LaERC-S:Improving LLM-based Emotion Recognition in Conversation with Speaker Characteristics
LaERC-S:Improving LLM-based Emotion Recognition in Conversation with Speaker Characteristics
LaERC-S 模型的具体流程如下:
1. 整体框架
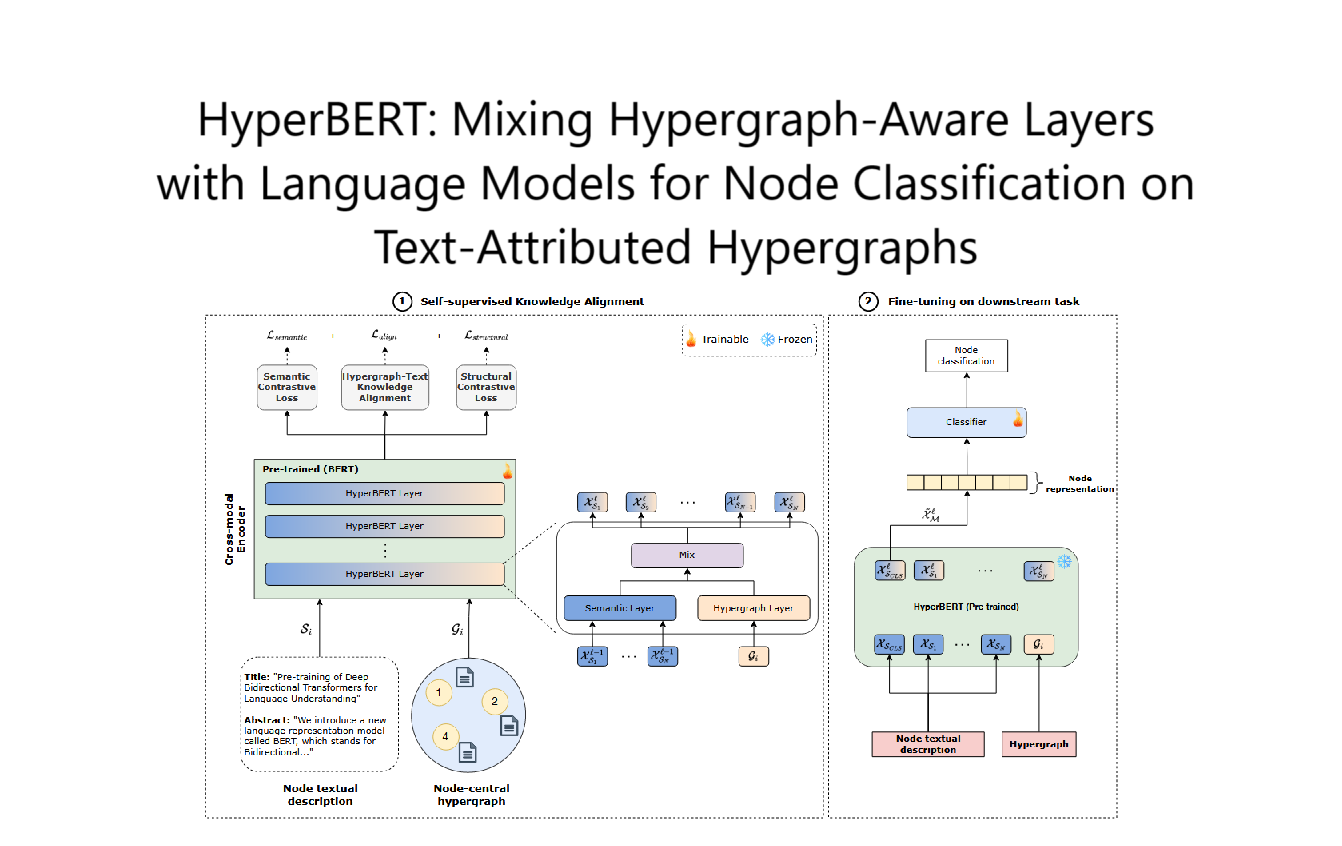
LaERC-S 主要用于对话中的情感识别(Emotion Recognition in Conversation, ERC),核心思想是结合 大语言模型(LLMs) 和 说话人特征(Speaker Characteristics),以更精准地预测对话中每个话语的情感状态。模型采用 两阶段学习(Two-Stage Learning),分为:
- 第一阶段:说话人特征提取与注入
- 第二阶段:情感识别
2. 模型流程
LaERC-S 由以下几个关键步骤组成:
(1) Vanilla ERC Model(基础 ERC 任务)
- 输入:对话数据 $D = {(C_i, Y_i)}_{i=1}^{N} $,其中 是第 个对话, 是对应的情感标签。
- 每个对话 由一系列话语 组成,每个话语 具有一个真实情感标签 (如快乐、愤怒等)。
- 目标:让 ERC 模型 从 LLMs 进行学习,输出话语 的情感类别 :
其中, 表示当前话语 之前的历史话语, 为所有可能的情感类别集合。
(2) 说话人特征提取(Speaker Characteristic Extraction)
- 核心思想:使用 提示学习(Prompt Engineering) 提取 LLMs 的世界知识,生成对话参与者的说话人特征。
- 说话人特征包含三个部分:
- 心理状态(Mental State):描述说话人的情感状态(如 xIntent, xReact, oReact)。
- 行为(Behavior):描述对事件的行为反应(如 xWant, oWant, xEffect, oEffect, xNeed)。
- 个性(Persona):描述说话人的属性(如 xAttr)。
- 处理方式:
- 设计查询模板(Query Templates),向 LLMs 提问获取说话人特征信息。
- 通过手动验证提高信息质量(实验中选择了 “oReact” 作为最佳特征)。
- 以结构化方式存储和使用这些特征信息。
