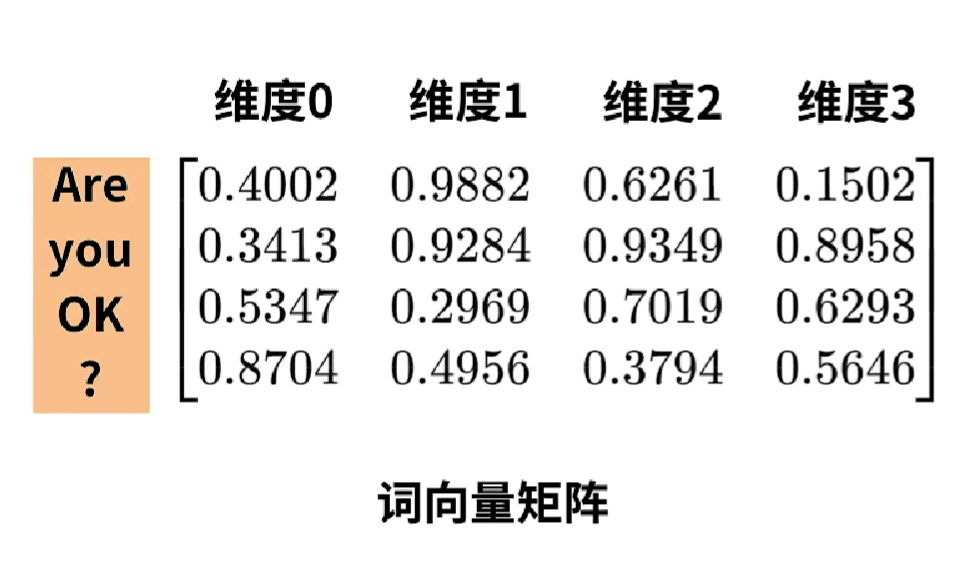
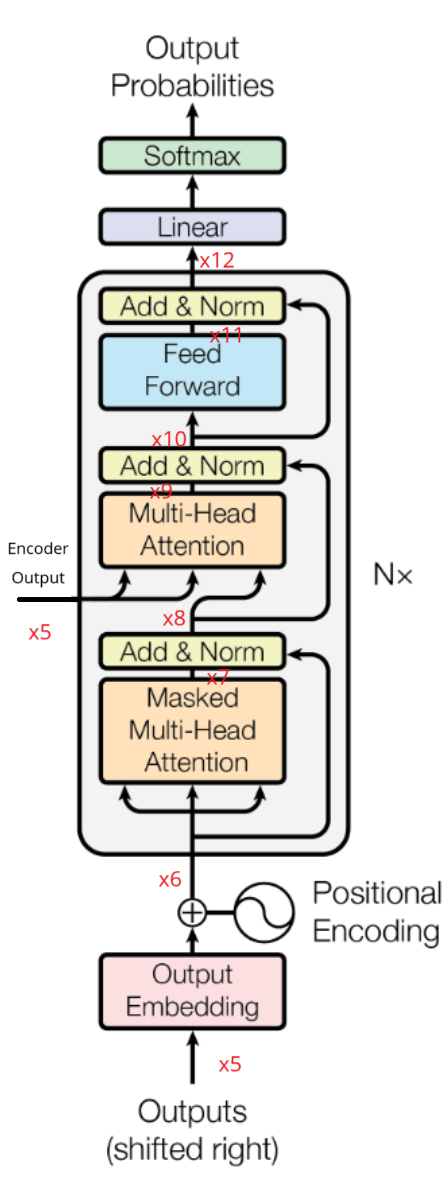
Tansformer
一、Transformer简介
Transformer 是一种深度学习模型架构,主要用于处理序列数据,比如自然语言处理(NLP)中的文本序列任务。它由 Google 研究团队在 2017 年提出,并在论文《Attention Is All You Need》中正式发布。Transformer 的关键创新在于自注意力机制 ,通过它,模型能够捕捉序列中每个位置之间的依赖关系,而不需要传统的递归(RNN)或卷积(CNN)结构。
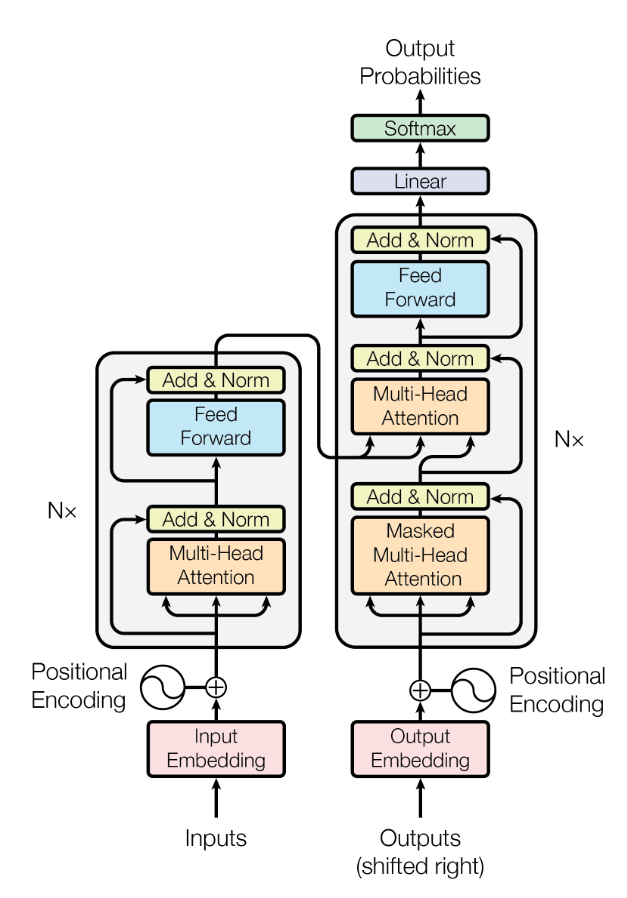
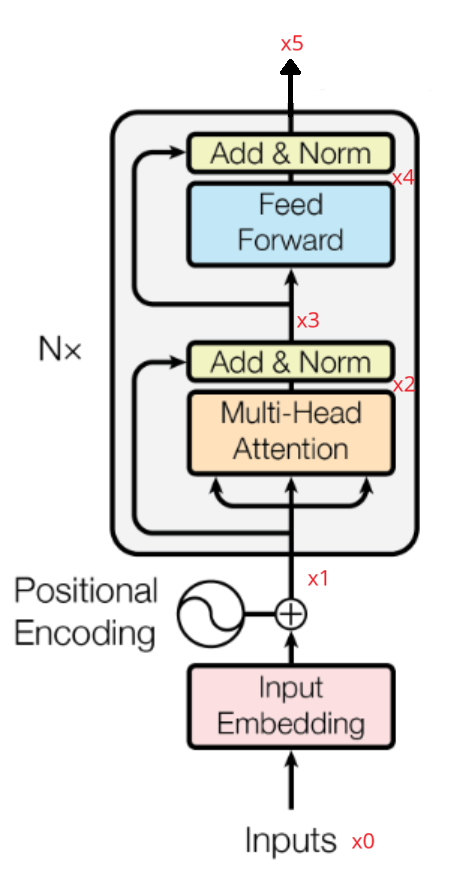
Transformer 主要由 Encoder 和 Decoder 两个模块组成:
Encoder :用于处理输入序列,比如输入文本。一个 Transformer 通常包含多个 Encoder 层堆叠,每层的 Encoder 会计算序列中每个词与其他词的关系,提取特征并捕捉依赖关系。Encoder 的输出可以作为 Decoder 的输入。
