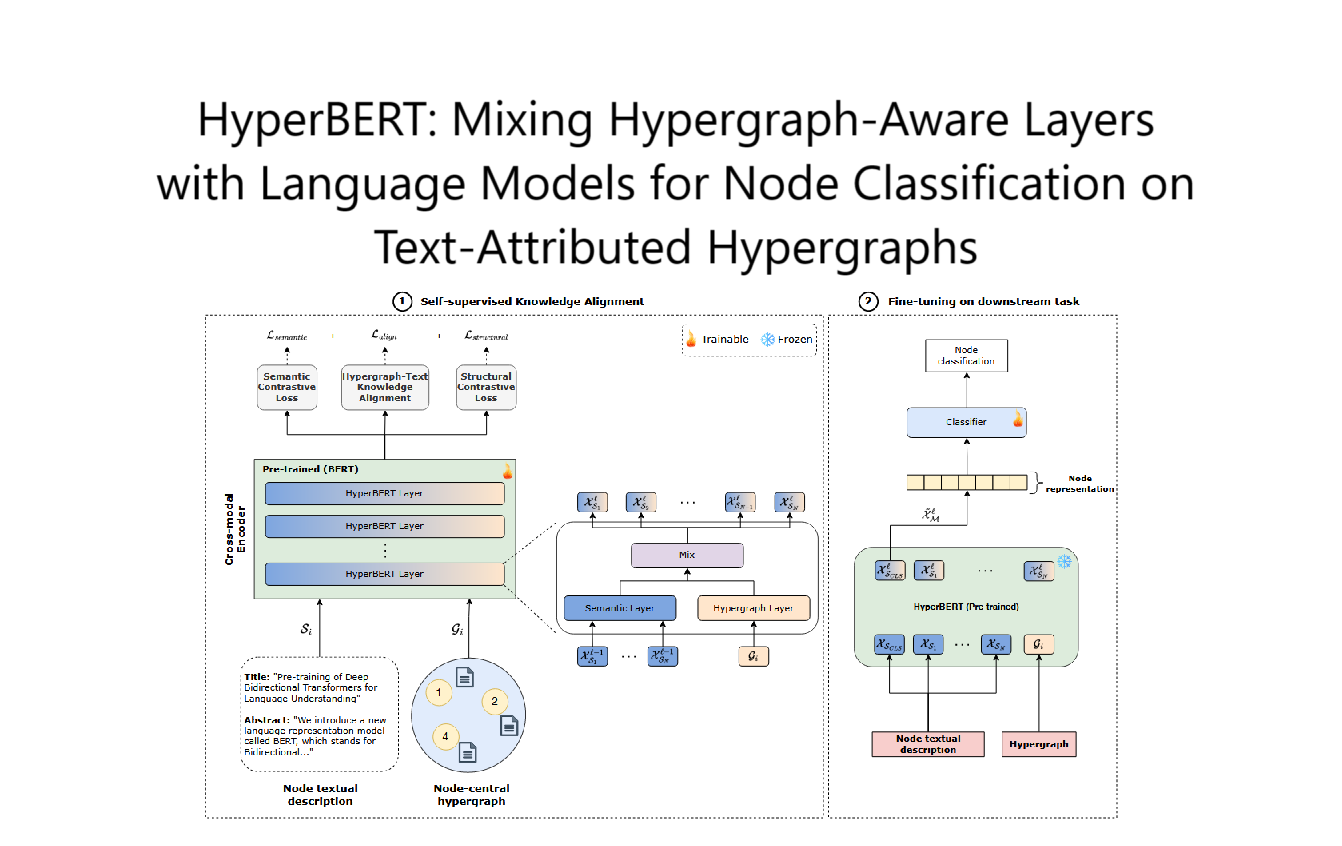
MSE-Adapter:A Lightweight Plugin Endowing LLMs with the Capability to Perform Multimodal Sentiment Analysis and Emotion Recognition
MSE-Adapter:A Lightweight Plugin Endowing LLMs with the Capability to Perform Multimodal Sentiment Analysis and Emotion Recognition
一、论文总结
这篇论文主要提出了一种名为 MSE-Adapter 的轻量级插件,用于赋予大型语言模型(LLMs)进行多模态情感分析(MSA)和对话情绪识别(ERC)的能力。以下是论文的核心内容总结:
论文pipeline:
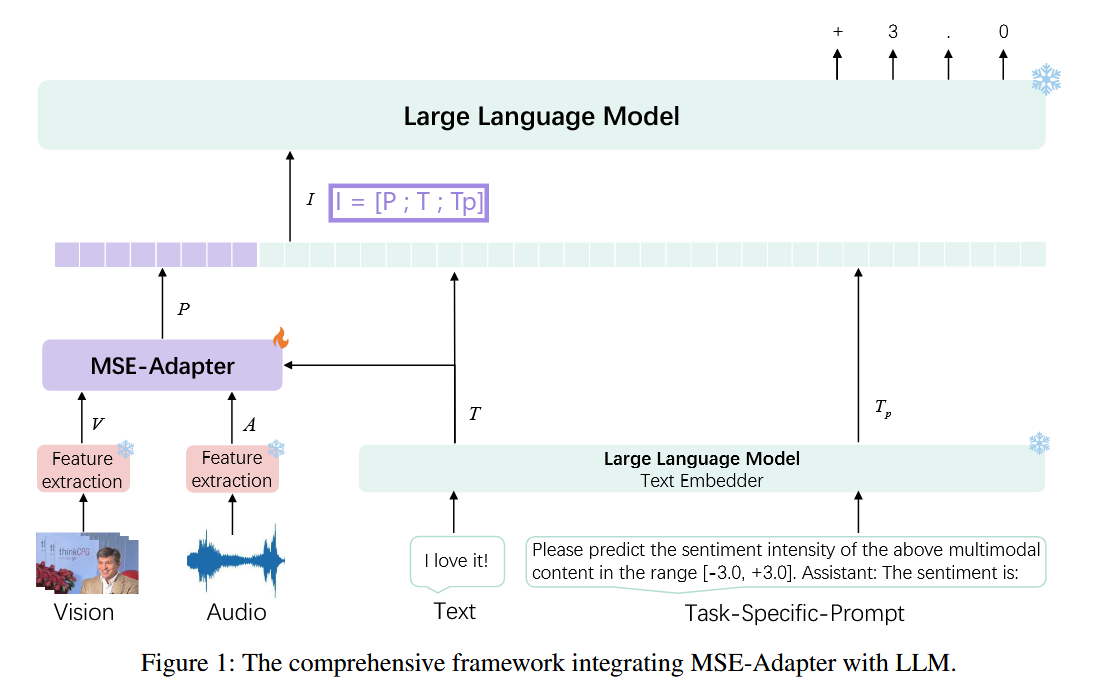
1.1 背景与问题
当前基于预训练语言模型的多模态情感分析方法面临两大问题:
- 破坏通用能力:为特定任务(MSA/ERC)微调后,模型很难再用于其他任务;
- 计算开销大:例如 UniSA 的预训练需 3 天 8 张 V100 显卡。
1.2 方法概述:MSE-Adapter
MSE-Adapter 是一个“即插即用”的轻量插件,具备以下特征:
- 冻结 LLM 主体:只训练少量参数(约 2.6M–2.8M),保留 LLM 的原始能力;
- 支持多模态输入:文本、语音、视觉;
- 输出情感标签:通过 LLM 的自回归生成机制生成情感或情绪类别。
模块结构
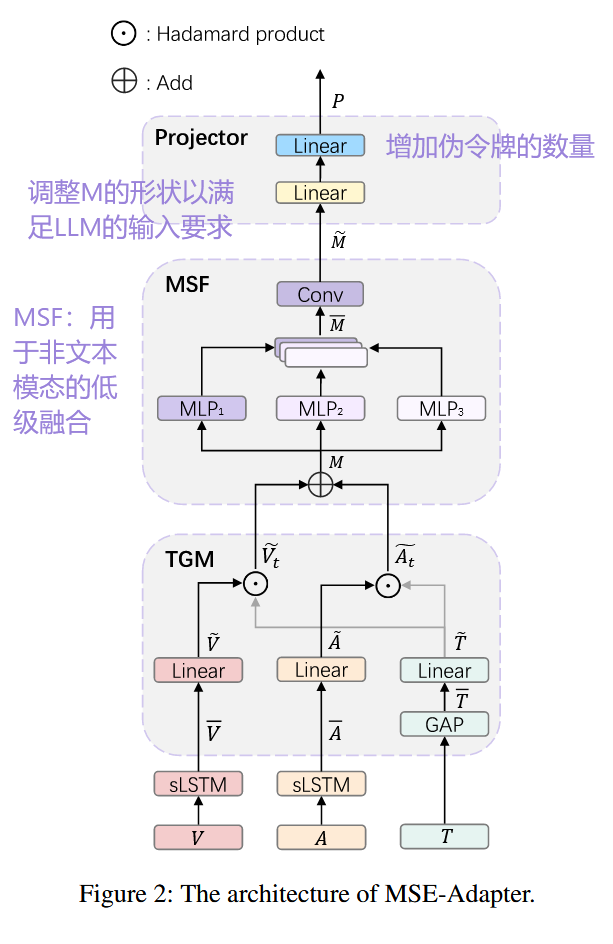
-
Text-Guide-Mixer(TGM):
- 使用 Hadamard 积实现文本与非文本模态(视觉、语音)的特征对齐;
- 提高非文本信息被理解的可能性。
-
Multi-Scale Fusion(MSF):
- 对非文本模态先进行低层融合(Early Fusion),减轻 LLM 对多模态融合的负担;
- 使用不同维度的 MLP 和卷积层实现信息整合。
-
Projector:
- 将融合后的信息投影为 LLM 可理解的“伪 token”,供 LLM 后续生成情感标签。
1.3 实验设置与结果
-
数据集:
- 英文:MOSEI(MSA)、MELD(ERC)
- 中文:SIMS-V2(MSA)、CHERMA(ERC)
-
主干模型:Qwen-1.8B、ChatGLM3-6B、LLaMA2-7B
-
结果:
- MSE-Adapter 在大多数指标上优于现有方法,尤其在 ChatGLM3-6B 上表现最佳;
- 即便是在中文任务上表现稍弱的 LLaMA2-7B,也优于许多基线模型;
- 相比 MAG 和 CHFN 等 BERT-based 方法,参数更少(仅 ~2.6M),但性能更优。
1.4 消融实验与分析
- 移除 TGM 或 MSF 会显著降低性能,验证两者的重要性;
- 移除文本模态对性能影响最大,说明语言在情绪识别中仍然是最关键的信息源;
- 视觉和语音模态也有明显贡献,说明非文本信息对多模态情绪理解是必要的补充。
1.5 结论
MSE-Adapter 是一个有效且高效的插件式方案,它在保留 LLM 原始能力的前提下,大幅提升其处理多模态情绪分析任务的能力,尤其适用于资源有限的部署场景(如移动设备)。
论文的 Method(方法) 部分是整篇文章的核心,详细介绍了作者提出的 MSE-Adapter 结构,如何以轻量的方式赋予大型语言模型(LLMs)处理多模态情感分析(MSA)与情绪识别(ERC)任务的能力。
二、整体架构:MSE-Adapter 概览
MSE-Adapter 作为一个“即插即用”的插件,位于多模态输入与冻结的 LLM 主体之间,核心结构如下三部分组成:
模块结构总览:
1 | [多模态输入: 文本 + 视觉 + 音频] |
2.1 Text-Guide-Mixer (TGM):文本引导的模态对齐
目的:通过文本引导,增强非文本模态(视觉、音频)的特征对齐效果,使其更容易被 LLM 理解。
实现方式:
- 使用 Hadamard 乘积(逐元素乘法):
- $ x_m $:视觉或语音特征
- $ x_t $:文本特征
- $ W_m $:可学习参数
- $ LN $:LayerNorm
这种方式能够保留模态间的结构信息,同时强化文本在对齐过程中的引导作用。
2.2 Multi-Scale Fusion (MSF):多尺度融合非文本模态
