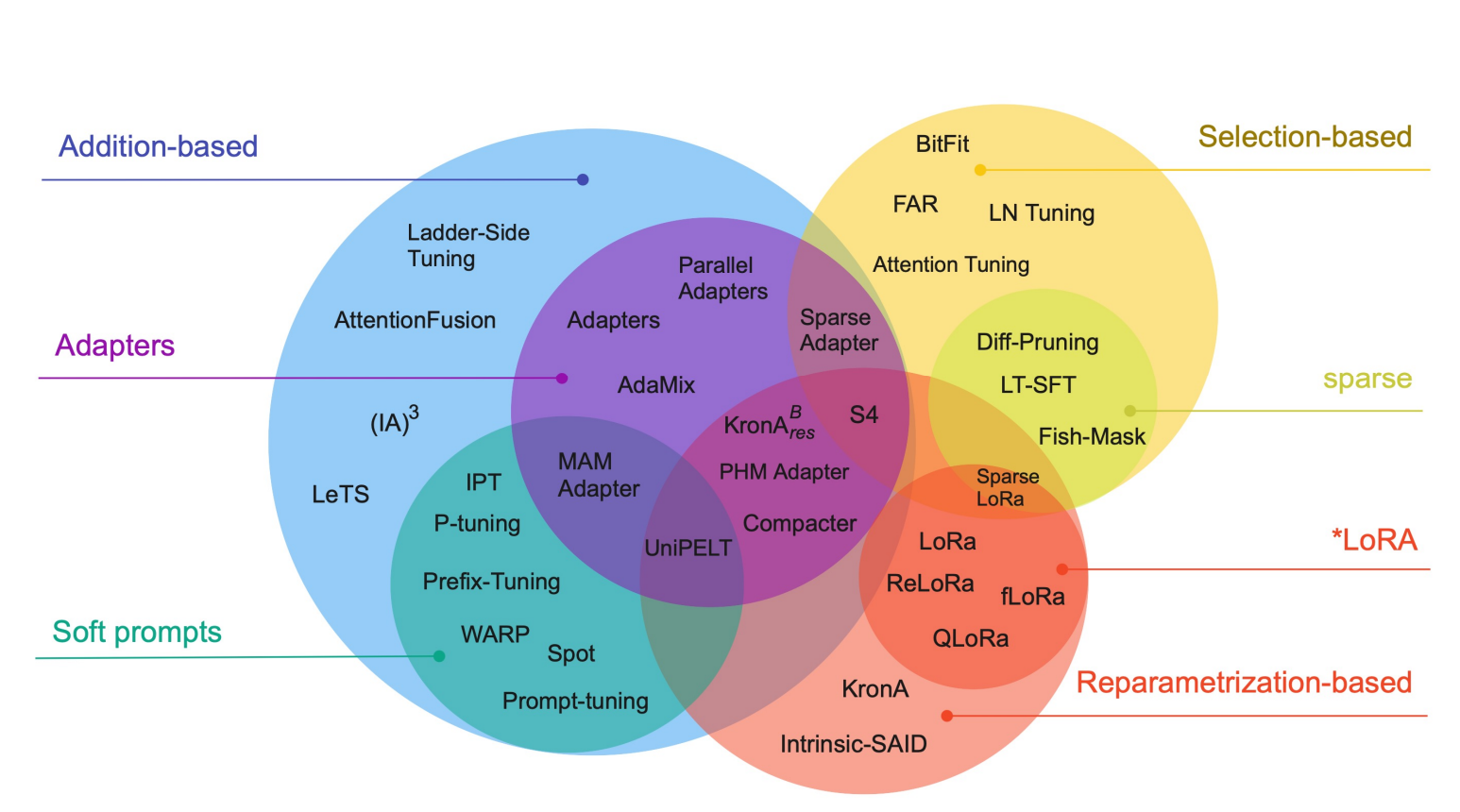
参数高效微调PEFT
随着预训练语言模型的不断发展,模型的参数越来越多,更大的模型带来了更好的性能,但是也带来了一些问题,比如以传统微调的方式对模型进行全量参数更新会消耗巨大的计算与存储资源。
参数高效微调(Parameter-efficient fine-tuning, PEFT)的方法仅对模型的一小部分参数进行训练,这一小部分参数可能是模型自身的,也可能是外部引入的,通过这种训练方式,不仅能够极大地减少需要训练的参数量,一些场景下效果甚至不输于全量微调。
常见的参数高效微调方法见下图:
(图片来源:Scaling Down to Scale Up:A Guide to Parameter-Efficient Fine-Tuning)
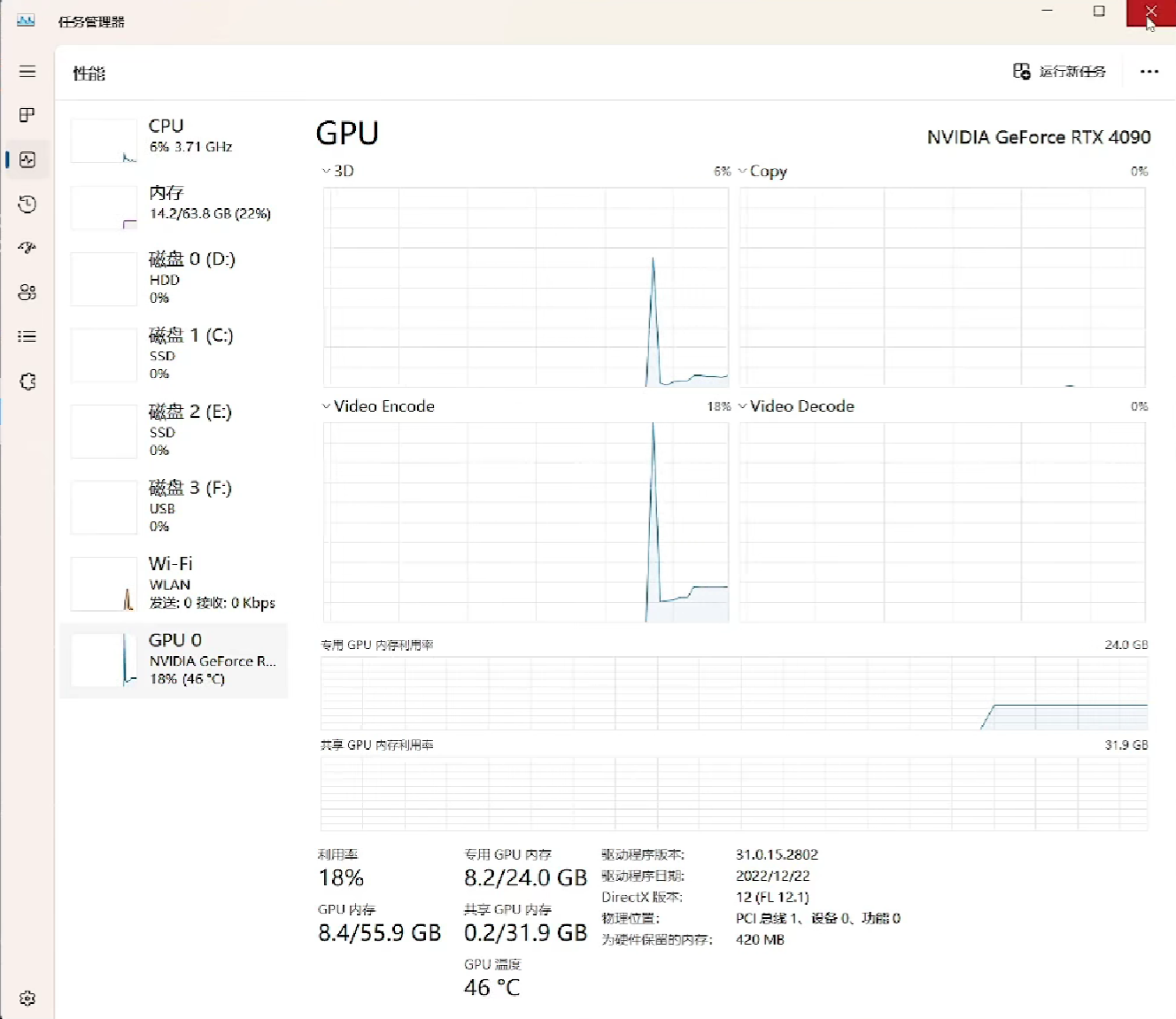
本文使用的基础模型为Langboat/bloom-1b4-zh,模型大小为1.4B
在实际使用时参数量大概为1.3B