Decoder :用于生成目标序列,比如翻译任务中的输出文本。Decoder 也由多个层堆叠而成,负责在给定输入编码的情况下生成输出,同时自我监督生成的内容,确保输出的每个词不会看到未来的词。
自注意力机制 (Self-Attention Mechanism):
多头注意力 (Multi-Head Attention):
位置编码 (Positional Encoding):
并行化计算 :
由于其强大的序列建模能力和并行化特性,Transformer 已经广泛应用于 NLP 和其他领域,包括:
机器翻译 :将一个语言的句子翻译成另一种语言。文本生成 :如自动写作、摘要生成和对话系统。图像处理 :ViT(Vision Transformer)应用 Transformer 架构进行图像分类和生成。推荐系统 :利用用户的行为序列进行兴趣预测和推荐内容。
Transformer结构如下图所示:
二、注意力机制(Attention)
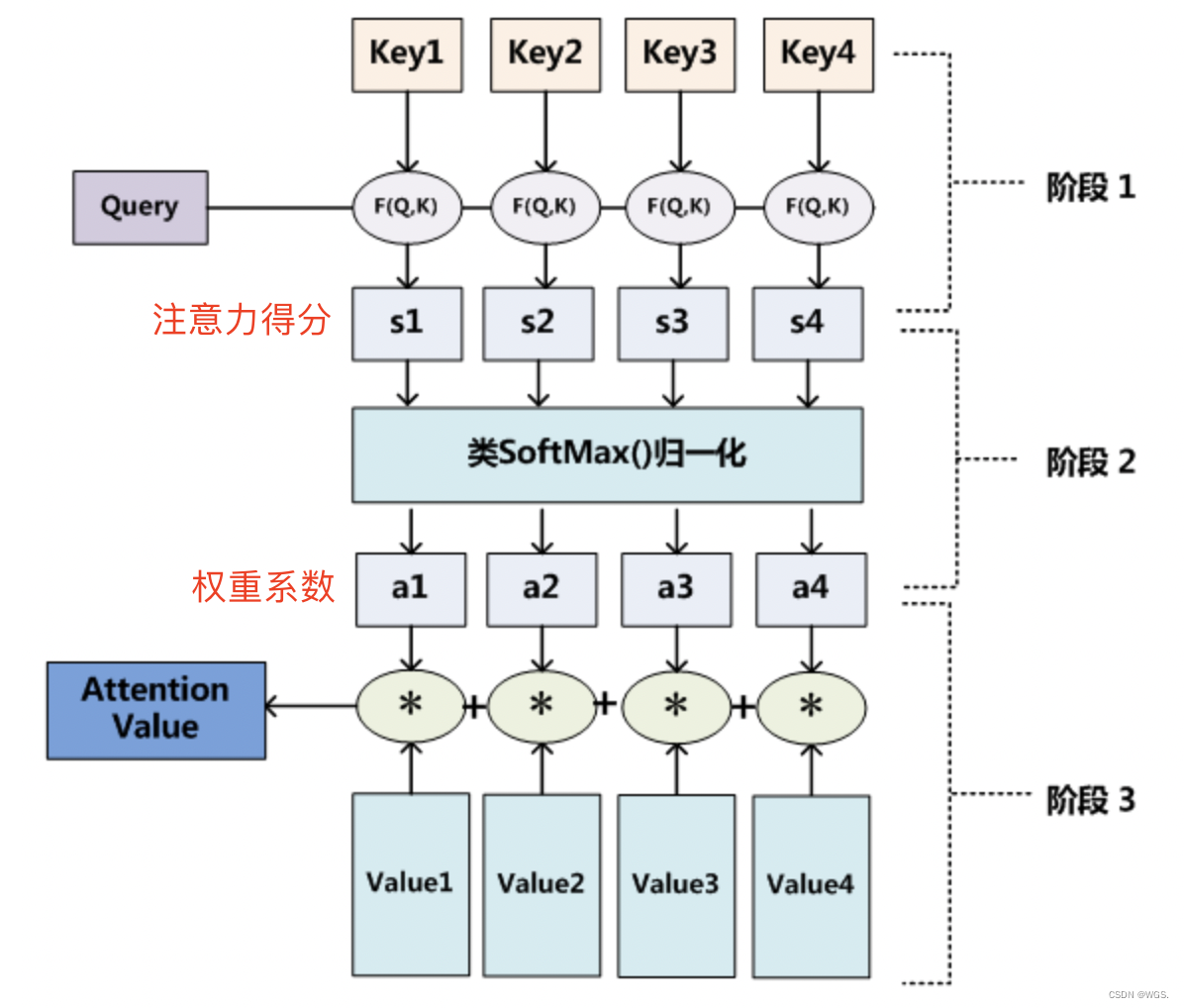
2.1 注意力机制(attention)
在讲自注意力机制之前,我们先来看一下什么是注意力机制。
