循环神经网络RNN、门控制单元GRU、长短期记忆网络LSTM原理及代码实现
循环神经网络RNN、门控制单元GRU、长短期记忆网络LSTM原理及代码实现
一、循环神经网络(RNN)
循环神经网络(RNN)是用来处理和生成数据序列的模型,广泛应用于自然语言处理、语音识别、时间序列分析等领域。序列模型的关键特性是它能够处理输入和输出之间的依赖关系,使模型能够理解数据在时间或序列上的顺序。
为了建模序列问题,RNN引入了隐状态h(hidden state)的概念,隐状态可以对序列的数据提取特征,接着再转换为输出。通过使用隐藏状态,我们就可以实现对序列数据的处理。
与传统神经网络不同的是,RNN可以支持不定长的输入。传统的神经网络的输入和输出通常都是固定长度的。例如输入图像大小固定,输出是分类结果,没有顺序相关的要求。但RNN可以支持不同长度的输入和输出,适应多种序列任务。
- 一对一(例如图像分类):一个输入对应一个输出。
- 一对多(例如图像描述生成):一个输入对应多个输出。
- 多对一(例如情感分析):多个输入对应一个输出。
- 多对多(例如机器翻译):多个输入对应多个输出。
1.1 单向循环神经网络
1.1.1 单向RNN结构
单向RNN的结构如图所示:
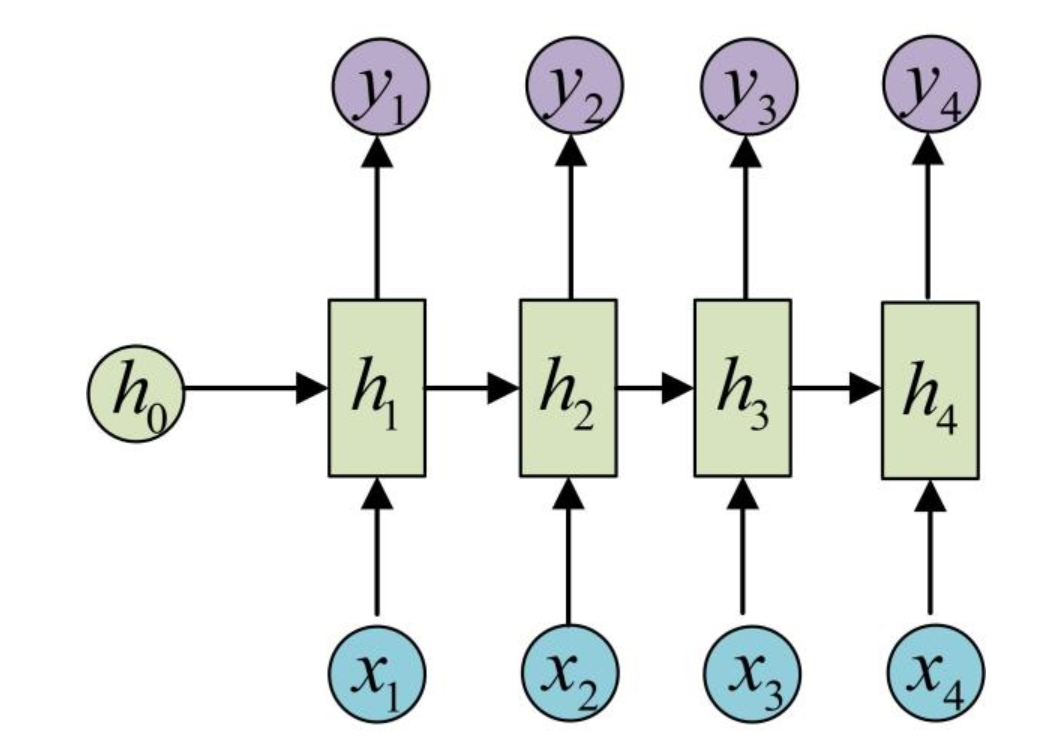
RNN的计算过程如下:
- 我们初始化一个隐藏状态矩阵,然后输入。
- 首先,和分别经过一个线性层得到,然后我们就可以根据得到第一个输出。
- 之后我们将和再分别经过一个线性层计算得到,然后我们就可以再根据计算得到。
- 以此类推
1.1.2 单向循环网络在Pytorch中的实现
在torch.nn中,RNN的实现原理如下:
其中:
- 是时间t时刻的隐藏状态。
- 是时间t时刻的输入。
- 是时间t-1时刻的隐藏状态。
- 和分别是输入和隐藏状态的权重矩阵。
- 和分别是输入和隐藏状态的偏置值。
- 是非线性激活函数,可以用代替。
RNN的参数有:
- input_size:输入的特征数量。
- hidden_size:隐藏层的特征数量。
- num_layers:RNN层的数量,num_layers=2表示用两个RNN层形成一个多层RNN,第二个RNN层的输入是第一个RNN层的输出。默认为1。
- nonlinearity:非线性函数,可以是“tanh”或“ReLu”。默认为“tanh”。
- bias:是否使用偏置值。默认为True。
- batch_first:决定输入和输出的格式。如果为True,那么我们的输入和输出张量的格式就是(batch,seq,feature),如果为False,那么我们的输入和输出张量的格式就是(seq,batch,feature)。默认为False。
- dropout:dropout参数。默认为0。