所以我们可以大概进行计算
model size: 1.3B
由于LP32的一个参数差不多4字节,所以model: 1.3G * 4 = 5.2G
梯度gradient: 1.3G * 4 = 5.2G
优化optimizer: 1.3G * 4 * 2 =10.4G
所以一共需要的内存大约是20.8G
实际运行时差不多:

一、BitFit
1.1 BitFit原理
BitFit思想:在进行训练时只训练一部分参数,BitFit选择就是只训练模型参数里面的所有bias部分,也就是偏置值,而冻结所有其他参数,从而减少计算和存储成本,同时保持较好的下游任务性能
实现方法:只需要把所有非bias部分的是否需要计算梯度设置为fase即可
1.2 代码实现
1 | # bitfit |
经过优化后的模型参数量约为544768个,相当于优化前的参数量1303111680的0.418%
显存占用率也明显下降


1.3 BitFit的优缺点
优点:
- 高效性:相比全参数微调,计算量和存储需求更低,适合资源受限环境(如移动端、嵌入式设备)。
- 适配性强:能够适用于各种下游任务,而无需存储多个完整的微调模型。
- 迁移性强:由于基础模型的权重未改变,可以快速在多个任务之间切换。
缺点:
- 性能可能略逊于全参数微调:虽然在许多任务上表现良好,但在某些复杂任务上,BitFit 可能比全参数微调略差。
- 适用范围有限:适用于 NLP 任务,但在计算机视觉等领域的效果仍需更多研究。
二、Prompt-Tuning
2.1 Prompt-Tuning原理
Prompt-Tuning思想:冻结主模型全部参数,在训练数据前加入一小段Prompt,只训练Prompt的表示层,即一个Embedding模块。其中,Prompt又存在两种形式,一种是hard prompt,一种是soft prompt,prompt相当于是一种提示

- hard prompt:prompt内容使我们人为定义的
- soft prompt:不指定prompt,让模型自我学习得到
实现方法:可以直接使用peft库进行实现
2.2 代码实现
我们需要先创建一个配置文件,根据配置文件在创建模型
PromptTuningConfig参数说明:
task_type: Optional[TaskType]=field(default=None, metadata={“help”: “The type of task.”}),
peft_type: Optional[PeftType]=field(default=None, metadata={“help”: “The type of PEFT model.”}),
auto_mapping: Optional[dict]=field(default=None, metadata={“help”: “An auto mapping dict to help retrieve the base model class if needed.”}),
base_model_name_or_path: Optional[str]=field(default=None, metadata={“help”: “The name of the base model to use.”}),
revision: Optional[str]=field(default=None, metadata={“help”: “The specific base model version to use.”}),
inference_mode: bool=field(default=False, metadata={“help”: “Whether to use inference mode”}),
num_virtual_tokens: int=field(default=None, metadata={“help”: “Number of virtual tokens”}),
token_dim: int=field(default=None, metadata={“help”: “The hidden embedding dimension of the base transformer model”}),
num_transformer_submodules: Optional[int]=field(default=None, metadata={“help”: “Number of transformer submodules”}),
num_attention_heads: Optional[int]=field(default=None, metadata={“help”: “Number of attention heads”}),
num_layers: Optional[int]=field(default=None, metadata={“help”: “Number of transformer layers”}),
prompt_tuning_init: Union[PromptTuningInit, str]=field(default=PromptTuningInit.RANDOM,metadata={“help”: “How to initialize the prompt tuning parameters”},),
prompt_tuning_init_text: Optional[str]=field(default=None,metadata={“help”: “The text to use for prompt tuning initialization. Only used if prompt_tuning_init isTEXT”},),
tokenizer_name_or_path: Optional[str]=field(default=None,metadata={“help”: “The tokenizer to use for prompt tuning initialization. Only used if prompt_tuning_init isTEXT”},),
tokenizer_kwargs: Optional[dict]=field(default=None,metadata={“help”: ("The keyword arguments to pass toAutoTokenizer.from_pretrained. Only used if prompt_tuning_init is "“TEXT”),},)
2.2.1 Hard Prompt
1 | """ |
经过优化后可训练参数只有16,384个,相当于原来参数1,303,128,064个的0.0013%


2.2.2 Soft Prompt
1 | """ |
经过优化后可训练参数只有20,480个,相当于原来参数1,303,132,160个的0.0016%

2.2.3 加载PEFT训练好的模型
1 | from peft import PeftModel |
2.3 Prompt-Tuning的优缺点
优点:
- 极少的训练参数:仅更新少量 Prompt 嵌入,适用于超大模型。
- 低计算成本:比全参数微调和 Adapter 方式更节省资源。
- 任务适配灵活:不同任务可使用不同的 Prompt,无需存储多个大模型。
缺点:
- 比全参数微调略逊色:Prompt 只能影响输入,可能不如 Adapter 调整 Transformer 结构来得强大。
- 对小模型效果有限:在小型 Transformer(如 BERT-base)上可能不如全参数微调效果好。
三、P-Tuning
3.1 P-Tuning原理
P-Tuning思想:在Prompt-Tuning的基础上,对Prompt部分进行一步的编码计算,加速收敛。具体来说,PEFT中支持两种编码方式,一种是LSTM,一种是MLP。与Prompt-Tuning不同的是,Prompt的形式只有Soft Prompt

实现方法:可以直接使用peft库进行实现
3.2 代码实现
1 | """ |
经过优化后可训练参数有5,267,456个,相当于原来参数1,308,379,136个的0.4026%