C 汤姆 = g ( 0.6 ∗ f 2 ( T o m ) , 0.2 ∗ f 2 ( c h a s e ) , 0.2 ∗ f 2 ( J e r r y ) ) C 追逐 = g ( 0.2 ∗ f 2 ( T o m ) , 0.7 ∗ f 2 ( c h a s e ) , 0.1 ∗ f 2 ( J e r r y ) ) C 杰瑞 = g ( 0.3 ∗ f 2 ( T o m ) , 0.2 ∗ f 2 ( c h a s e ) , 0.5 ∗ f 2 ( J e r r y ) ) C_{汤姆} = g(0.6∗f_2(Tom),0.2∗f_2(chase),0.2∗f_2(Jerry)) \\
C_{追逐} = g(0.2∗f_2(Tom),0.7∗f_2(chase),0.1∗f_2(Jerry)) \\
C_{杰瑞} = g(0.3∗f_2(Tom),0.2∗f_2(chase),0.5∗f_2(Jerry))
C 汤姆 = g ( 0.6 ∗ f 2 ( T o m ) , 0.2 ∗ f 2 ( c ha se ) , 0.2 ∗ f 2 ( J erry )) C 追逐 = g ( 0.2 ∗ f 2 ( T o m ) , 0.7 ∗ f 2 ( c ha se ) , 0.1 ∗ f 2 ( J erry )) C 杰瑞 = g ( 0.3 ∗ f 2 ( T o m ) , 0.2 ∗ f 2 ( c ha se ) , 0.5 ∗ f 2 ( J erry ))