(3) 说话人特征注入(Speaker Characteristic Injection)
- 目的:将提取的说话人特征注入 LLMs,以增强模型对对话情感动态的理解能力。
- 方法:
- 设计 指令调优(Instruction Tuning) 模板,引导 LLMs 学习对话情感线索。
- 模板包含:
- 标题(Title):设定 LLMs 在情感分析任务中的角色(如“你是一位擅长情感分析的专家”)。
- 特定标记(Specific Token):区分不同部分的内容(如对话文本、任务目标)。
- 目标描述(Objective):简要描述任务(如“请预测该话语的情感”)。
- 约束(Constraint):限制输出范围(如情感标签集合)。
- 通过微调 LLMs,确保它能够感知这些情感特征,并在后续任务中使用。
(4) 情感识别(Emotion Recognition)
- 目的:利用前述步骤中的信息,提高对话情感预测的准确性。
- 方法:
- 再一次指令调优,让 LLMs 通过对话上下文推断最终的情感标签。
- 目标函数(Loss Function):
其中:
- 表示不同任务阶段(如特征注入、情感识别)。
- 代表不同阶段输入的指令模板,用于指导LLMs进行情感分析。
- 是生成的输出 token,即模型输出的情感类别。
- 是 LLMs 的可训练参数。
3. 实验结果
- 数据集:
- IEMOCAP(6 类情感)
- MELD(7 类情感)
- EmoryNLP(7 类情感)
- 对比方法:
- 传统 ERC 方法(如 COSMIC、SKAIG)
- LLMs-based 方法(如 InstructERC、BiosERC)
- 性能表现:
- LaERC-S 在所有数据集上均取得最佳效果。
- 在 IEMOCAP 数据集上,相较于 InstructERC 提升 1.01%。
- 采用 “oReact” 作为特征,性能最佳。
4. 关键影响因素分析
- 不同说话人特征的影响:
- “oReact” 带来最佳性能提升,因为它描述了听众的情感反应,能更好地捕捉对话动态。
- 不同 LLMs 影响:
- LLaMA2-7B 提取的特征效果最佳。
- 不同模板的影响:
- 经过实验选择了 “the reaction of potential listeners” 这一描述,能够最准确地提取特征。
5. 总结
LaERC-S 通过两阶段学习:
- 第一阶段 提取和注入说话人特征,使 LLMs 感知对话情感动态。
- 第二阶段 在此基础上进行情感识别,提高 ERC 任务的准确性。
