LLM as GNN:Graph Vocabulary Learning for Text-Attributed Graph Foundation Models
LLM as GNN:Graph Vocabulary Learning for Text-Attributed Graph Foundation Models
一、论文总结
1.1 研究背景与问题
1.1.1Text-Attributed Graphs(TAGs)
- 指图中每个节点都附带有自然语言文本描述的图,如引文网络、社交网络、生物分子图等。
- 当前图-文本结合的研究主要存在以下问题:
- 架构松散,采用“两阶段”方法分别处理图和文本,导致融合效果差。
- 节点被当作 OOV tokens,造成词表爆炸(token explosion)、语义不兼容、跨图迁移困难。
1.2 核心贡献:PromptGFM 框架
PromptGFM 由两个关键模块组成:
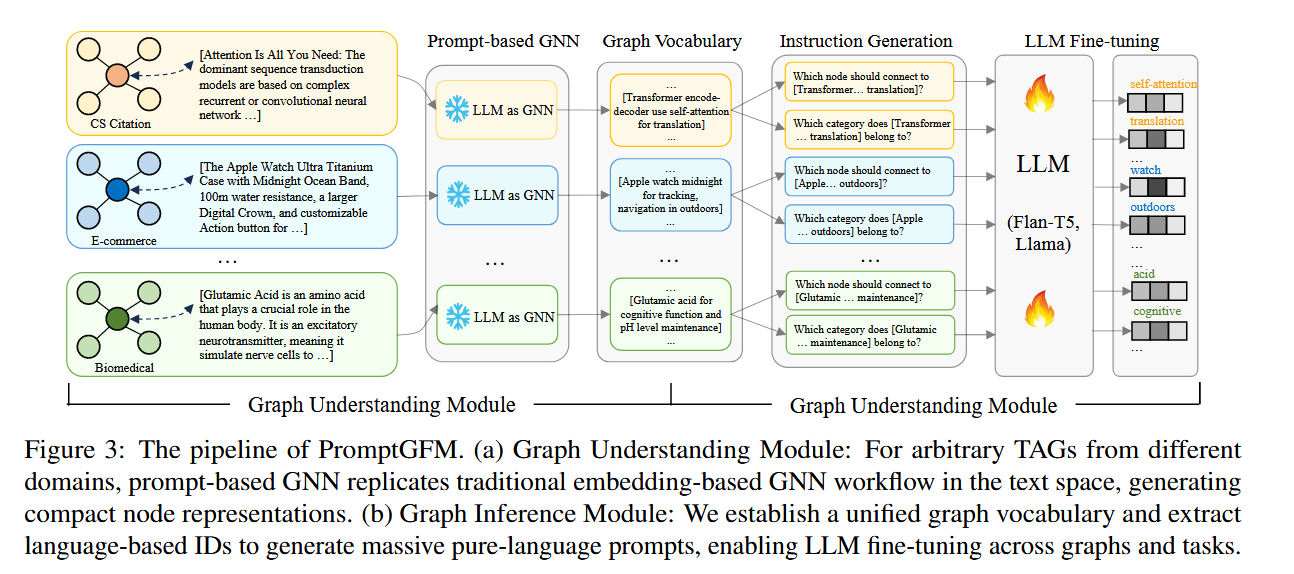
1.2.1 Graph Understanding Module
利用 LLM 模拟 GNN 的消息传递机制,纯粹在文本空间进行图表示学习。
-
怎么做?
- 使用 prompt 引导 LLM 对节点的邻居信息进行聚合与更新。
- 迭代多轮生成新的文本表示(如结构化摘要),等价于 GNN 的多层传播。
- 采用对比学习目标,使得相邻节点语义更近,远节点更远。
-
效果:
- 用 LLM 实现类 GNN 的结构感知机制。
- 保留结构与语义,避免传统嵌入方法的模态错位问题。
1.2.2 Graph Inference Module
构建统一的语言化图词表(Graph Vocabulary),实现图节点的泛化与可迁移表示。
-
怎么做?
