LLM supervised Pre-training for Multimodal Emotion Recognition in Conversations
LLM supervised Pre-training for Multimodal Emotion Recognition in Conversations
论文总结
本文提出了一种基于大型语言模型(LLM)监督预训练的多模态对话情感识别方法(MERITS-L),通过结合语音和文本模态,显著提升了对话中情感识别的性能。核心贡献包括:
- LLM监督的文本预训练:利用预训练的ASR系统(Whisper)生成语音转录文本,并通过LLM(如GPT-3.5 Turbo)为这些转录文本自动生成伪标签(“积极”“消极”“中性”),用于微调RoBERTa模型,从而增强文本情感分类能力。
- 分层多模态融合架构:提出分阶段训练策略,从单模态特征提取到对话上下文建模,再到跨模态注意力融合,逐步整合语音和文本信息。
- 实验验证:在IEMOCAP、MELD、CMU-MOSI三个基准数据集上验证模型,结果表明MERITS-L在两项任务上达到SOTA,尤其在跨模态交互场景中表现优异。
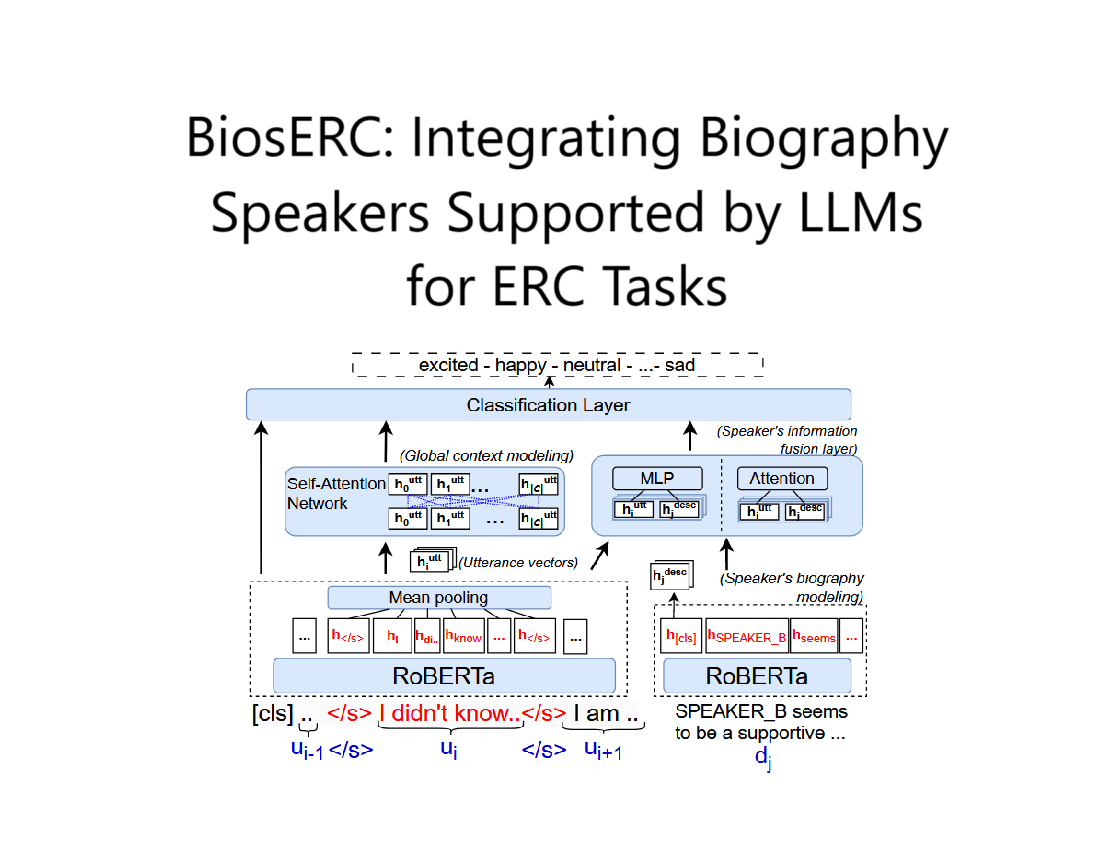
论文模型结构:
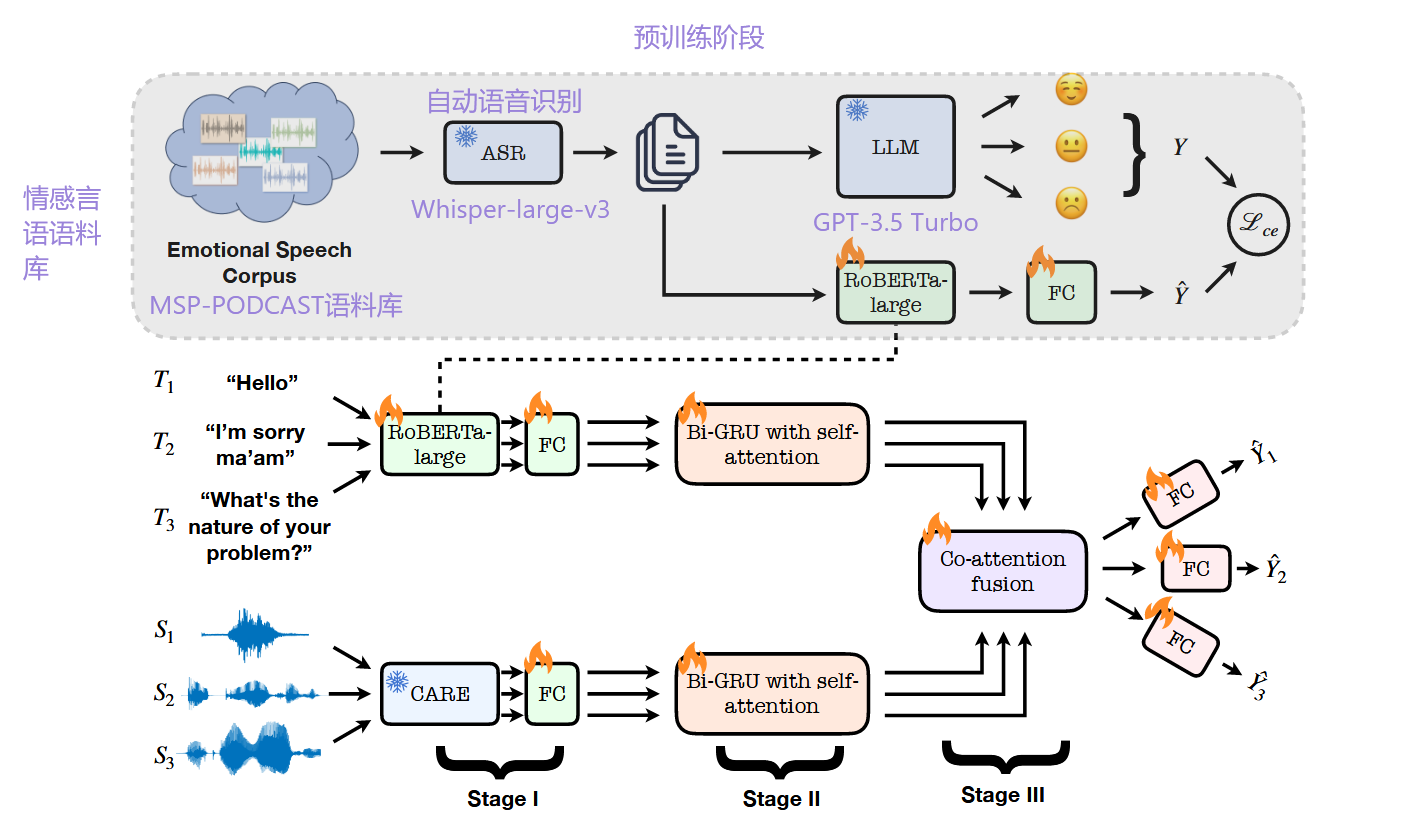
方法部分详细解释
1. 问题定义
输入为对话中的一组话语(utterances)$ U = [(u_1, y_1), (u_2, y_2), \ldots, (u_K, y_K)] $,其中每段话语 $ u_k $ 包含语音信号 $ S_k $ 和文本转录 $ T_k $,目标是预测每段话语的情感标签 $ y_k $。
2. 核心方法流程
(1)LLM监督的文本预训练
- 语音转录生成:使用Whisper-large-v3对原始语音数据进行ASR转录,生成文本。
- 伪标签生成:通过LLM(如GPT-3.5 Turbo)对转录文本进行情感分类,生成三类伪标签。
- RoBERTa微调:用伪标签数据微调RoBERTa-large模型(RoBERTa-FT),作为文本特征提取器。
(2)语音特征提取
- 使用预训练的CARE模型提取语音嵌入,该模型结合语义(对齐RoBERTa文本表示)和声学特征(基于PASE+的低级描述符),生成高质量的语音表征。
