
聚簇索引与非聚簇索引
聚簇索引与非聚簇索引
InnoDB里的聚簇索引和非聚簇索引的区别本质上是:
索引叶子节点里,存的到底是什么?
聚簇索引(Clustered Index)
在 InnoDB 里,主键索引就是聚簇索引。
核心特征只有一句话:
数据行本身,就存放在索引的叶子节点上。
换句话说:
B+ 树的叶子节点 = 完整数据行
可以把它想象成:
整张表就是一棵按主键排序的 B+ 树。
比如:
1 | CREATE TABLE user ( |
这张表的物理存储结构大概是:
1 | (B+树) |
特点
- 数据按照主键顺序物理存储
- 叶子节点存完整数据
- 一张表只能有一个聚簇索引(因为数据只能按一种顺序排)
查询过程
1 | SELECT * FROM user WHERE id = 10; |
直接查主键 B+ 树 → 到叶子节点 → 数据到手。
一次树查找结束。很干脆。
优点
- 查询速度快
- 对排序查找和范围查找优化
缺点
- 依赖有序的数据
- 更新代价大(插入、删除可能导致页分裂和数据移动)
非聚簇索引(Non-Clustered Index)
非聚簇索引是除了主键索引以外的所有索引。
核心特征:
叶子节点不存完整数据,只存:
- 索引列的值
- 主键值
注意,是主键值,不是物理地址。
例如:
1 | CREATE INDEX idx_name ON user(name); |
这棵树结构是:
1 | (name 的 B+树) |
它不存 age。
优点
更新代价比聚簇索引小,因为它不存完整数据,页分裂和数据移动的概率较低。
缺点
- 依赖有序的数据
- 可能会二次查询(回表)
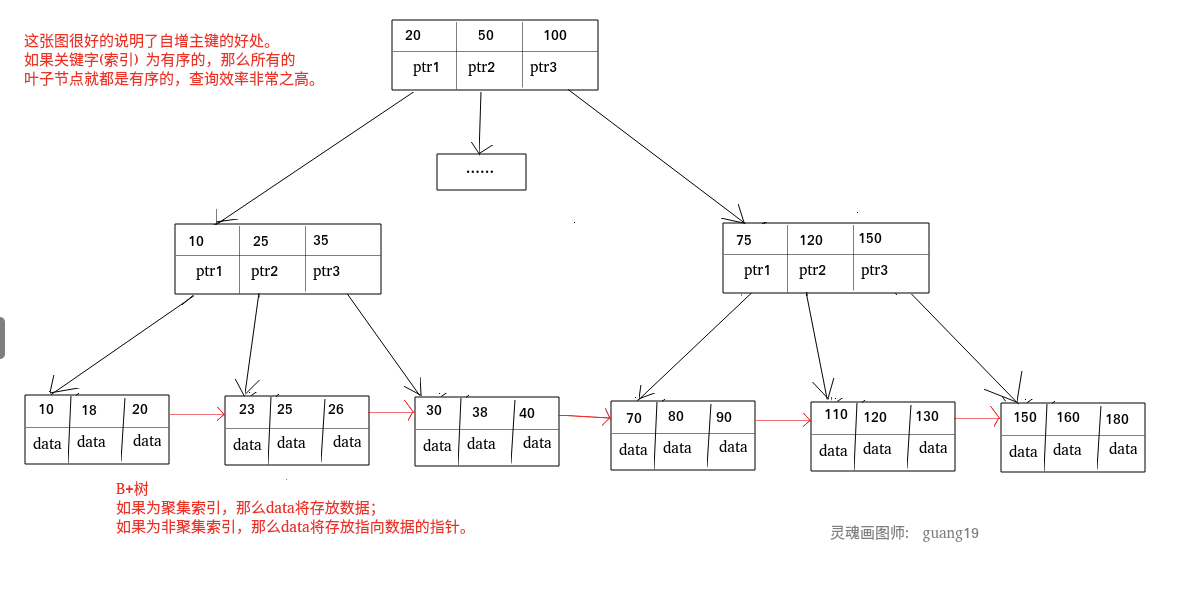
为什么要存主键?
因为 InnoDB 的数据都存在主键聚簇索引里。
所以:
- 先通过 name 索引找到 id
- 再用 id 去主键聚簇索引里查完整数据
这一步叫:
回表
举个查询例子:
1 | SELECT * FROM user WHERE name = 'Tom'; |
执行步骤:
- 查 name 索引
- 拿到 id
- 回主键索引查完整行
两棵树,两次查找。
覆盖索引是什么?
如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为覆盖索引(Covering Index)。
如果你写:
1 | SELECT name FROM user WHERE name = 'Tom'; |
因为 name 索引的叶子节点已经有 name 和 id
你只要 name,不需要 age
那就不需要回表。
这叫:
覆盖索引(Using index)
本质:查询字段全部存在于二级索引中。
面试标准回答结构
如果面试官问:
你可以这样答:
- InnoDB 的主键索引是聚簇索引,数据行存储在叶子节点中
- 非主键索引是非聚簇索引,叶子节点存索引列和主键
- 非聚簇索引查询如果需要完整数据会发生回表
- 一张表只能有一个聚簇索引
底层本质再挖深一点
为什么设计成这样?
如果二级索引直接存物理地址:
- 页分裂时地址会变
- 数据移动成本极高
- 维护复杂
而存主键值:
- 主键是逻辑稳定标识
- 结构解耦
- 插入和分裂更安全
这是数据库工程上的权衡,不是随便设计的。
顺带一个容易被问到的问题
如果没有定义主键怎么办?
InnoDB 会:
- 选一个唯一非空索引
- 如果没有
- 自动生成一个隐藏 6 字节 row_id
也就是说:
InnoDB 一定会有聚簇索引。



.JPG)