- 将每个节点表示为一串自然语言 token(即“语言化 ID”),代替传统 ID 或 OOV token。
- 支持跨图、跨任务复用,生成统一的纯文本 prompt,用于 LLM 微调。
- 利用多指令微调(multi-instruction fine-tuning)+ 受限解码(constrained decoding)提升鲁棒性。
-
优势:
- 可读性强、易解释。
- 支持跨领域、跨任务迁移,避免词表爆炸。
1.3 实验结果
1.3.1 任务涵盖:
- 节点分类
- 链路预测
- 跨图迁移(intra-domain 和 inter-domain)
- 跨任务迁移(link prediction ➝ node classification)
1.3.2 表现亮点:
- 在 7 个图数据集上,PromptGFM 在节点分类和链路预测任务中,全面超过 GCN、GAT、BERT、GraphPrompter、LLaGA 等现有方法。
- 在跨图和跨任务迁移上表现出显著优势,展示其泛化能力。
1.4 消融分析与探索
- 去除 GNN 模拟模块或微调模块会显著降低性能,说明两个模块缺一不可。
- 尝试邻居节点打乱、token 顺序打乱,结果稳健,说明模型具备一定的结构感知能力。
- 引入受限解码(prefix tree search)有效降低 LLM 生成的幻觉现象。
1.5 总结亮点
| 模块 | 创新点 | 贡献 |
|---|---|---|
| Graph Understanding | 用 LLM 模拟 GNN 消息传递过程 | 实现图结构建模 + 文本语义对齐 |
| Graph Inference | 构建语言化图词表 | 支持可解释、可扩展、可迁移的图推理 |
| 整体框架 | 全流程文本空间操作,无嵌入空间对齐 | 避免 OOV,提升跨图泛化能力 |
1.6 局限性与未来方向
- 跨域知识迁移仍存在挑战:引入多领域数据会引发知识冲突。
- 目前仅适用于 TAGs:对不含文本属性的纯结构图无效。
- 没有统一处理跨图语义对齐的问题,未来可考虑显式的图间语义映射。
1.7 总结一句话
PromptGFM 是首个让 LLM 真正“变身”为 GNN 的工作,在自然语言空间中完成图建模、推理和微调,为构建通用的图基础模型(GFM)开辟了新方向。
二、Methodology 关键点
论文 《LLM as GNN: Graph Vocabulary Learning for Text-Attributed Graph Foundation Models》 中 Methodology(方法)部分包括两个核心模块:
PromptGFM 的方法部分由两个主要组件组成:
Graph Understanding Module
Graph Inference Module
它们分别负责:
- 理解:用 LLM 模拟 GNN 的消息传递(在文本空间中进行图学习)
- 推理:构建语言化的图词汇表,并用纯文本 prompt 进行多任务微调
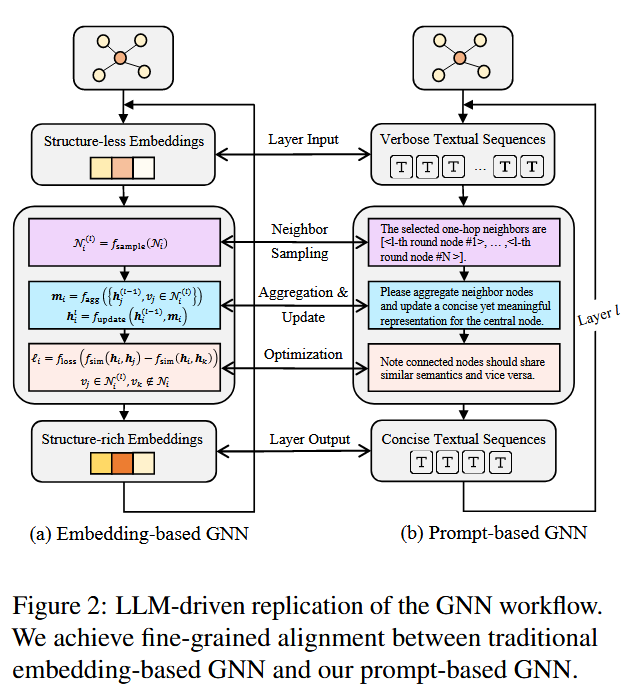
2.1️ Graph Understanding Module:用 LLM 模拟 GNN(即“LLM as GNN”)
2.1.1 目标:
实现传统 GNN 的功能 —— 邻居采样、信息聚合、更新嵌入 —— 但 完全在文本空间中进行,不使用结构化图嵌入。
2.1.2 核心思想:Prompt-based GNN
模拟传统 GNN 三大步骤:
| 步骤 | GNN 中的做法 | PromptGFM 中的模拟方式 |
|---|---|---|
| 邻居采样 | 选取一阶邻居节点 | 使用 prompt 对邻居节点进行文本采样 |
| 信息聚合 | 聚合邻居嵌入 | 用 prompt 引导 LLM 合并邻居文本信息 |
| 节点更新 | 更新中心节点表示 | 生成新的节点文本描述(表示) |
2.1.3 具体步骤:
2.1.3.1 初始化节点表示:
- 用每个节点的原始文本描述作为初始表示(类比 GNN 的
lookup embedding)
2.1.3.2 邻居采样:
- 限制最多采样 20 个邻居(为避免 prompt 长度过长)
- 文本形式表示这些邻居,例如:
“The selected one-hop neighbors of node X are […].”