(3)分层训练策略
-
Stage I:单模态训练
- 文本模态:用RoBERTa-FT对转录文本进行情感分类,生成话语级文本嵌入 $ T_k^1 $。
- 语音模态:用轻量级网络处理CARE语音嵌入,生成话语级语音嵌入 $ S_k^1 $。
-
Stage II:对话上下文建模
- 文本分支:将 $ T_k^1 $ 输入双向GRU(Bi-GRU)和自注意力模块,生成上下文感知的文本特征 $ T_k^2 $。
- 语音分支:类似地,将 $ S_k^1 $ 处理为上下文感知的语音特征 $ S_k^2 $。
-
Stage III:跨模态融合
- 跨注意力机制:设计跨模态注意力网络(见图2),将 $ T_k^2 $ 和 $ S_k^2 $ 作为查询(Query)、键(Key)、值(Value),通过交叉注意力对齐两种模态的信息。
- 联合分类:融合后的特征通过全连接层进行情感分类。
3. 关键设计细节
- 伪标签生成优化:实验对比不同LLM(如GPT-3.5 Turbo、Mixtral、Llama-3)的伪标签质量,发现GPT-3.5 Turbo的标注效果最佳。
- 分阶段训练的优势:通过逐步训练单模态、上下文建模和跨模态融合,避免端到端训练在小数据集上的过拟合问题(见图4)。
- 对称性融合机制:跨注意力模块在模态性能相近时效果更显著(如IEMOCAP),而对模态性能差异较大的场景(如MELD)提升有限。
4. 实现与训练
- 预训练数据:使用MSP-PODCAST语料库(230小时语音),ASR转录后由LLM标注。
- 下游任务训练:分三阶段进行,每阶段使用交叉熵损失和AdamW优化器,学习率为 $ 1e^{-4} $。
本文的主要贡献点在于主要是在于使用无监督训练
模型的第一个阶段是预训练阶段,他先使用自动语音识别模型将语料库中的音频转换成文字,然后用LLM生成这些文字的情感预测标签作为真实标签,以此来训练他下面要使用的RoBERTa-Large模型。
第二个阶段就是做多模态的情感分析,文字处理使用的是第一阶段训练好的RoBERTa-Large模型,音频处理使用的是这个团队之前的研究成果CARE,之后分别进行特征提取并在最后进行拼接,最后输入到FC层中得到预测结果
这篇文章中说的是他们的贡献点主要在于使用的是无监督训练,以及在训练过程中分了三个stage
相关推荐