3.3 P-Tuning的优缺点
优点:
- 参数高效(Parameter-Efficient):只优化 Soft Prompt + MLP/LSTM,冻结 预训练模型的全部参数,训练成本远低于全参数微调(Full Fine-Tuning)。
- 比 Prompt Tuning 更强大:相比于 Prompt Tuning(仅优化 Soft Prompt 嵌入),P-Tuning 采用 MLP/LSTM 生成 Prompt,具有更强的表示能力。在小样本学习(Few-Shot Learning)任务上表现更佳。
- 适用于 Few-Shot / Zero-Shot 学习:适用于 低资源任务,在少量数据上能获得比全参数微调更优的效果。对 Prompt 设计敏感的任务(如文本分类、问答等)特别有效。
- 灵活性强:由于使用 MLP/LSTM 生成 Prompt,P-Tuning 可以学习更复杂的 Prompt 表达,而不像手工 Prompt 那样受限于自然语言结构。
- 计算效率高:只优化 Soft Prompt + MLP/LSTM,参数量远小于全参数微调,计算需求低,适合 资源受限环境(如云端 API 调用)。
缺点:
- 比全参数微调(Fine-Tuning)略逊色:在大规模数据集上,全参数微调仍然是最优方案,P-Tuning 可能在某些任务上无法超越 Full Fine-Tuning 的性能。主要适用于 低资源任务 或 计算受限场景。
- 依赖模型架构:Soft Prompt 只能影响输入部分,而 LoRA / Adapter 等方法 可以调整 Transformer 内部参数,因此在某些任务上,P-Tuning 可能不如 LoRA 等方法强大。适用于 NLP 任务,但在 计算机视觉(CV) 任务上不如 LoRA / Adapter 常见。
- 训练收敛可能较慢:P-Tuning v1 使用 LSTM 生成 Prompt,可能导致训练不稳定。P-Tuning v2 改进为 MLP,但仍需要 更多的超参数调整 来找到最优的 Prompt 表达。
- 对小模型效果有限:在 大规模 Transformer(如 GPT-3, T5-XXL) 上表现良好,但在 小型模型(如 BERT-base, GPT-2-small) 上,可能 不如全参数微调或 LoRA 。这是因为 Prompt 本质上是通过输入影响模型,而不是直接调整模型内部参数。
四、Prefix-Tuning
4.1 Prefix-Tuning原理
Prefix-Tuning思想:相较于Prompt-Tuning和P-Tuning,Prefix-Tuning不再将Prompt加在输入的Embedding层,而是将其作为可学习的前缀,放置在Transformer模型中的每一层中,具体表现形式为past_key_values
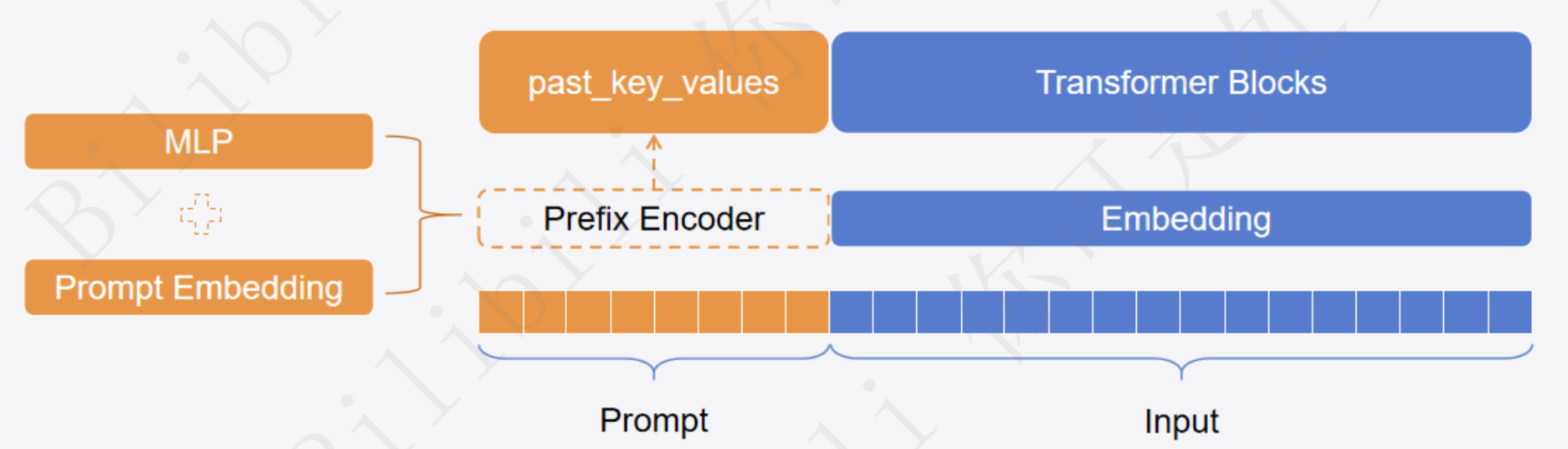
实现方法:可以直接使用peft库进行实现
past_key_values:Transformer模型中解码器是根据之前的token来预测之后的token,这个过程中存在大量的重复计算,因此可以将key和value的计算结果缓存,作为past_key_values输入到下一次的计算中,这一技术被称之为kv_cache。Prefix-Tuning中就是通过past_key_values的形式讲可学习的部分放到了模型中的每一层,这部分内容又被称之为前缀

4.2 Prefix-Tuning 在注意力机制计算中的矩阵形状变化
Prefix-Tuning 的核心是在 Transformer 的多头自注意力(Self-Attention)机制中,为 Key()和 Value()添加可训练的前缀向量,而 Query()仍然基于输入序列计算。因此,矩阵的形状在计算过程中会发生变化。
4.2.1 设定符号与输入形状
假设:
- 批量大小:$ N $
- 序列长度(输入文本的 token 数量):$ T $
- 隐藏层维度(Transformer 维度):$ d_{\text{model}} $
- 注意力头数(multi-head attention 的 head 数量):$ h $
- 每个注意力头的维度(即 ):
- 前缀 token 数量:$ p $(通常 5~50)
- Transformer 层数:$ L $
输入到注意力机制的 Query、Key、Value 计算方式:
其中:
- $ W_Q, W_K, W_V $ 是可训练的权重矩阵,形状为 $ \mathbb{R}^{d_{\text{model}} \times d_{\text{model}}} $。
- $ X $ 是输入序列的嵌入,形状为 $ (N, T, d_{\text{model}}) $。
- 计算出的 $ Q, K, V $ 形状为 $ (N, T, d_{\text{model}}) $。
由于注意力机制是 多头 的,因此我们将 $ d_{\text{model}} $ 划分成 $ h $ 个头,每个头的维度是 $ d_h = \frac{d_{\text{model}}}{h} $:
通常会被 重塑(reshape) 为:
4.2.2 Prefix-Tuning 中 Key 和 Value 形状的变化
在 Prefix-Tuning 中,我们引入 可训练的前缀向量,分别作用于 Key 和 Value:
其中:
- $ p $ 是前缀 token 数量。
- $ L $ 是 Transformer 层数(不同层的 Prefix 可能不同)。
- 每个 Prefix 向量的维度与 $ d_{\text{model}} $ 相同。
同样,我们需要将 前缀向量划分为多个头:
然后重塑为:
在计算注意力时,每一层的 Key 和 Value 拼接 额外的前缀向量:
其中:
- 原始 $ K $ 形状:$ (N, h, T, d_h) $。
- 前缀 $ P_K $ 形状:$ (L, h, p, d_h) $。
- 拼接后的 $ K’ $ 形状:$ (N, h, T + p, d_h) $。
同理:
- 原始 $ V $ 形状:$ (N, h, T, d_h) $。
- 前缀 $ P_V $ 形状:$ (L, h, p, d_h) $。
- 拼接后的 $ V’ $ 形状:$ (N, h, T + p, d_h) $。
4.2.3 计算注意力分数
计算注意力权重:
其中:
- $ Q $ 形状:$ (N, h, T, d_h) $。
- $ K’^T $ 形状:$ (N, h, d_h, T + p) $(转置后)。
- 矩阵乘法后的注意力权重 $ A $ 形状:
然后对注意力权重进行 Softmax 归一化:
其形状仍然是 $ (N, h, T, T + p) $。
4.2.4 计算注意力输出
计算最终的注意力输出:
其中:
- $ A $ 形状:$ (N, h, T, T + p) $。
- $ V’ $ 形状:$ (N, h, T + p, d_h) $。
- 矩阵乘法后的 $ O $ 形状:
然后进行 多头合并:
最终经过一个 线性变换(使用可训练矩阵 $ W_O \in \mathbb{R}^{d_{\text{model}} \times d_{\text{model}}} $),恢复到模型的原始输出维度:
最终输出形状:
4.2.5 总结
在 Prefix-Tuning 中,矩阵形状变化如下:
-
输入嵌入:
- $ X \in \mathbb{R}^{N, T, d_{\text{model}}} $
-
计算 Query、Key、Value:
- $ Q, K, V \in \mathbb{R}^{N, h, T, d_h} $
-
拼接前缀向量:
- $ P_K, P_V \in \mathbb{R}^{L, h, p, d_h} $
- $ K’ = [P_K; K] \in \mathbb{R}^{N, h, T + p, d_h} $
- $ V’ = [P_V; V] \in \mathbb{R}^{N, h, T + p, d_h} $
-
计算注意力权重:
- $ A = Q K’^T \in \mathbb{R}^{N, h, T, T + p} $
-
计算最终注意力输出:
- $ O = A V’ \in \mathbb{R}^{N, h, T, d_h} $
- 合并多头后恢复为 $ \mathbb{R}^{N, T, d_{\text{model}}} $
Prefix-Tuning 通过 仅调整 Key 和 Value(而不改变 Query),让前缀向量影响注意力分布,使模型适应特定任务,同时减少参数更新量。
4.3 代码实现
1 | """ |
不使用prefix_projection的prompt_encoder:

使用prefix_projection的prompt_encoder:
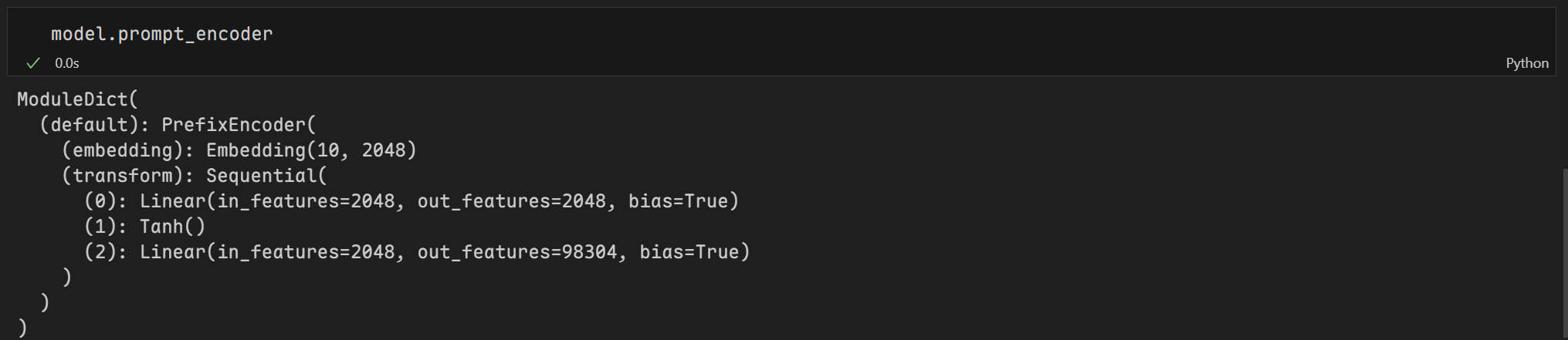
经过优化后可训练参数有983,040个,相当于原来参数1,304,094,720个的0.0754%

在 Prefix-Tuning 的实现(如 transformers 库中的 PrefixTuningConfig)中,prefix_projection 是一个 布尔参数,它决定了是否对前缀(prefix)进行 可学习的投影(projection),从而引入 更复杂的前缀表示。
prefix_projection 的作用
-
如果
prefix_projection = False(默认情况):- 前缀向量 $ P_K $ 和 $ P_V $ 直接是可训练的参数,不经过额外的变换,形状为 $ (p, d_{\text{model}}) $(或者拆分成多头后 $ (p, h, d_h) $)。
- 这种方式 参数量较少,训练 更稳定,适用于小规模任务。
-
如果
prefix_projection = True:- 前缀向量 $ P $ 先经过一个小型的前馈神经网络(MLP)投影,使其从一个 较小的隐含空间 投影到 更大的维度,从而增加表达能力:
- MLP 通常是一个单隐藏层的前馈网络,可以用
tanh或ReLU激活函数: - 这样,模型可以 学习到更复杂的前缀表示,适用于更复杂的任务(如对话、摘要生成等)。
- 代价是 计算量略大,但仍比 Fine-Tuning 轻量。
- 前缀向量 $ P $ 先经过一个小型的前馈神经网络(MLP)投影,使其从一个 较小的隐含空间 投影到 更大的维度,从而增加表达能力:
使用prefix_projection的代码:
1 | # 配置文件 |
使用prefix_projection的prompt_encoder:

经过优化后可训练参数有205,641,728个,相当于原来参数1,508,753,408个的13.6299%

4.4 Prefix-Tuning的优缺点
优点:
-
低计算成本 & 低存储需求
- 冻结原始模型,只训练 少量的前缀参数(通常占总参数的 不到 1%)。
- 减少存储成本:多个任务只需要存储不同的前缀,而不是整个模型。
- 适用于 资源受限的设备(如边缘计算、移动端部署)。
-
适用于大规模语言模型
- 由于 不改变预训练模型的权重,Prefix-Tuning 能很好地适用于大模型(如 GPT-3、T5 等)。
- 在 超大规模参数(>10B)的 Transformer 模型上,Prefix-Tuning 的效果通常比 Fine-Tuning 更好,因为它减少了过拟合的风险。
-
训练稳定
- 相比于 Prompt-Tuning(直接优化嵌入),Prefix-Tuning 在优化时更稳定,梯度更容易传播。
- 减少了 Prompt-Tuning 中出现的梯度消失问题,从而在小数据集上也能有效训练。
-
灵活性强
- Prefix-Tuning 适用于 多种 NLP 任务,包括 文本生成(摘要、翻译、对话)、分类任务(情感分析)、知识问答 等。
- 由于前缀是独立的,可以用于 多任务学习,在不同任务之间共享基础模型,仅调整不同任务的前缀。
-
更强的可解释性
- 相比于 Fine-Tuning,Prefix-Tuning 的参数量较少,研究者可以直接分析哪些前缀影响了模型的行为,有助于 理解模型的决策机制。
缺点
-
适用于生成任务,分类任务效果可能不如 Fine-Tuning
- Prefix-Tuning 主要作用在 Key 和 Value 上,影响注意力分布,因此在 文本生成任务(如 GPT, T5)上效果较好。
- 对于分类任务(如 BERT 任务),Prefix-Tuning 可能不如 Fine-Tuning 有效,因为分类任务更依赖于最后一层的特征表示。
-
需要更长的前缀(影响计算效率)
- Prefix-Tuning 通过 在 Key 和 Value 上增加前缀 来影响注意力计算,这意味着 前缀长度 ( p ) 会影响计算复杂度:
- 更长的前缀(如 50~100 个 token)会导致更高的计算开销。
- 但如果前缀 太短,可能不能充分影响模型行为。
- 相比于 Fine-Tuning,Prefix-Tuning 可能会增加计算成本,尤其是在序列较长时。
- Prefix-Tuning 通过 在 Key 和 Value 上增加前缀 来影响注意力计算,这意味着 前缀长度 ( p ) 会影响计算复杂度:
-
依赖于任务 & 预训练模型
- 对于不同的任务,Prefix-Tuning 需要找到合适的前缀长度和初始化方式,否则效果可能不稳定。
- 在某些任务上,Fine-Tuning 仍然是最优的选择,特别是当任务需要改变模型的深层参数时。
-
需要调试
prefix_projection- 是否使用
prefix_projection(MLP 投影) 需要调试:- 不使用时,表达能力可能不足,尤其是复杂任务。
- 使用时,计算复杂度增加,可能需要更多数据来稳定训练。
- 是否使用
五、LoRA
5.1 LoRA原理
LoRA思想:
- 预训练模型中存在一个极小的内在维度,这个内在维度是发挥核心作用的地方
- 在继续训练的过程中,权重的更新依然也有如此特点,即也存在一个内在维度(内在秩)
- 权重更新:W = W + ΔW
- 因此,可以通过矩阵分解的形式,将原本要更新的大矩阵变成两个小矩阵
- 权重更新:W = W + ΔW = W + BA
具体做法:
- 即在矩阵计算中增加一个旁系分支,旁系分支由两个低秩矩阵A和B组成
- 训练时输入分别于原始权重和两个低秩矩阵进行计算,共同得到最终结果,优化则仅优化A和B
- 训练完成后,可以将两个低秩矩阵与原始模型中的权重进行合并,合并后的模型与原始模型无异,避免了推理期间Prompt系列方法带来的额外计算量
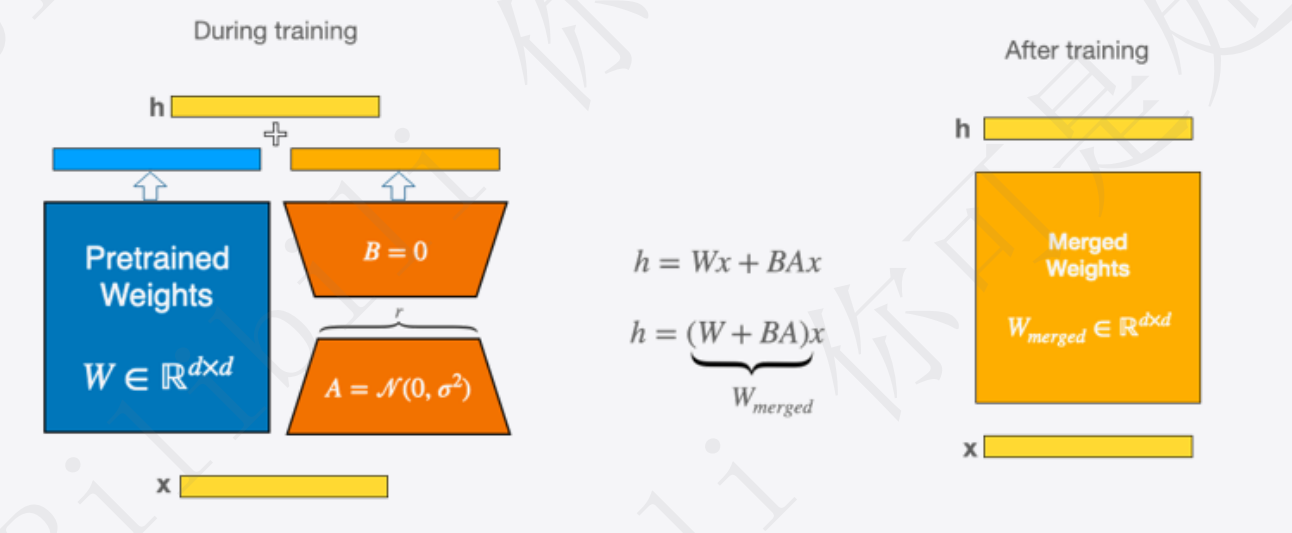
实现方法:可以直接使用peft库进行实现
5.2 代码实现
1 | """ |
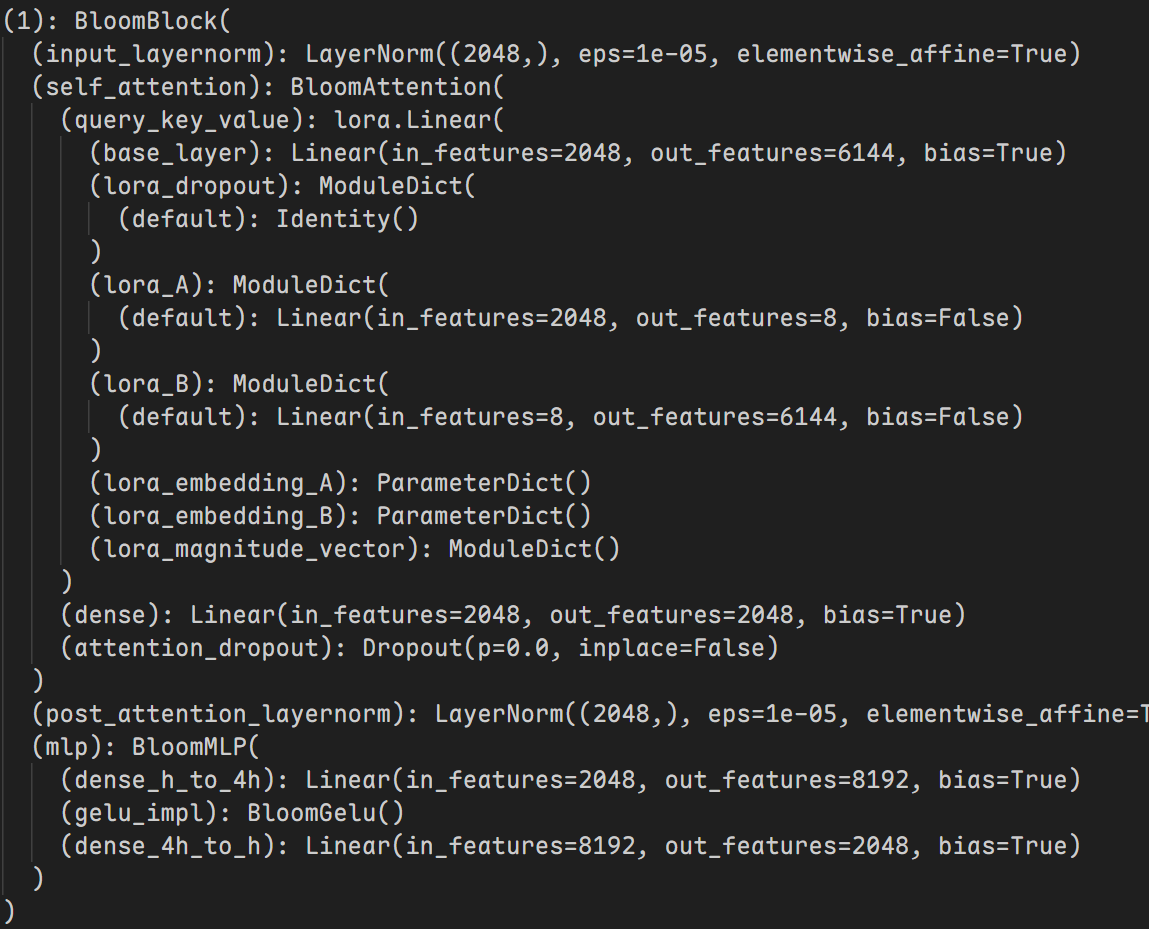
再使用target_modules指定要使用LoRA的层后模型内部会发生变化:
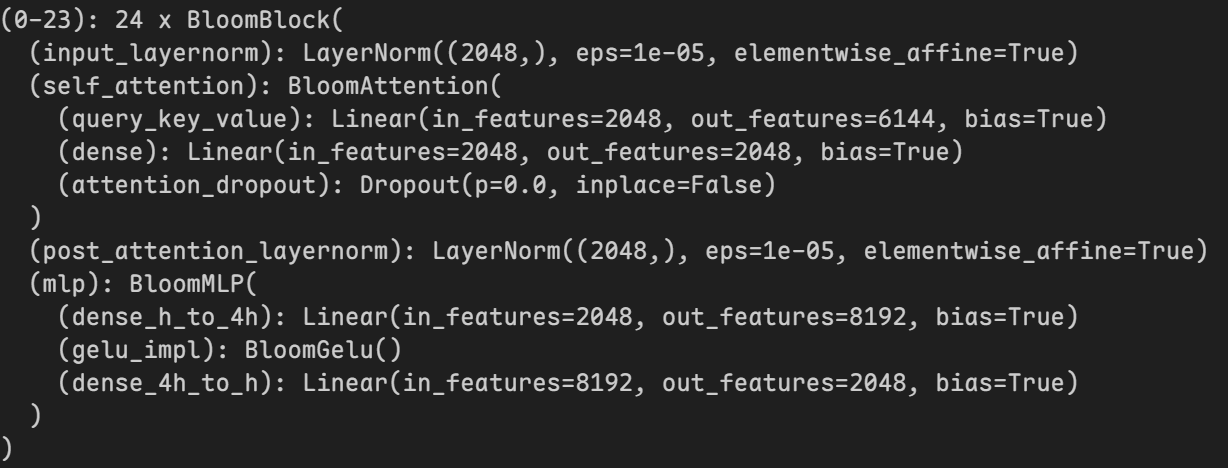 |
 |
|---|
经过优化后可训练参数有95,225,856个,相当于原来参数1,398,337,536个的6.8099%