2.1.3.3 信息聚合 + 更新:
-
设计自然语言 prompt,引导 LLM进行如下操作:
“Please aggregate neighbor nodes and update a concise yet meaningful representation for the central node.”
-
输出结果是一个新的精炼文本表示,包含结构 + 语义信息。
2.1.3.4 多轮消息传递(多层 GNN):
- 多轮调用 LLM,上一轮的输出作为下一轮输入,模拟 GNN 的多层传播结构(high-order 信息传递)。
2.1.2 优化目标:对比学习(Contrastive Loss)
PromptGFM 采用对比学习损失函数来强化语义聚合效果:
- $ h_i $:中心节点
- $ h_j $:邻居节点(正样本)
- $ h_k $:非邻居节点(负样本)
这里的表示 $ h $ 是通过多轮 prompt 得到的文本 embedding。
2.1.3 小结:
这一模块的创新在于:完全在文本空间中复现了 GNN 的消息传递过程,避免了传统方法中图结构与语言嵌入的不兼容问题。
2.2️ Graph Inference Module:构建语言化图词表,支持跨任务/图推理
2.2.1 目标:
将每个图节点转化为“语言化 ID” —— 即由若干自然语言 token 组成的可读表示,用于统一表示不同图中不同任务的节点。
2.2.2 核心概念:Graph Vocabulary(图词汇表)
2.2.2.1 定义:
图词汇表是一个语言化表示集合,其中每个图节点 $v_i $ 被映射成 token 序列 $ T_i = (t_i^1, t_i^2, …, t_i^m) $。
这相当于给每个节点一个“文本名字”,而非 ID 或向量。
2.2.2.2 好处:
| 维度 | 效果 |
|---|---|
| 表达力(Expressiveness) | 能表示语义与结构信息 |
| 迁移性(Transferability) | 所有图共享同一个词表 |
| 可扩展性(Scalability) | 新节点也可以构造 token 表示,不会OOV |
2.2.3 如何应用语言化 ID:
使用 Prompt Templates 构造任务指令:
以链接预测任务为例:
1 | Given the node <Transformer...translation>, among |
- 所有节点使用语言 ID 替换
- 完整任务变成自然语言形式,供 LLM 处理
2.2.4 LLM 微调:Instruction-based Fine-tuning
将上述 prompt + answer 转为 text-to-text 格式:
- 模型输入:自然语言 prompt
- 模型输出:预测答案(目标节点、分类标签等)
使用 T5、Flan-T5 或 LLaMA 进行微调,跨图跨任务泛化。
2.2.5 防止幻觉(Hallucination):Prefix Tree 解码
- 将所有候选节点的语言 ID 构建成一棵前缀树(prefix tree)
- 在生成时限制输出路径必须在树中
- 确保输出是图中真实节点,避免生成虚假 ID
2.3 Methodology 总结图解
1 | [Graph Structure + Text Attributes] |
2.4 创新点总结
| 模块 | 创新之处 |
|---|---|
| Graph Understanding | 用 LLM 完整模拟 GNN 消息传递机制(text-space GNN) |
| Graph Vocabulary | 构建语言 ID 替代图 ID,解决 OOV、语义错位问题 |
| Inference Module | 用 prompt template 实现跨图跨任务迁移 |
| 解码策略 | 使用前缀树约束生成,避免 hallucination |
三、Graph Vocabulary介绍
Graph Vocabulary 是一种“语言化”的节点表示方式:将每个图节点用一组自然语言 token(而非 ID 或嵌入向量)表示,使图节点可以作为 LLM 输入的“词”,参与统一建模与推理。
3.1 为什么要构建 Graph Vocabulary?