- bidirectional:是否为双向RNN。如果为True则表示使用双向RNN。如果是双向RNN,那么输出就是两倍的hidden_size。默认为False。
RNN的输入:
- input:当batch_first=False时输入形状为(,,),当batch_first=True时输入形状为(,,)。
- h_0:形状为(,,)。
其中: - = batch size
- = sequence length
- = 单向RNN时为1,双向RNN时为2
- = input_size
- = hidden_size
RNN的输出:
- output:当batch_first=False时输入形状为(,,),当batch_first=True时输入形状为(,,)。
- h_n:形状为(,,)。
RNN的权重和偏置矩阵:
- weight_ih_l[k]:第k层的输入权重矩阵。在K=0时形状为(hidden_size, input_size),否则形状为(hidden_size,num_directions*hidden_size)。
- weight_hh_l[k]:第k层的隐藏状态权重矩阵。形状为(hidden_size, hidden_size)。
- bias_ih_l[k]:第k层的输入偏置值矩阵。形状为(hidden_size)。
- bias_hh_l[k]:第k层的隐藏状态偏置值矩阵。形状为(hidden_size)。
代码实现如下:
1 | import torch |
1.1.3 手写单向RNN
1 | class MyRNN(nn.Module): |
1.2 双向循环网络
1.2.1 双向RNN结构
单向循环网络只能依据之前时刻的时序信息来预测下一时刻的输出,但在有些问题中,当前时刻的输出不仅和之前的状态有关,还可能与未来的状态有关。
比如要预测一句话中缺失的单词时,就需要同时考虑上下文的内容。
双向RNN有两个RNN上下叠加在一起组成,输出由这两个RNN的状态共同决定。
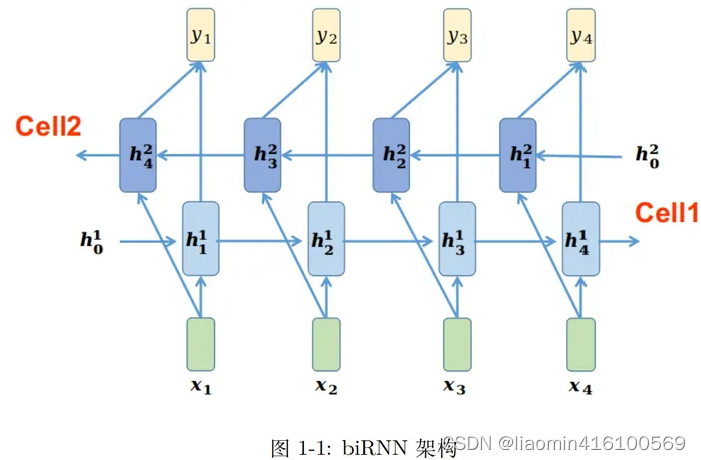
双向RNN的计算过程如下:
- 首先进行前向RNN,输入和,输出。
- 再根据和计算得到,以此类推进行完前向RNN。
- 当前向RNN完成后计算反向RNN,反向RNN有单独的隐藏层,且在反向RNN中输入input是反向输入的。
- 首先输入和计算得到,然后由和拼接得到最终输出的第一个输出(可以直接拼接也可以相加得到)。
- 再由和得到,由和拼接得到输出。
- 以此类推进行完反向RNN过程即可。
输入及输出分析:
- 输入:[]
- forward输出:[]
- backward输出:[]
- 最终输出隐藏状态序列h_out:[]
- 最终隐藏状态h_n:[]
1.2.2 双向循环网络在pytorch中的实现
使用pytorch实现双向RNN只需要改变传入RNN的参数bidirectional=True即可。