5.3 LoRA训练模型与原模型合并
合并的影响
-
优点:
- 部署时不再需要额外的 LoRA 适配器权重,方便模型的独立使用。
-
缺点:
- 一旦合并,LoRA 的低秩适配器就会被计算到原模型权重中,无法再独立调节 LoRA 影响力(如不同 LoRA 适配器的组合)。
- 合并后,模型存储大小会恢复到原始全参数微调的级别,失去 LoRA 低存储的优势。
1 | from transformers import AutoModelForCausalLM, AutoTokenizer |
5.3 LoRA的优缺点
优点:
-
大幅减少可训练参数,节省计算资源
- 传统全参数微调需要更新整个模型(如 LLaMA-7B 约 130 亿 参数),而 LoRA 仅添加 少量低秩矩阵(通常占 0.1% ~ 1% 参数)。
- 训练时 仅更新 LoRA 适配器,而不改变原模型参数,减少显存占用和计算量。
-
更低的存储需求
- 由于原模型参数不变,只需存储 LoRA 适配器(通常是 MB 级别),而不是整个 GB 级别的模型。
- 适用于 存储多个任务的 LoRA 适配器,而无需为每个任务存储独立模型。
-
快速适配不同任务
- 你可以 同时加载多个 LoRA 适配器,适配不同任务,而无需单独微调整个模型。
- 例如,一个基础大模型可以在多个任务(文本摘要、情感分析、对话生成等)上分别训练 LoRA 适配器,并在推理时 动态加载不同的适配器。
-
适用于多种模型(Transformer、CNN、GNN)
- LoRA 最初用于 Transformer 语言模型(如 LLaMA、GPT),但也适用于 CNN(计算机视觉)、GNN(图神经网络)、分子模拟等任务。
-
训练更稳定,避免灾难性遗忘
- 由于原模型参数保持不变,LoRA 不会像全参数微调那样导致模型遗忘原有能力。
- 适用于 少量数据场景(如医学、金融领域的小样本微调)。
缺点:
-
推理时仍需加载 LoRA 适配器
- LoRA 训练的参数是额外的 适配器,推理时需要 同时加载原模型和 LoRA 参数,可能增加存储管理复杂度。
- 如果需要一个独立的模型,可能需要 合并 LoRA 参数,但这样会失去 LoRA 低存储的优势。
-
可能不适用于所有任务
- LoRA 主要对 Transformer 的 FFN 和 Self-Attention 层生效,但对于某些特定任务(如需要调整输入嵌入或大规模结构调整)可能不够灵活。
- 在 小型模型上(参数少于 100M),LoRA 可能带来的节省不明显,甚至会影响性能。
-
R 维度选择影响效果
- LoRA 的 秩 (Rank, R) 是一个超参数,决定了低秩矩阵的维度。
- 过小 (R 太低):模型调整能力不足,影响性能。
- 过大 (R 太高):会接近全参数微调,失去 LoRA 的存储和计算优势。
六、IA3
6.1 IA3原理
IA3思想:
- IA3(Infused Adapter by Inhibiting and Amplifying Inner Activations),IA3的思想就是抑制和放大内部的激活函数,通过可学习的向量对激活值进行抑制或放大。
具体做法:
- 会对K、V、FFN三部分的值进行调整,训练过程中同样冻结原始模型的权重,只更新课学习的部分向量部分
- 训练完成后,与LoRA类似,也可以将学习部分的参数与原始权重合并,没有额外的推理开销
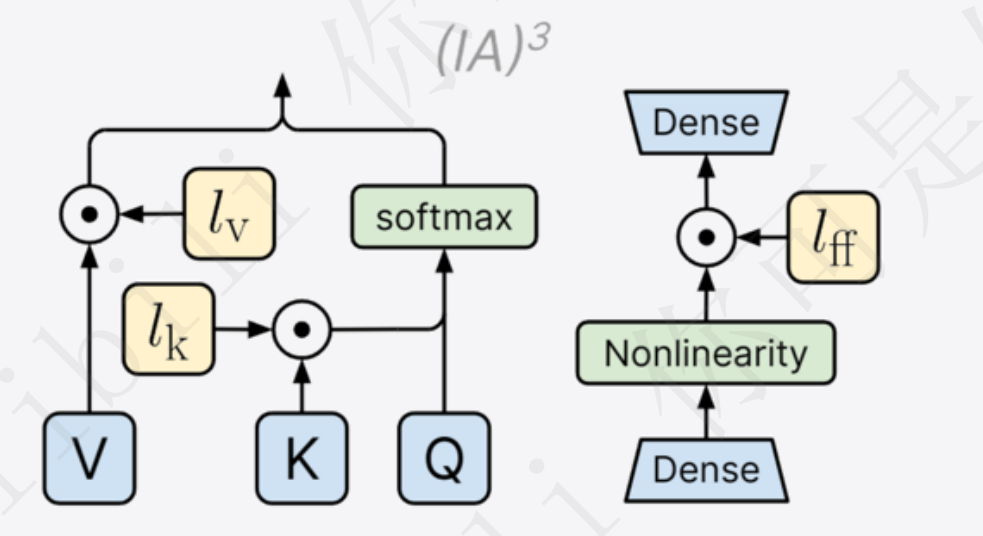
实现方法:可以直接使用peft库进行实现
6.2 代码实现
1 | """ |
在使用target_modules指定要使用IA3的层后模型内部会发生变化:
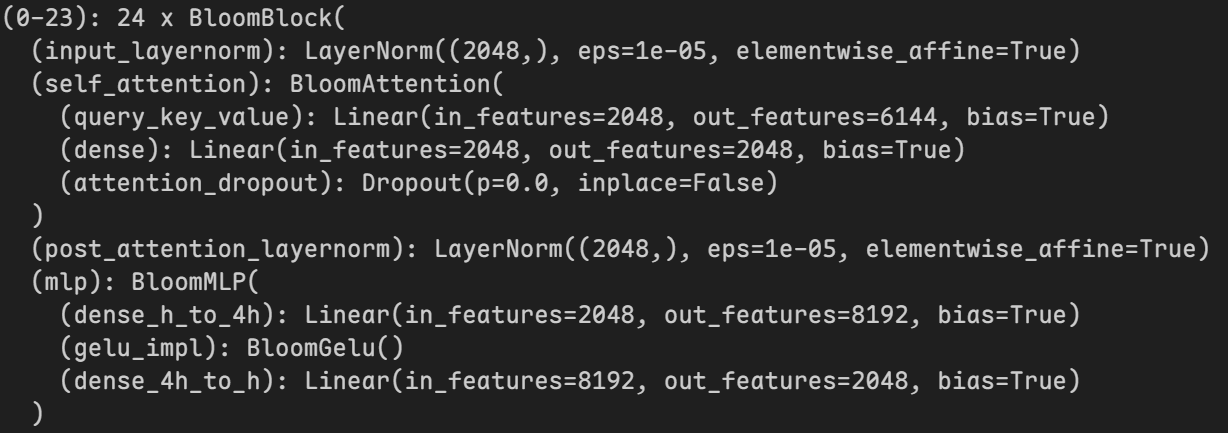 |
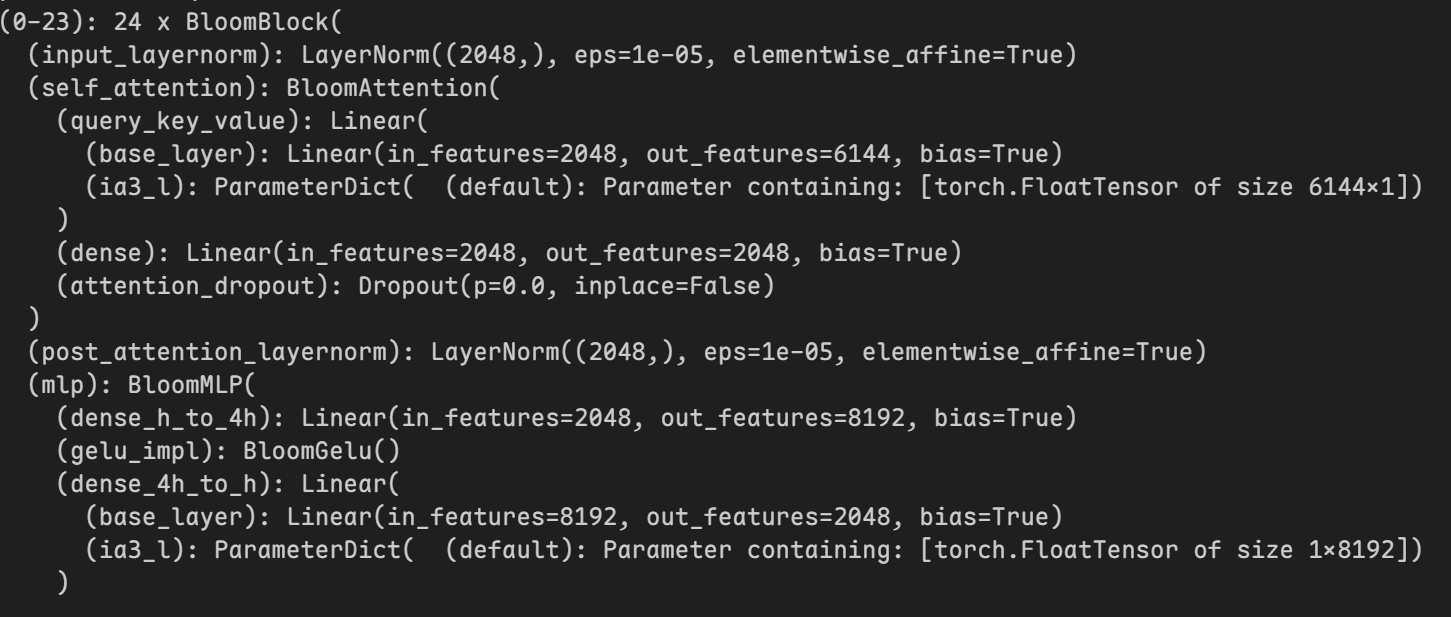 |
|---|
这里IA3在mlp层中的实现方式与图片中的位置不太一样:图片中是在两个dense层之间,但实际上是在第二个dense层中
原因:其实在源码中IA3的实现是在第二个dense层的前面部分,所以实际上IA3的实现还是在两个dense层之间
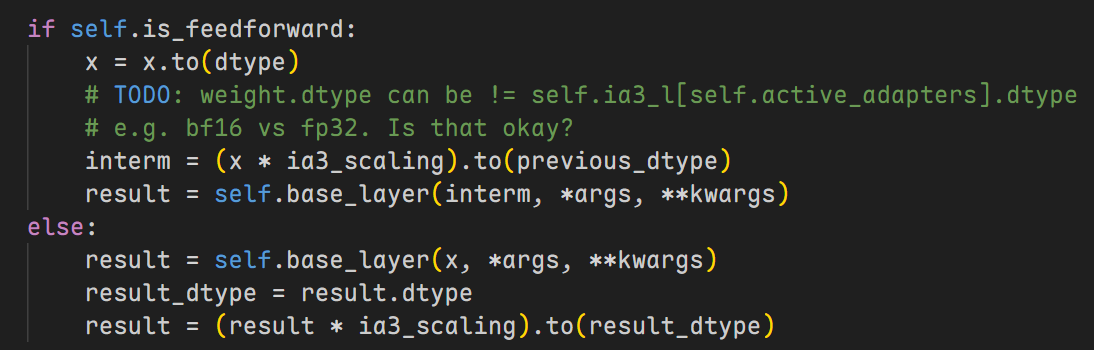
经过优化后可训练参数有344,064个,相当于原来参数1,303,455,744个的0.0264%