目的:通过多个尺度的表示融合不同模态信息(如视觉和音频),提升 LLM 的上下文理解能力。
模块结构:
- 首先使用多个 MLP 进行线性变换;
- 然后串联多个 卷积层(Conv1D) 处理不同尺度的特征;
- 最终输出一个统一表示,增强不同模态之间的信息交互。
核心思想:
- Early Fusion:先在 Adapter 中融合视觉+音频,减轻 LLM 本身的负担;
- 多尺度处理:帮助捕捉不同粒度的模态信息,有利于对细微情绪线索的捕捉。
2.3 Projector:伪 token 映射器
目的:将融合后的特征序列映射成伪 token(伪词嵌入),插入到文本序列中,作为输入喂给 LLM。
做法:
- 使用一层线性层:
- 生成的伪 token 会被拼接到原始文本 token 的前部或中部,作为额外输入;
- LLM 通过自回归方式生成最终的情感类别标签。
2.4 训练策略与任务格式
- 输入格式设计为 Prompt Completion:
1
2Input: “User: [TEXT] [AUDIO] [VIDEO]”
Target: “System: [Emotion Label]” - 采用 交叉熵损失进行训练;
- 所有实验中 LLM 全部冻结,只训练 Adapter 部分(约 2.6M 参数)。
2.5 优点总结:
| 特性 | 描述 |
|---|---|
| 轻量化 | 只训练 Adapter(百万级参数),LLM 冻结 |
| 模块化 | 插件式设计,兼容任何 LLM |
| 多模态适配 | 有效融合文本、视觉、语音 |
| 保留原始能力 | 不影响 LLM 的通用性,可扩展到其他任务 |
三、MSE-Adapter与prefix-tuning的对比
3.1 类比说明:MSE-Adapter vs. Prefix-Tuning
| 特性 | Prefix-Tuning | MSE-Adapter |
|---|---|---|
| 🌱 基本思想 | 插入一串“可训练 prefix 向量”到 LLM 的输入中,引导其完成特定任务 | 把视觉/音频等非文本模态转成“伪 token”(pseudo tokens)插入到文本前面,引导 LLM 做多模态任务 |