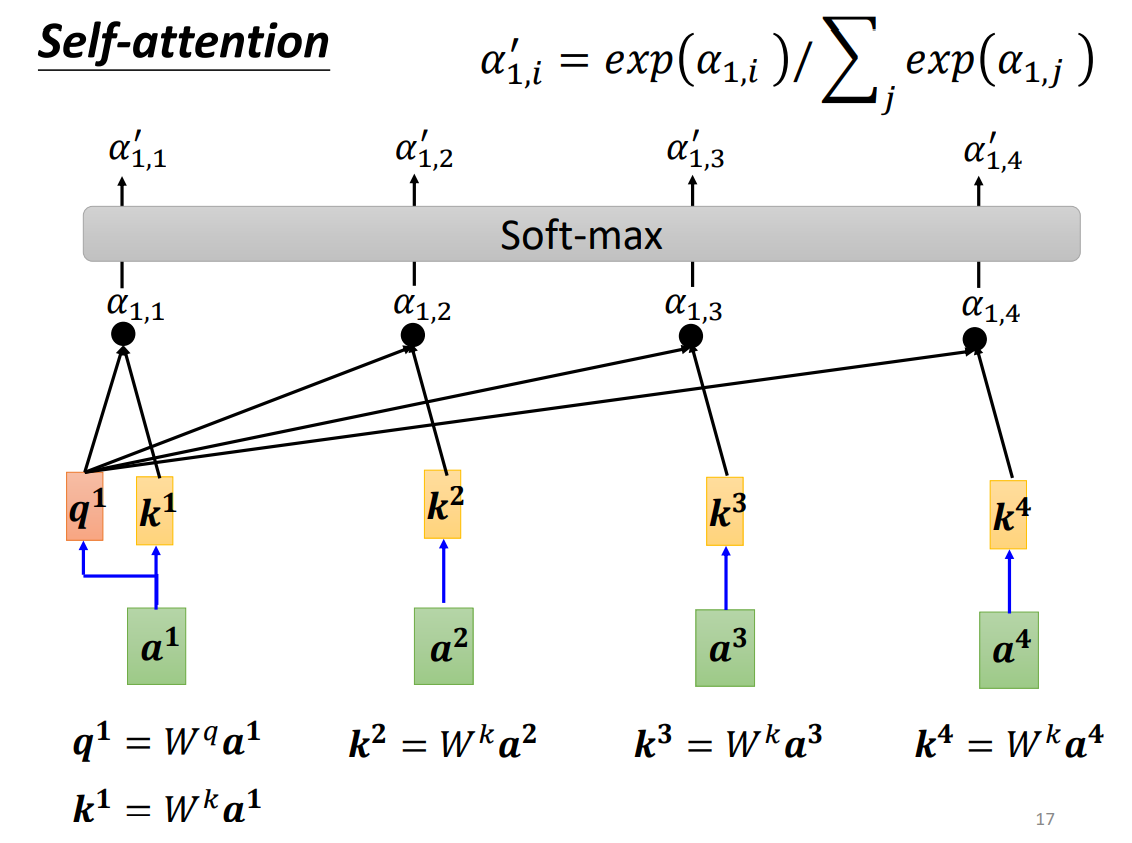
2.2 自注意力机制(self-attention)
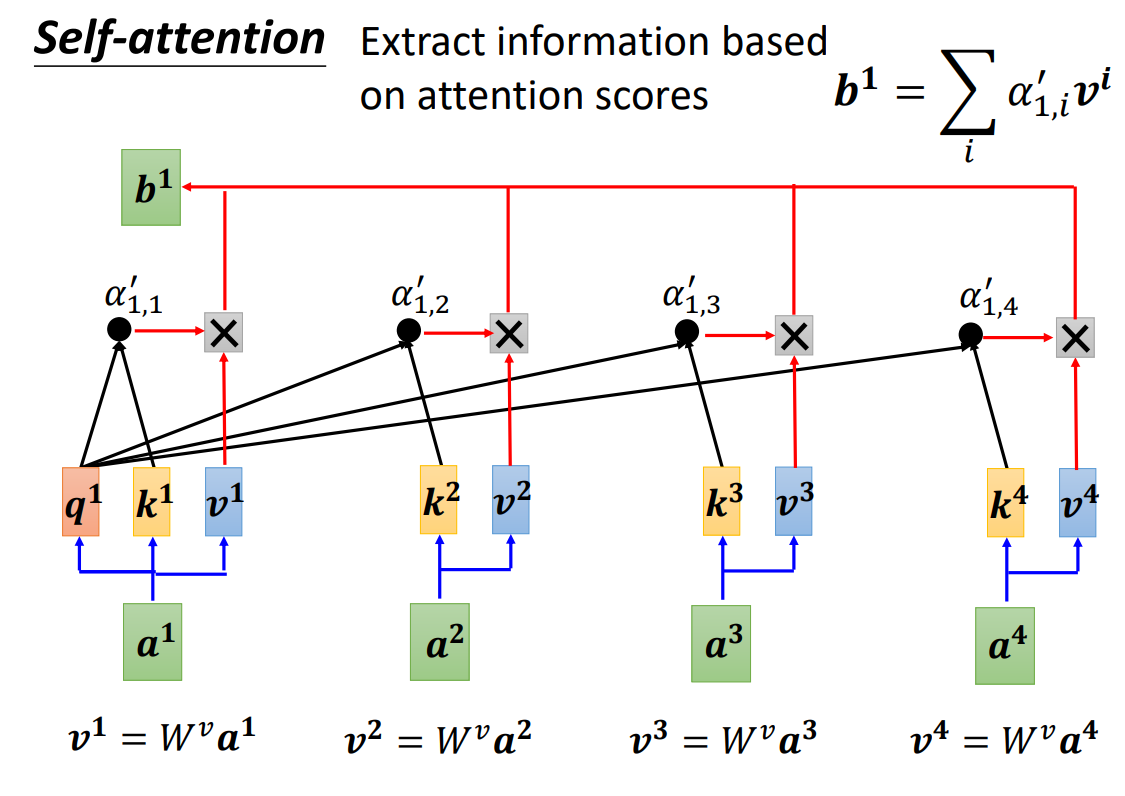
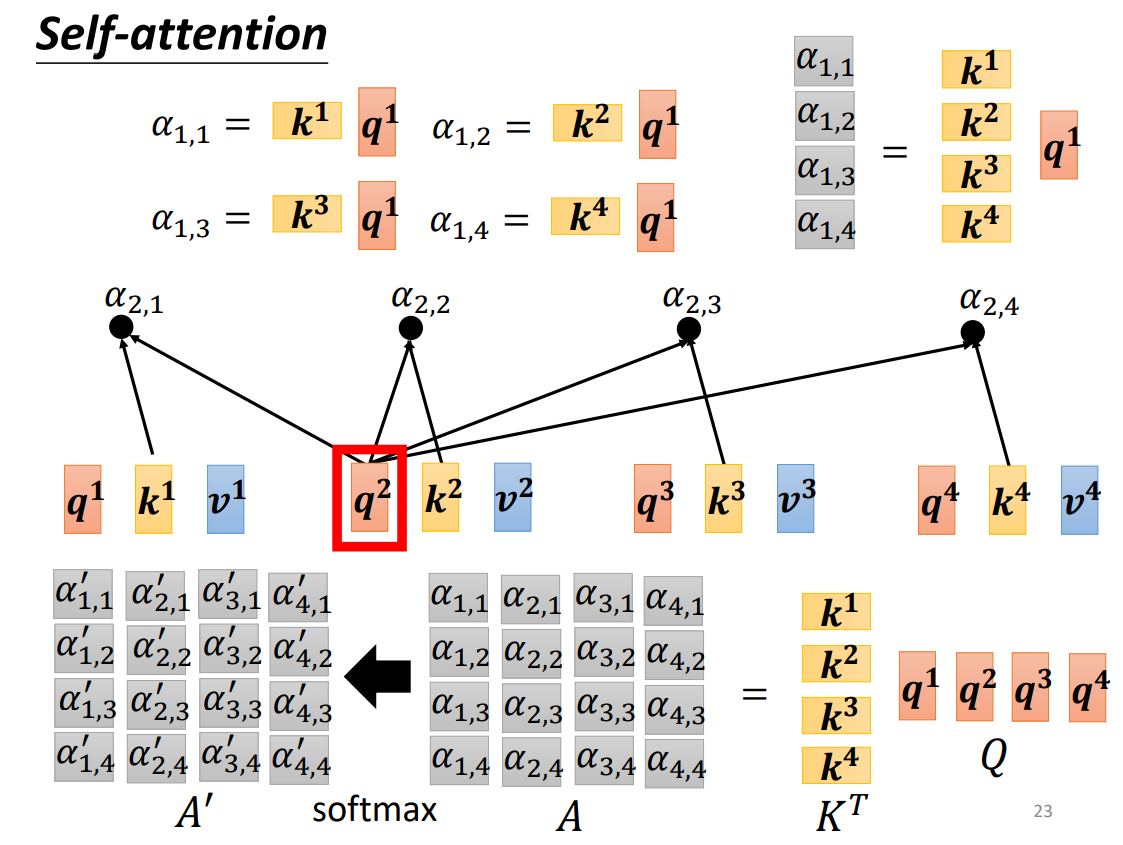
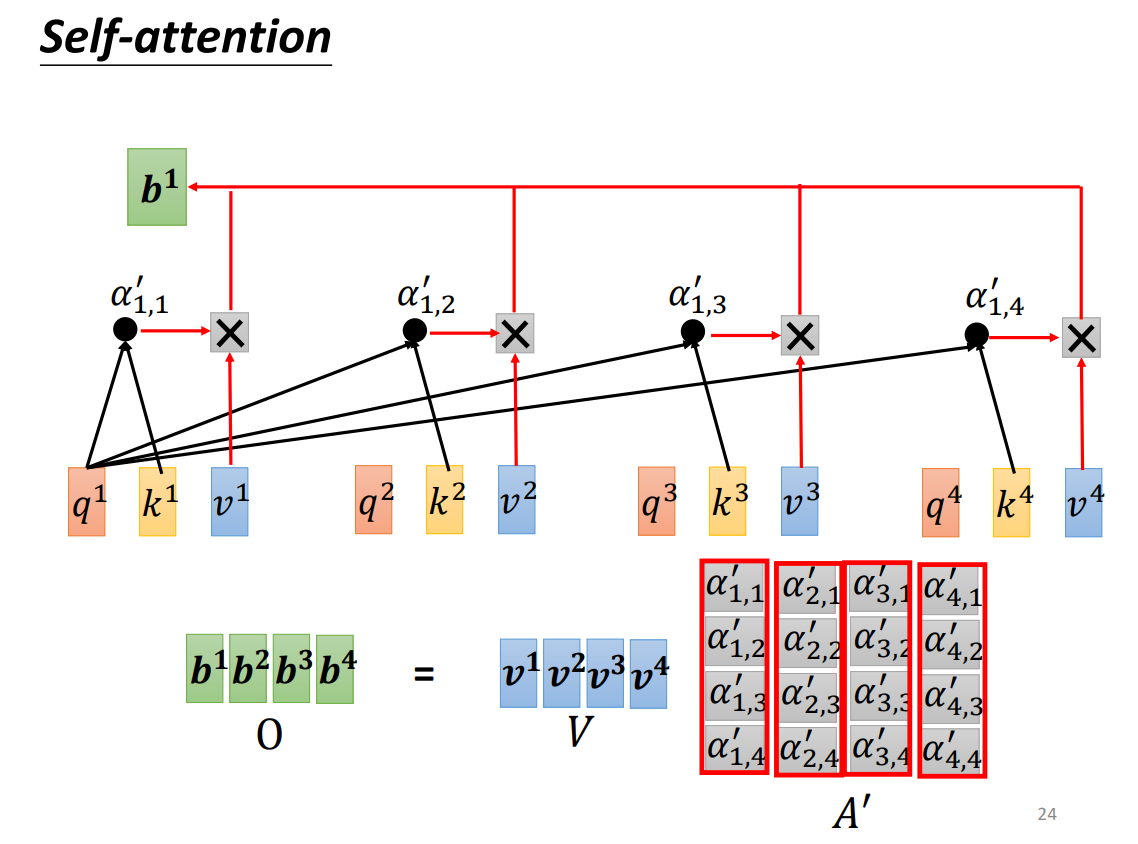
在实现注意力机制前,我们一般引入三个参数:query、key、value。a 1 , a 2 , a 3 , a 4 a^1,a^2,a^3,a^4 a 1 , a 2 , a 3 , a 4 W q W^q W q a 1 a^1 a 1 q 1 q^1 q 1 a 1 a^1 a 1 W k W^k W k a 1 , a 2 , a 3 , a 4 a^1,a^2,a^3,a^4 a 1 , a 2 , a 3 , a 4 k 1 , k 2 , k 3 , k 4 k^1,k^2,k^3,k^4 k 1 , k 2 , k 3 , k 4 q 1 q^1 q 1 k 2 , k 3 , k 4 k^2,k^3,k^4 k 2 , k 3 , k 4 α 1 , 2 , α 1 , 3 , α 