6.3 IA3的优缺点
优点:
-
参数高效
- 只在注意力层和 MLP 层的输入处引入可训练的缩放参数,避免了对整个模型进行微调,从而减少了存储和计算开销。
-
避免灾难性遗忘
- 由于不会修改原始的模型权重,IA3 允许模型在不同任务之间共享一个基础模型,而不会影响原始知识。
-
减少计算成本
- 训练过程中仅调整少量参数,使得微调时计算资源占用远低于全参数微调(Full Fine-Tuning)。
-
易于集成
- 仅需在 Transformer 的关键层(注意力层和 MLP 层)增加少量额外参数,无需改动模型架构,适用于大多数 Transformer 变体。
-
比 LoRA 更简单
- 相比于 LoRA(Low-Rank Adaptation),IA3 只引入简单的缩放参数,而不是低秩矩阵,因此计算开销更小,并且不引入额外的矩阵乘法。
缺点 :
-
可表达性受限
- IA3 仅通过缩放现有激活值来调整模型,而不像 LoRA 那样可以学习更复杂的变换,因此在某些任务上的适配能力可能不如 LoRA 或 Adapter 方法。
-
对任务敏感
- 由于 IA3 只是对注意力和 MLP 进行缩放,它可能无法适应所有类型的任务,特别是在需要复杂表示调整的任务中可能表现较弱。
-
适应能力可能不如全参数微调
- 由于 IA3 仅修改缩放因子,而不是学习新的参数,因此在某些需要大幅调整模型行为的任务上,它可能无法达到全参数微调的效果。
-
在低数据任务上可能不稳定
- 如果训练数据较少,IA3 可能无法有效学习适当的缩放参数,从而影响最终性能。
七、PEFT进阶操作
7.1 自定义模型适配
如何在自定义的模型中使用LoRA等方法呢?
其实就是传递在Config中配置相应的参数就可以了
首先我们创建自定义的模型
1 | import torch |
模型结构为:
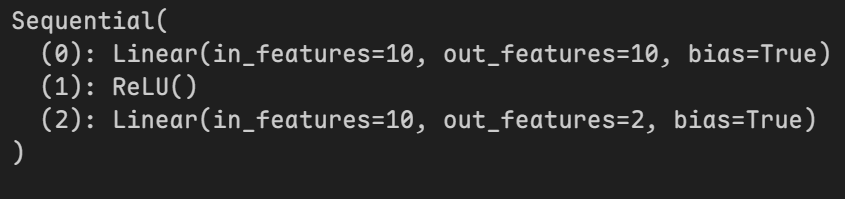
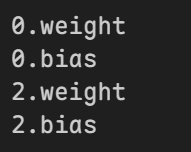
然后我们可以使用param查看可训练的层
1 | for name, param in net.named_parameters(): |
可训练的层有:
之后设置参数并创建模型
1 | config = LoraConfig(target_modules=["0"]) |
使用LoRA后的模型结构为:

这样就实现了对自定义模型的适配
7.2 多适配器加载与切换
首先创建模型分别作不同的LoRA训练
1 | net = nn.Sequential( |
模型结构为:
加载训练好的模型
第一次加载时需要加载主模型
第二次加载时就不需要加载主模型了
1 | # 加载LoraA |
仅加载LoraA后模型结构为:
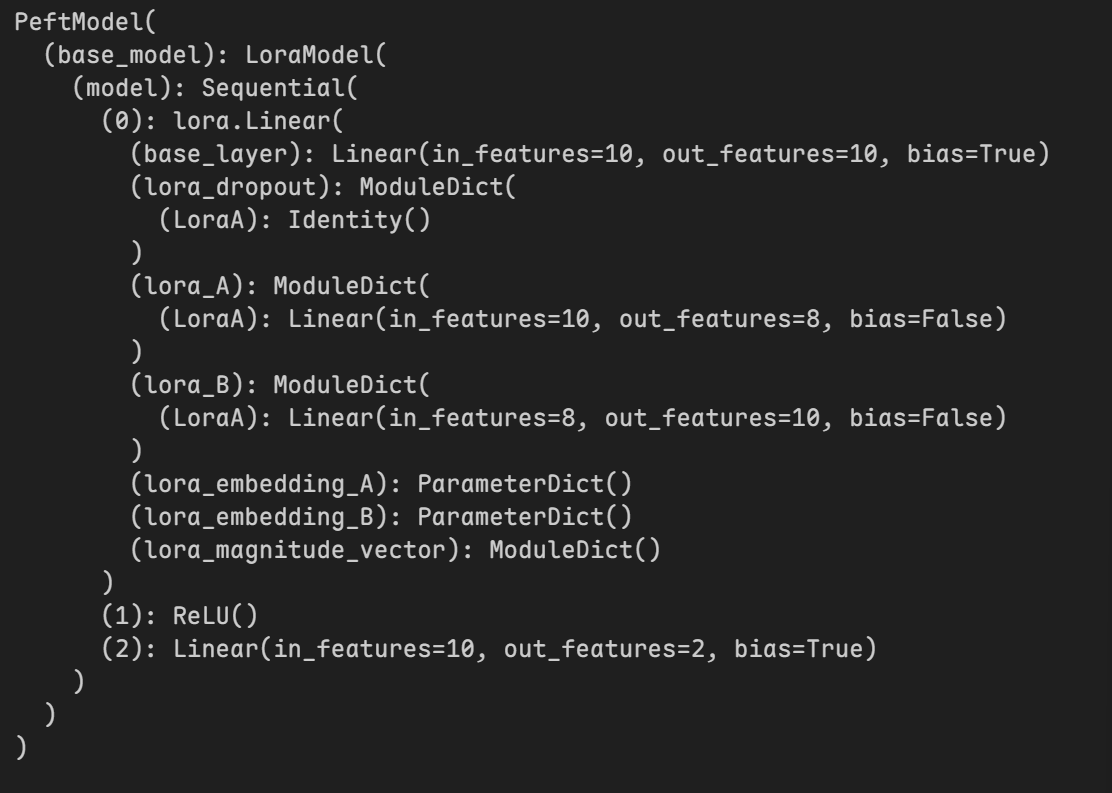
加载LoeaB后模型结构为:
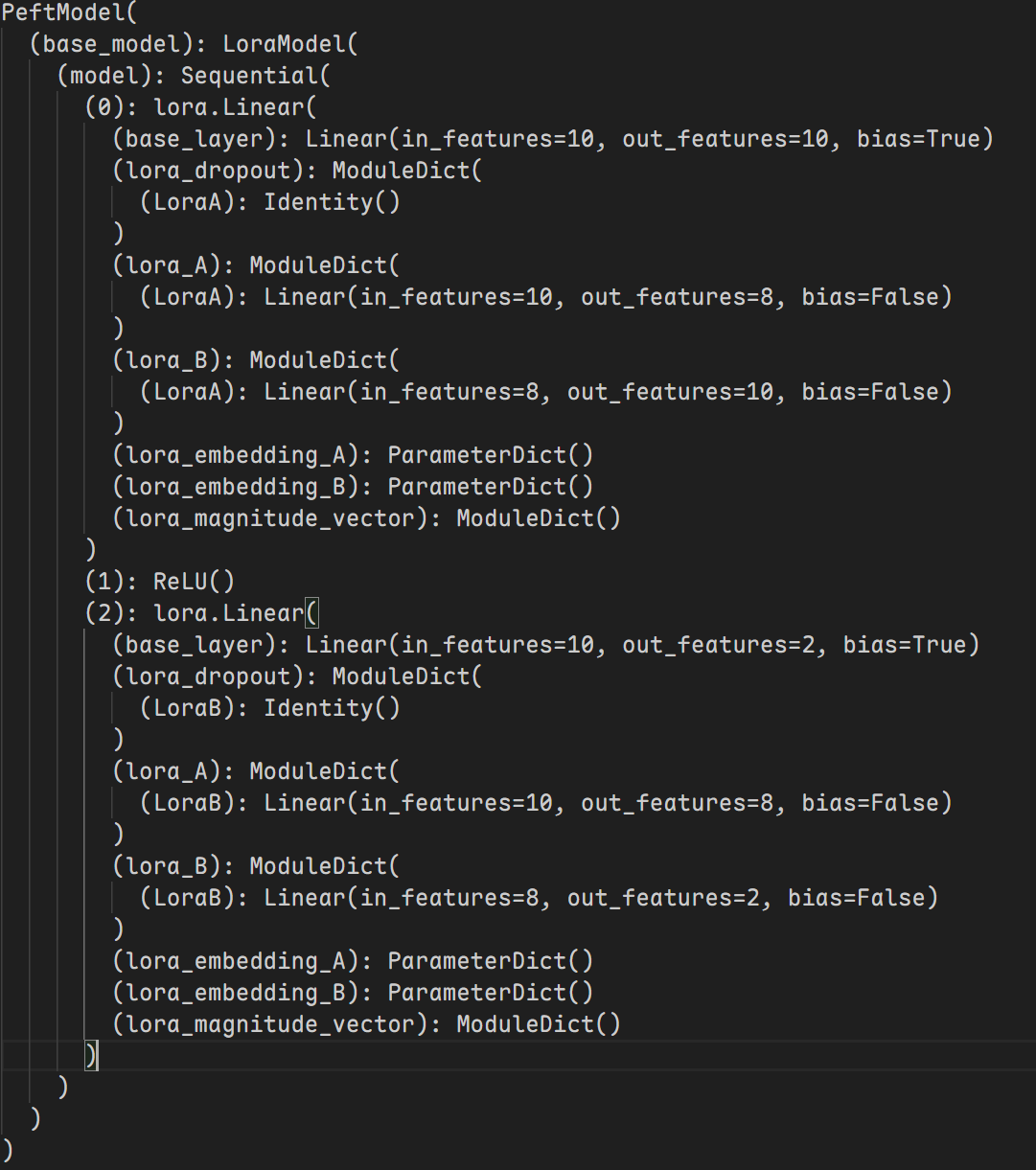
查看当前使用的模型
默认使用LoraA
1 | model.active_adapter |
切换模型
1 | model.set_adapter("LoraB") |
7.3 禁用适配器
禁用适配器,也就是使用原始模型进行输出任务
1 | with model.disable_adapter(): |
八、总结
以下是 BitFit、Prompt-Tuning、P-Tuning、Prefix-Tuning、LoRA 和 IA3 的对比总结:
| 方法 | 主要思想 | 调整的参数 | 计算成本 | 存储需求 | 适用场景 | 备注 |
|---|---|---|---|---|---|---|
| BitFit | 只对偏置项进行微调 | 仅调整模型的偏置项 | 低 | 低 | 轻量级适配任务 | 适用于资源受限场景 |
| Prompt-Tuning | 在输入中加入可训练的提示向量 | 可训练的 prompt 向量 | 低 | 低 | 小数据微调 | 依赖手工设计的 prompt |
| P-Tuning | 用可训练的连续向量替代离散文本提示 | 可训练的 prompt 嵌入 | 低 | 低 | 小样本学习 | 适用于复杂 NLP 任务 |
| Prefix-Tuning | 对注意力层的 key 和 value 进行微调 | 仅调整前缀向量 (prefix) | 低 | 低 | 生成任务 | 避免影响原始模型权重 |
| LoRA (Low-Rank Adaptation) | 在特定层添加低秩适配矩阵 | 低秩矩阵 (A、B) | 低 | 低 | 迁移学习 | 适用于大模型,节省显存 |
| IA3 (Intrinsic Attention Adapters) | 仅调整注意力层的缩放因子 | 仅调整注意力层缩放参数 | 低 | 低 | 任务适配 | 不影响模型原权重 |
参考资料:
[1] 【手把手带你实战HuggingFace Transformers-入门篇】基础知识与环境安装
[2] 项目地址