| 📦 输入内容 | 全是纯文本 + 可学习前缀 | 文本 + 非文本模态(图像、音频等)转换成伪 token 后一起输入 |
| 🧠 LLM 权重 | 冻结 | 冻结 |
| 🔧 可训练部分 | 仅 prefix 向量(几百个 token) | 仅 Adapter(将模态特征 → token),参数量约为几百万 |
| 🧩 插入方式 | 直接在 prompt 前拼接 prefix(如 [prefix] + prompt) |
拼接生成的伪 token(如 [P_audio, P_vision] + text + prompt) |
| 🎯 应用领域 | 文本分类、生成、QA 等 | 多模态情感分析、图文问答、视频理解等 |
| 💡 本质 | 学习“上下文引导提示向量” | 学习“多模态→语言伪 token 映射器” |
3.2 相似之处
- 都是 参数高效的微调(parameter-efficient tuning) 方法;
- 都是 通过添加额外“提示”引导 LLM 完成特定任务;
- 都 冻结 LLM 主体,降低训练成本、保留通用性;
- 都适合任务迁移、模块化部署;
3.3 不同点 & MSE-Adapter 的扩展性更强
| 不同点 | 差异说明 |
|---|---|
| 模态支持 | Prefix-tuning 主要针对纯文本任务;MSE-Adapter 支持 跨模态输入(图像、音频、时间序列等); |
| 模块结构 | Prefix-tuning 是直接优化一串向量;MSE-Adapter 是一个小网络,负责融合、变换不同模态后生成伪 token; |
| 表达能力 | MSE-Adapter 可集成模态对齐(如 TGM)、多尺度融合(如 MSF)等复杂操作,表达能力更强; |
| 通用性 | MSE-Adapter 通过不同“插件”支持多种多模态任务;Prefix-tuning 更偏文本任务的轻调优; |
3.4 总结
Prefix-tuning 像是在提示:“我现在是个 xxx 任务,请你用这个方式去思考”;
MSE-Adapter 则像是在**“把图片/语音翻译成人话”,再请 LLM 去理解**。
四、MSF模块
在 MSF 中,为什么作者不直接用一个 MLP 处理融合特征 $ M $,而是用了 三个具有不同隐藏维度的 MLP,分别生成三个输出 $ m_1, m_2, m_3 $?