1 , 4 \alpha_{1,2},\alpha_{1,3},\alpha_{1,4} α 1 , 2 , α 1 , 3 , α 1 , 4 α 1 , i ′ \alpha_{1,i}' α 1 , i ′ b 1 = ∑ i α 1 , i ′ v i b^1 = \sum_i\alpha_{1,i}'v^i b 1 = ∑ i α 1 , i ′ v i v i = W i a i v^i=W^ia_i v i = W i a i
我们将q 1 q 2 q 3 q 4 q^1q^2q^3q^4 q 1 q 2 q 3 q 4 Q Q Q k 1 k 2 k 3 k 4 k^1k^2k^3k^4 k 1 k 2 k 3 k 4 K K K v 1 v 2 v 3 v 4 v^1v^2v^3v^4 v 1 v 2 v 3 v 4 V V V K T K^T K T Q Q Q A A A A ′ A' A ′ A ′ A' A ′ V V V O O O
O = s o f t m a x ( Q K T ) V O = softmax(QK^T)V
O = so f t ma x ( Q K T ) V
一般情况下,我们为了让梯度更稳定,还会除以key向量的维数的平方根,所以最后的公式表示为:
O = s o f t m a x ( Q K T d k ) V O = softmax(\frac{QK^T}{\sqrt{d_k}})V
O = so f t ma x ( d k Q K T ) V
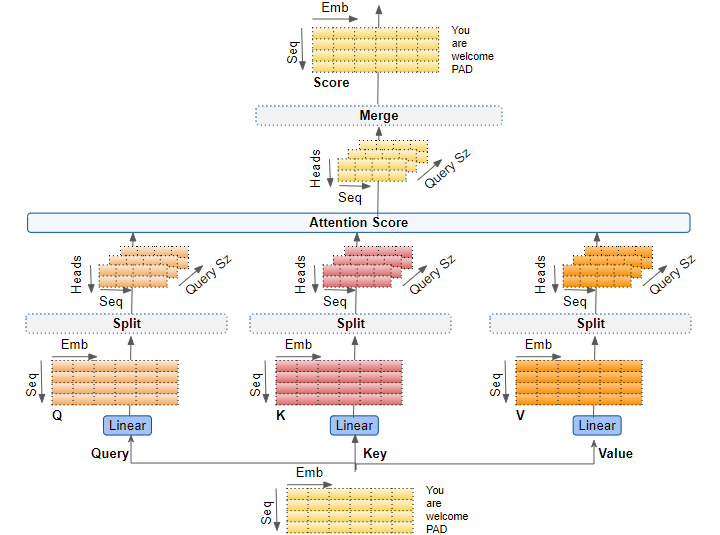
2.3 多头注意力机制(multi-head attention)
多头注意力机制是在自注意力机制的基础上,通过增加多个注意力头来并行地对输入信息进行不同维度的注意力分配,从而捕获更丰富的特征和上下文。
输入嵌入 :给定一个输入X X X
线性变换 :我们将输入分别经过三个不同的线性层,即进行线性变换,得到查询(Query)、键(Key)和值(Value)矩阵:
Q = X W Q , K = X W K , V = X W V Q = XW_Q, K = XW_K, V = XW_V
Q = X W Q , K = X W K , V = X W V
其中:W Q 、 W K 、 W V W_Q、W_K、W_V W Q 、 W K 、 W V
多头分割 :将Q 、 K 、 V Q、K、V Q 、 K 、 V h h h
计算每个头的注意力 :对于每个头i i i