3.1.1 传统方法的问题:
- 用图结构中的节点 ID(如“node_32”)当 token,会被语言模型当作 OOV 处理。
- 图节点嵌入与语言嵌入不在同一语义空间,导致语义错位(semantic misalignment)。
- 节点 ID 不可解释、不可泛化,导致模型无法迁移到新图或新任务。
3.1.2 Graph Vocabulary 带来的好处:
| 目标 | 实现方式 |
|---|---|
| 语义一致性 | 用语言 token 表示节点,与 LLM 内部语义对齐 |
| 跨图泛化 | 所有图节点统一使用可共享的 token 表达 |
| 迁移能力 | 新节点也可以用已有 token 组合表达,避免词表爆炸 |
| 可解释性 | 每个节点表示为可读文本,方便调试、分析 |
3.2 构建 Graph Vocabulary 的流程
3.2.1 获取初始节点表示(Initial Representation)
论文中使用 Graph Understanding Module,通过 prompt + LLM 多轮生成,得到每个节点 的结构感知语义表示 ,即:
1 | T_i = [t_i^1, t_i^2, ..., t_i^m] |
每个 是一个自然语言 token,可以是词、短语、子词(取决于 tokenizer)。
这些表示是:
- 结构感知的(融合邻居信息)
- 语义丰富的(来自 LLM 生成)
- 语言模型可直接处理的
3.2.2 语言 ID 归一化(Tokenization + Vocabulary 构建)
- 将所有节点的表示文本 分词,得到 token 序列。
- 取所有 token 的集合,作为图词表
Graph Vocabulary:
- 这些 token 与 LLM 的原始词表部分重叠,部分新增。
注意:这不是传统的“embedding lookup”,而是将节点语义直接变成 LLM 的输入文本。
3.2.3 任务输入中的节点替换(Tokenization 应用)
当执行 downstream 任务(如链路预测、节点分类)时:
传统方式:
1 | Node ID: node_42 |
Graph Vocabulary 方式:
1 | Node ID → “transformer-based model for translation” |
然后构造自然语言 prompt,例如:
1 | Given the node "transformer-based model for translation", |
这样,每个节点都变成可读的、语义可解释的文本输入。
3.2.4 词表泛化能力(跨图/新节点)
对于训练集中未见过的节点,如何获得对应的语言表示?
有两种方式:
- 再调用 Graph Understanding Module,生成新节点的语言表示
- 组合已有 token 构建新节点的描述(如“node with property A and B”)
这就实现了 zero-shot 跨图推理。
3.2.5 生成时防止幻觉(Constrained Decoding)
由于语言模型可能会生成不存在的节点表示,论文引入了 Prefix Tree(前缀树)限制生成输出:
- 把所有候选节点的语言 ID 建成一棵 trie 树
- 生成过程中必须遵循这棵树的路径
- 避免输出无效、虚构的节点 ID
3.2.6 示例回顾
如果原始图中有两个节点:
| Node | 属性文本 |
|---|---|
| A | “Transformer model for translation” |
| B | “Graph convolutional network for connection” |
它们被转为:
1 | T_A = ["transformer", "model", "for", "translation"] |
Graph Vocabulary 变为:
1 | V_graph = {"transformer", "model", "for", "translation", |
推理时:
1 | Which node should "transformer model for translation" connect to? |
3.3 总结一句话
Graph Vocabulary 是将图中每个节点用自然语言 token 表达出来的机制,使得图节点可以作为“可读词汇”参与语言模型推理,具有可解释性、可迁移性、统一性。
四、Prefix Tree Search(前缀树搜索)
它是为了解决 LLM 在推理时“生成幻觉(hallucination)”的问题。
4.1 什么问题需要 Prefix Tree Search?
在 Graph Vocabulary 方法中,节点是用自然语言 token来表示的。例如:
1 | "Transformer model for translation" |
当 LLM 需要预测某个节点作为答案(比如链路预测中选目标节点),它的输出是一串 token。
问题:
LLM 可能会生成不属于图中任何一个节点的词组,也就是**“不存在的语言化 ID”**。
比如模型生成了:
1 | "Graph reasoning attention encoder" |
这不在任何实际图节点中 ➜ 就是幻觉(hallucination)。
4.2 Prefix Tree Search 是如何解决的?
目标:
让 LLM 的输出只能是候选节点中的合法语言化 ID。
4.3 什么是 Prefix Tree(前缀树)?