这是为了引入 多尺度特征处理(multi-scale processing),增强模型对不同粒度情感线索的理解能力。
4.1 三个 MLP 有什么区别?
这三个 MLP 的结构相同,但 隐藏层的维度不同(k ∈ {8, 16, 32}),如下:
其中:
- $ W^i_1 \in \mathbb{R}^{h/k \times h} $:压缩维度
- $ W^i_2 \in \mathbb{R}^{h \times h/k} $:再恢复维度
- $ \sigma $:GELU 激活函数
- $ i \in {1, 2, 3} $
三组 MLP 的隐藏层分别压缩到 1/8、1/16、1/32 的维度后再展开,就像从“粗 → 细”多个层次提取特征。
4.2 为什么要这样设计?
4.2.1 多尺度捕捉不同粒度信息
现实中,情感线索有“大粒度”和“小粒度”:
- 大粒度:说话人整体语调、音量、表情风格
- 小粒度:微笑时嘴角细微动作、音调起伏
多个 MLP 不同压缩尺度相当于:
从大视角、粗视角、中视角不同角度去理解情绪。
这类似于计算机视觉中的 多尺度感受野设计(如 FPN、ResNet block 中的不同 kernel),有助于识别不同层次的特征。
4.2.2 避免信息瓶颈
如果只用一个固定维度的 MLP,可能:
- 太大 → 计算开销大
- 太小 → 信息压缩过度,丢失细节
多个尺度并行处理 + 后融合,可以有效地取长补短、提升表达能力。
4.2.3 提升模型鲁棒性与泛化能力
在不同语言、模态和任务中,不同尺度的情感特征重要性是不同的。
- 有时语音节奏是关键
- 有时面部细节更重要
使用多个尺度同时建模,可增强适应性和鲁棒性。
4.3 最后一步:融合这三种尺度信息
论文中将三个 $ m_i $ 拼接成一个矩阵 $ M = [m_1; m_2; m_3] \in \mathbb{R}^{h \times 3} $,再用 1×1 卷积压缩维度,得到最终表示:
这相当于在 token 维度上做一次自适应融合 —— 让模型学会从不同尺度中选出最有用的特征。
4.4 总结一句话
三个 MLP 是在不同尺度上对融合特征进行建模,增强模型对多粒度、多模态情绪信息的理解和表达能力,是 MSF 的“多视角处理核心”。
五、Projector模块
5.1 Projector 的作用是什么?
简洁总结:
Projector 的作用是将多模态融合后的特征表示,映射成与 LLM 输入兼容的 “伪 token” 嵌入序列(pseudo tokens),从而让 LLM 可以“看懂”视觉和音频模态信息。
