
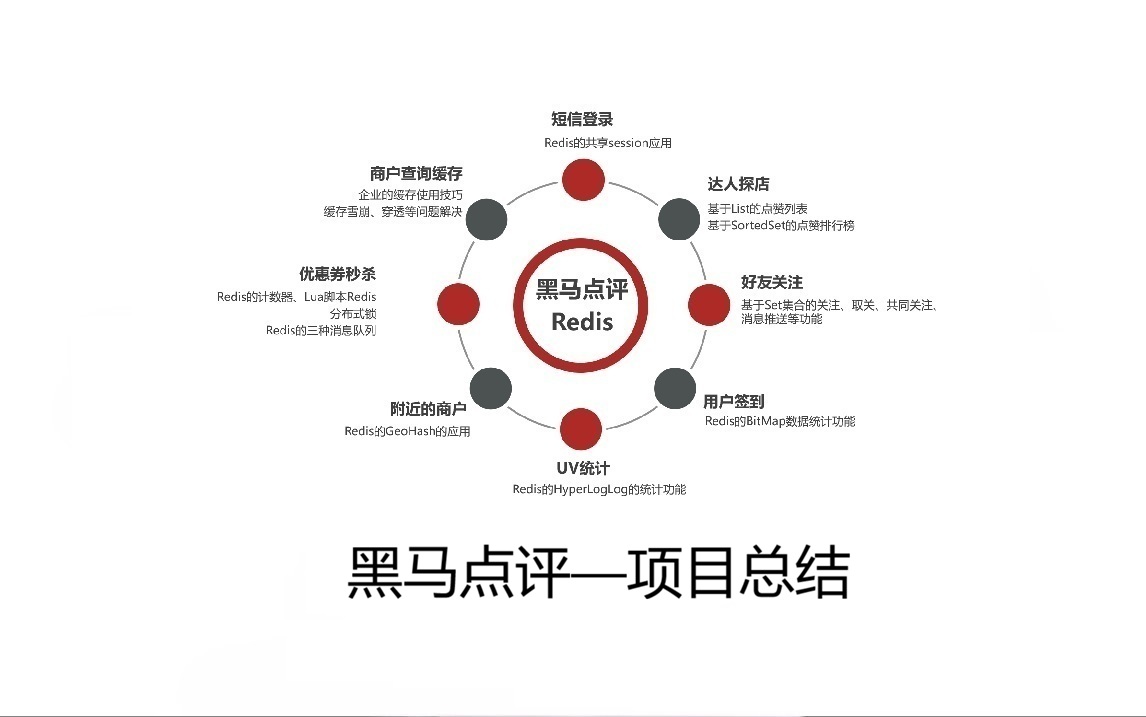
黑马点评项目总结
黑马点评项目关键技术总结

Milvus 向量数据库入门与实战
本文系统介绍 Milvus 向量数据库的核心概念、架构设计与 Java SDK 基础操作,并在最后一章提供一个完整的、可直接运行的 Spring Boot + Milvus RAG 智能问答项目。读完本文,你将掌握从零搭建企业级语义检索系统的全流程。

Go 内存管理与垃圾回收:从三色标记到 Green Tea GC
Go 内存管理与垃圾回收:从三色标记到 Green Tea GC
Go 的 GC 延迟从数百毫秒降到百微秒级,只用了不到五年。 这背后不是魔法,而是一系列精巧的工程权衡——三色标记、混合写屏障、并发清扫、以及刚刚在 Go 1.26 中默认启用的 Green Tea GC。
但你一定也遇到过这些场景:内存一直涨却不知道谁在吃、goroutine 数量只增不减、一个 3 元素的小切片把整个大数组拴住了…… Go 有 GC,但绝不等于不会内存泄漏。
在这篇文章里,我们不止聊"Go GC 做了什么",更要拆开它怎么做到的、什么情况下变量会从栈逃逸到堆、6 类常见内存泄漏怎么排查和修复——全是能直接用到生产环境的内容。
一、逃逸分析:决定变量归属的裁判
理解 Go 的内存管理,首先要搞清楚一个核心问题:你的变量到底分配在哪儿?
栈(Stack)
堆(Heap)
分配速度
极快(移动栈指针,单指令)
较慢(需查找空闲内存)
回收方式
函数返回即自动释放
依赖 GC 扫描回收
生命周期
跟随函数调用
跨函数 / 跨 Goroutine
GC 压力
零 ...

GMP 面试题
本文总结了 Go 语言 GMP 模型相关的面试题,涵盖了 GMP 模型的定义、调度器的工作原理、GMP 之间的关系以及调度器如何实现高效的 goroutine 调度等核心概念,帮助你系统复习 Go GMP 模型知识,为面试做好准备。

Interface 面试题
本文总结了 Go 语言 interface 相关的面试题,涵盖了 interface 的底层原理、iface 和 eface 的区别、类型转换和断言的区别以及 interface 的应用场景等核心概念,帮助你系统复习 Go interface 知识,为面试做好准备。

Context 面试题
本文总结了 Go 语言 Context 相关的面试题,涵盖了 Context 的定义、作用、Value 查找过程以及取消机制等核心概念,帮助你系统复习 Go Context 知识,为面试做好准备。

Sync 面试题
本文总结了 Go 语言 sync 包相关的面试题,涵盖了 mutex、原子操作、WaitGroup、sync.Map 等核心概念,帮助你系统复习 Go sync 包知识,为面试做好准备。

Channel 面试题
本文总结了 Go 语言 Channel 相关的面试题,涵盖了 CSP 模型、Channel 的底层实现原理、数据发送和接收的过程、关闭 Channel 的行为以及 select 语句的执行机制等核心概念,帮助你系统复习 Go Channel 知识,为面试做好准备。

Map 面试题
本文总结了 Go 语言 Map 相关的面试题,涵盖了 Map 的底层实现原理、遍历顺序、扩容机制以及并发安全性等核心概念,帮助你系统复习 Go Map 知识,为面试做好准备。

Slice 面试题
本文总结了 Go 语言切片(slice)相关的面试题,涵盖了切片的底层结构、扩容机制、切片截取对原切片的影响以及切片作为函数参数传递时的行为等核心概念,帮助你系统复习 Go 切片知识,为面试做好准备。