1 | import torch |
1.2.3 手写双向RNN
1 | import torch |
二、长短期记忆网络(LSTM)
传统的循环神经网络RNN虽然能够联系上下文的信息,但是RNN的梯度需要通过时间反向传播(Backpropagation Through Time)传播很长的时间步。当序列长度较大时,就会出现梯度消失或梯度爆炸的问题。这种问题可能会导致某些不太重要的信息对其后续信息的预测造成影响。
所以我们引入了“长短期记忆”(long-short-term memory, LSTM)和“门控循环单元”(gated recurrent unit,GRU)。
传统的RNN对于输入的重要性判断很固定,越早输入的越不重要,越晚输入的越重要,这显然存在一定的问题。而LSTM则是通过门控制的方式实现了对输入重要度的控制。
2.1 LSTM结构
原始的RNN隐藏状态只有一个,它对于短期输入非常敏感,所以我们的想法就是增加一个隐藏状态用来保存长期状态,我们把状态称为候选记忆单元,这就是LSTM。
LSTM的结构如下图:
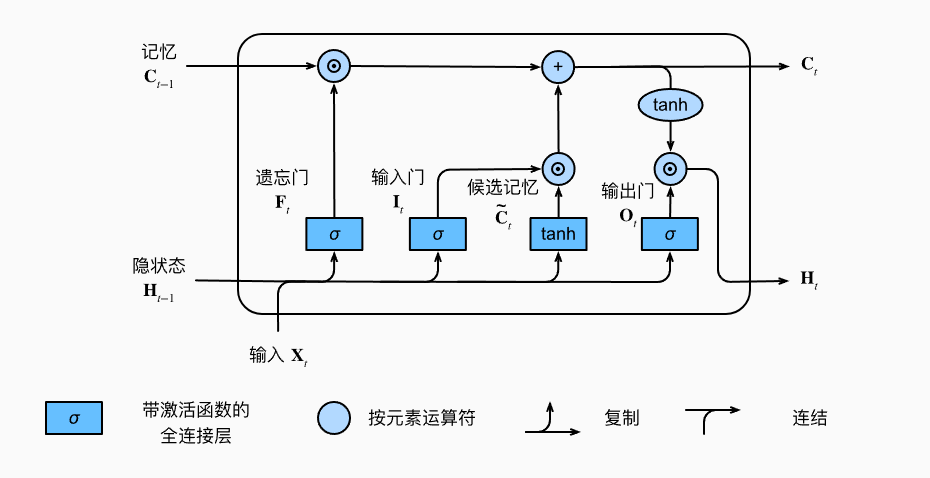
LSTM的公式如下:
LSTM中有三种门:是输入门,它控制使用多少来自候选记忆单元的数据,遗忘门控制保留多少过去的记忆元的内容,输出门用于决定当前时刻输出哪些信息。
公式中的激活函数(即sigmoid)和目的都是将输出限制在[0,1]之间。
2.2 手写LSTM
LSTM的实现与RNN类似,但是需要注意的是,因为我们在中都要实现和,所以我们可以将四个权重矩阵拼接到一起,然后只进行一次矩阵乘法运算即可。
1 | import torch |
三、门控循环单元(GRU)
GRU的实现原理与LSTM类似,只不过GRU对LSTM做了一些优化,减少了一些参数。
3.1 GRU结构
GRU通过引入重置门(reset gate)和更新门(update gate)来实现对重要度不同信息的控制。重置门控制前一时刻隐藏状态对当前时刻候选隐藏状态的影响程度,更新们控制上一时刻的隐藏状态()与当前候选隐藏状态()的混合程度,决定信息的保留和更新比例。
GRU的结构如下图:
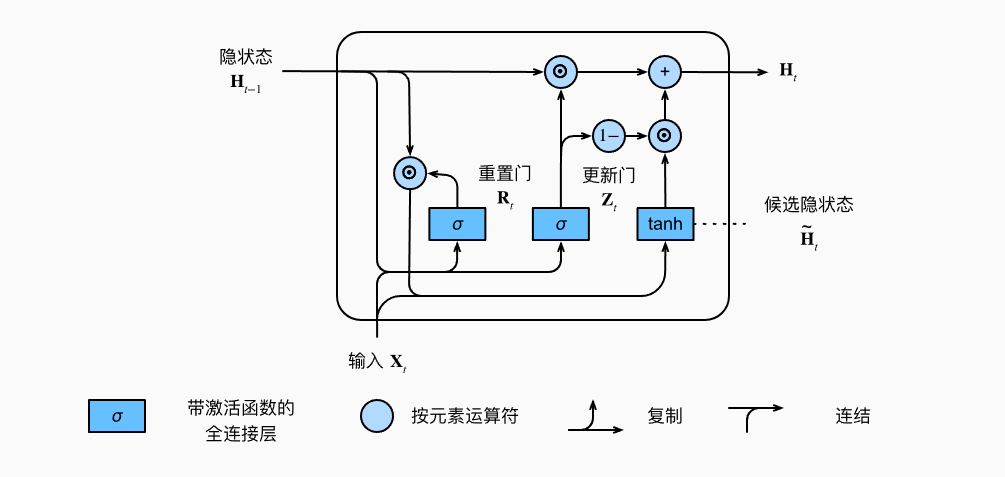
GRU的公式如下:
我们通过来计算候选隐藏状态,然后再根据控制候选隐藏状态与前一隐藏状态的比例,从而计算得到新的隐藏状态。
3.2 手写GRU
GRU的实现与LSTM非常类似,只不过参数变为了LSTM的:
1 | import torch |
参考资料:
[1] Pytorch官方文档
[2] PyTorch RNN的原理及其手写复现
[3] 如何从RNN起步,一步一步通俗理解LSTM
[4] 循环神经网络 RNN【动手学深度学习v2】
[5] 深度学习05-RNN循环神经网络