前缀树(Trie Tree)是一种高效的数据结构,用于存储和查找字符串集合中共享前缀的部分。
比如你有以下候选节点文本:
1 | "Graph attention network" |
它们可以建成这样的前缀树:
1 | [Graph] |
4.4 Prefix Tree Search 的做法:
-
构建前缀树:将所有候选节点的语言化 ID(如 Graph Vocabulary 中的表示)构建为 prefix tree。
-
受限生成(constrained decoding):
- 在生成 token 的过程中,每一步只允许模型选择 符合前缀路径的 token。
- 如果当前生成路径不是任何节点表示的前缀,就禁止模型继续往下生成这条路径。
-
终止判断:
- 当模型生成了一条完整路径,且它在前缀树中是一个完整的节点表示时,允许输出。
- 否则继续搜索或回溯。
4.5 举个例子
候选语言化节点:
1 | ["graph attention network", |
模型生成到一半时:
1 | "graph con" |
prefix tree 检查到它符合 "graph convolutional" 的路径 ➜ ✅ 继续
如果模型想输出:
1 | "graph residual connection" |
前缀 "graph residual" 不在任何合法路径中 ➜ ❌ 被剪枝掉,不允许生成。
4.6 好处
| 问题 | Prefix Tree Search 的解决方式 |
|---|---|
| 幻觉(生成不存在的节点) | 只允许生成合法节点表示路径 |
| 多样性控制困难 | 精确限制候选集合 |
| 可解释性差 | 输出始终是候选节点之一,可追溯来源 |
4.7 在论文中的应用场景:
- Link prediction
- Node classification
- Question answering
在这些任务中,输出的节点是来自图的节点集合,因此使用 prefix tree 可以有效控制生成范围。
4.8 总结一句话:
Prefix Tree Search 是一种对 LLM 的输出进行“合法性控制”的方法,它构建一个包含所有合法候选的前缀树,在生成过程中仅允许沿着这棵树的路径生成,从而避免生成幻觉、提升鲁棒性。
五、Vocabulary相对于节点ID当token更有助于泛化
你说得对,从编码角度来看,节点 ID 是“统一的标识符”,好像挺通用的。但是实际上,在 LLM 或多任务学习中,节点 ID 当 token 往往是很难泛化的,而 Graph Vocabulary 更有助于泛化。我们来详细对比一下为什么。
5.1 首先,什么是“泛化”?
泛化,指的是模型在以下场景中的能力:
- 新图:没见过的新图结构(不同节点 ID)
- 新任务:从分类转到预测,或从图 A 迁移到图 B
- 新节点:图中新增节点,不在训练集中出现
5.2 节点 ID 当 token 的问题
ID 是符号性的编号,不是语义。
问题 1:节点 ID 没有语义
1 | node_42 和 node_87 是什么?模型不知道 |
即使它们在不同图中具有类似角色(比如都代表 Transformer),但模型只看到两个完全不同的字符串。
问题 2:ID 是局部的,不具有可迁移性
- A 图中 node_1 ≠ B 图中 node_1
- 每张图的 ID 编号方式都不同
- 模型学到的只是“node_1”在这张图里是什么,不知道在别的图是不是一样
问题 3:新图/新任务完全换 ID
一旦换图,原来学到的所有 ID 都无法复用。模型只能重新学,从零开始。
5.3 Graph Vocabulary 的优势(语言化表示)
Graph Vocabulary 用自然语言 token 表达节点 —— 是“可读的语义表示”。
优势 1:共享语义空间
不同图中可能都有 “Transformer model for translation” 或 “Graph neural network”,这些语义可以共享。
优势 2:LLM 能理解词义
语言模型已经学习了大量 token 之间的语义关系,可以直接利用它的常识和语义结构来进行推理。
优势 3:泛化到新图新节点
新节点可以用“组合已有语言 token”来表达,无需重新定义新的 ID。例如:
1 | "transformer model with self-attention" |
即使训练时没见过这个 exact 表达,但模型可以理解这几个词的组合含义。
5.4 用类比来解释:
节点 ID = 人脸识别中的“编号”
“这个人是 user_4827”,但模型并不知道他是谁。
如果你换一张图(换个编号),模型就不认识这个人了。
Graph Vocabulary = “带描述的标签”
“这个人是一个中年男性,喜欢跑步,戴眼镜”
这时候模型可以根据描述做出泛化判断,即使换图,它仍然知道这类人长什么样。
5.5 结论
| 表示方式 | 是否具有语义? | 可读性 | 可迁移性 | 泛化能力 |
|---|---|---|---|---|
| 节点 ID | ❌ 无语义 | ❌ | ❌ | 弱 |
| Graph Vocabulary | ✅ 有语义 | ✅ 可读 | ✅ 可迁移 | 强 ✅ |
最后总结一句话:
节点 ID 是“编号”,不具备语言模型可理解的语义,因此泛化性差;
而 Graph Vocabulary 是“语言化表达”,能被 LLM 理解、组合、迁移,自然更适合做泛化任务。