5.2 Projector 具体做了什么?
在前面两个模块(TGM + MSF)完成对视觉/音频特征的融合之后,会得到一个统一的多模态表示向量:
这是一个较短、浓缩的“信息摘要”,但还不是 LLM 可以直接吃进去的 token。
于是,Projector 模块做了两个关键步骤:
步骤 1:调整维度(线性映射)
先用一个线性变换将维度转到与 LLM token embedding 一致的维度:
其中:
- $ W_3 \in \mathbb{R}^{d_t \times h} $
- $ d_t $ 是 LLM 的 token 嵌入维度(比如 768)
步骤 2:扩展为多个“伪 token”
接下来,为了生成多个伪 token,使用另一个线性层将单个向量扩展为多个 token(数量为 $ n $):
其中:
- $ W_4 \in \mathbb{R}^{n \times 1} $,控制输出 token 的数量
- 最终输出 $ n $ 个伪 token,每个维度是 $ d_t $,可以直接拼接到文本 token 中
5.3 Projector 的核心价值:
| 功能 | 解释 |
|---|---|
| 🎨 统一模态维度 | 把非语言特征统一成 LLM token 能理解的表示形式 |
| 🔧 可控 token 数量 | 用户/任务可配置生成多少个伪 token |
| 🔄 可训练 | 具有可学习参数,能适应不同模态、任务、语言模型 |
| 📦 保持模块解耦 | 不需要改动 LLM 内部结构,保持整个系统松耦合 |
5.4 对应论文中的公式:
- $ W_3 $:从融合特征 → token 向量
- $ W_4 $:将 token 向量扩展成多个 token
- $ P $:最终生成的伪 token 序列(可输入 LLM)
5.5 总结一句话:
Projector 是连接多模态世界与语言模型世界的“最后一跳桥梁” —— 它把融合后的视觉/语音信息,转成一串“LLM能读懂的token”。
六、pseudo tokens(伪token)
这个问题问得非常深入!论文中之所以将多模态特征 扩展为多个“伪 token”(pseudo tokens),而不是只生成一个,是出于以下几个 非常关键的考虑
多个伪 token 的作用与优势:
6.1 提供更丰富的信息容量
单个 token 能携带的信息是有限的。如果你把整个图像或音频都压缩成一个向量,就像让人用一个词总结一张图 —— 会丢失很多细节。
多个伪 token 就相当于用“多个词”描述图像或声音的不同方面(如颜色、语气、动作、情绪等)。
📌 举例:
- 伪 token 1:人脸信息
- 伪 token 2:音调特征
- 伪 token 3:视觉情绪线索
- 伪 token 4:上下文场景提示
6.2 方便 LLM 的 Transformer 编码器做“注意力交互”
LLM 是基于 Transformer 的,它依赖 token 之间的注意力(attention)机制来进行推理。如果只有一个 token,它就无法和其它 token 做交互(注意力矩阵退化为一维)。
而多个伪 token 之间 可以互相计算注意力,再与文本 token 交互,这大大增强了:
- 多模态信息之间的整合能力
- 与语言上下文的耦合程度
想象:伪 token 像几个“间谍”,分别打探了不同模态的情报,然后一起与 LLM 的“智囊团”(文本 token)商量对策。
6.3 提高模型的可扩展性和灵活性
每个任务或模态的复杂度不同,所需的伪 token 数量也不同。支持多个 token 可以让系统具备:
- 任务自适应能力:图像/语音越复杂 → 生成更多伪 token
- 统一接口设计:不同任务只是 token 数量不同,不影响整体框架
6.4 实验验证:多个 token 比单 token 性能更好
虽然论文没有单独对这个点做 ablation,但根据大量多模态工作(如 Flamingo, Frozen, BLIP-2, MiniGPT-4)的经验,单个 token 会严重压缩信息,多个 token 可以显著提升性能。
6.5 总结一句话
将多模态特征扩展为多个伪 token,是为了最大化信息表达能力、提高注意力交互效率,并提升 LLM 对复杂感知任务的适应能力。