通过实验表明,LaERC-S 具有 更好的泛化能力、更高的情感识别精度,在多个数据集上实现 SOTA(State-of-the-Art)效果。
Pipline
LaERC-S Model 的作用
LaERC-S 是一个基于 大语言模型(LLMs) 的框架,旨在改进 对话情感识别(Emotion Recognition in Conversation, ERC) 的效果。
其 主要作用 是:
-
增强 LLMs 识别情感的能力:
- 通过提取和注入说话人特征(Speaker Characteristics),如心理状态、行为、个性等,使 LLMs 能够更好地理解对话中的情感动态。
- 采用 两阶段学习(Two-Stage Learning) 来提升情感识别的精准度。
-
利用 LLMs 提取知识,提高 ERC 任务的性能:
- 第一阶段(说话人特征提取与注入):通过 LLMs 生成对话参与者的心理状态、行为等信息,并将其融入模型中。
- 第二阶段(情感识别):基于增强的特征信息,使用 LLMs 进行情感预测。
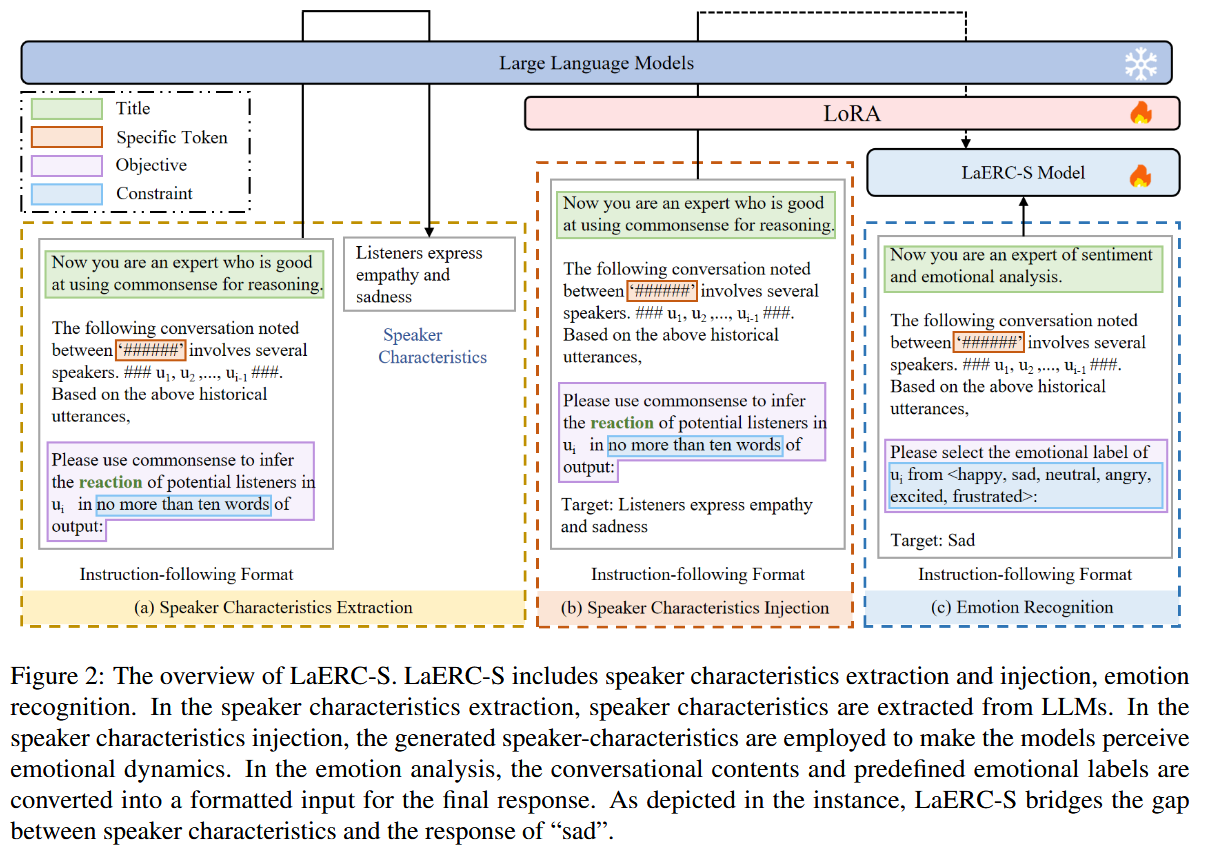
Figure 2 中 LaERC-S Model 与 LLM 的作用
Figure 2 展示了 LaERC-S 的整体流程,主要包括三个部分:
- 说话人特征提取(Speaker Characteristics Extraction)
- 说话人特征注入(Speaker Characteristics Injection)
- 情感识别(Emotion Recognition)
在这个过程中:
-
LLM 的作用:
- 在 说话人特征提取(第一阶段) 中,LLM 被用来生成说话人特征(如 oReact、xIntent、xEffect 等)。
- 这些特征反映了 对话中不同角色的情感状态、反应、行为,提供了更丰富的情感信息。
-
LaERC-S Model 的作用:
- 负责 特征注入(第二阶段) 和 情感识别。
- 通过 微调(fine-tuning) 使 LLMs 能够利用这些特征,提高情感分类的准确率。
- 在情感识别阶段,LaERC-S 采用一个 指令调优(Instruction-Tuning) 过程,使 LLMs 预测每个话语的情感标签(如“Happy”、“Sad”)。
总结:
- LLM 主要用于知识提取(知识生成),帮助获取说话人特征。
- LaERC-S Model 主要用于模型训练和预测,结合 LLMs 提取的信息进行情感分类,提高对话情感识别的准确性。
相关推荐