h e a d i = A t t e n t i o n i ( Q i , K i , V i ) = s o f t m a x ( Q i K i T d k ) V i head_i = Attention_i(Q_i,K_i,V_i) = softmax(\frac{Q_iK_i^T}{\sqrt{d_k}})V_i
h e a d i = A tt e n t i o n i ( Q i , K i , V i ) = so f t ma x ( d k Q i K i T ) V i
拼接头部 :将所有头的注意力输出拼接起来形成一个新的矩阵:
M u l t i H e a d ( Q , K , V ) = C o n c a t ( h e a d 1 , h e a d 2 , . . . , h e a d n ) W O MultiHead(Q,K,V) = Concat(head_1,head_2,...,head_n)W_O
M u lt i He a d ( Q , K , V ) = C o n c a t ( h e a d 1 , h e a d 2 , ... , h e a d n ) W O
其中:W O W_O W O
输出 :最终的多注意力输出回座位后续层的输入。
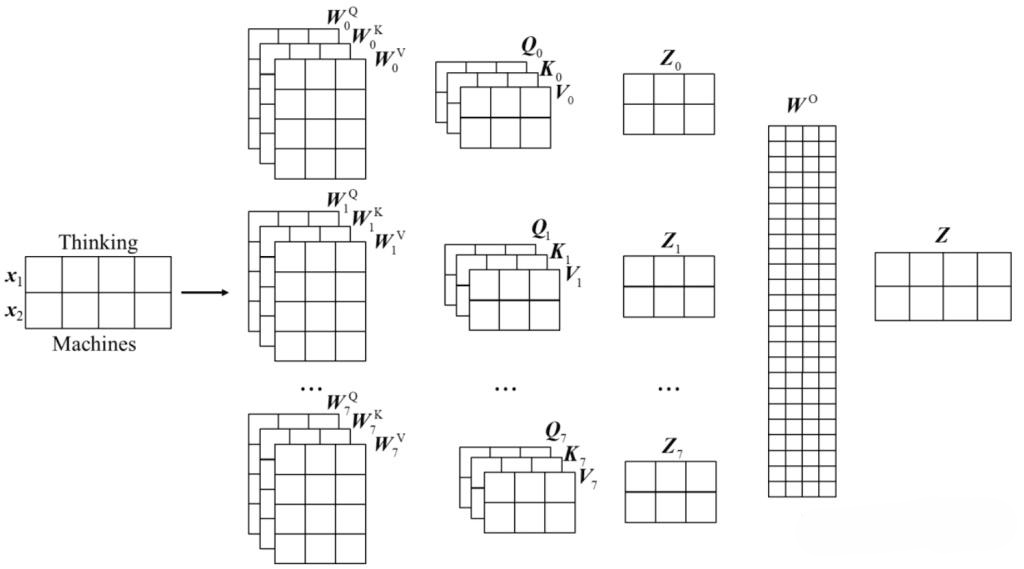
还有一种多头的实现方法不是将矩阵拆分,而是进行多次线性变换从而实现多头,过程如下图所示:
2.4 多头注意力机制的代码实现
多头注意力机制的代码实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 import torchfrom torch import nnimport mathimport torch.nn.functional as Fclass MultiheadAttention (nn.Module): def __init__ (self, model_dim, num_head ) -> None : super (MultiheadAttention, self).__init__() self.model_dim = model_dim self.num_head = num_head self.w_q = nn.Linear(model_dim, model_dim) self.w_k = nn.Linear(model_dim, model_dim) self.w_v = nn.Linear(model_dim, model_dim) self.o = nn.Linear(model_dim, model_dim) self.softmax = nn.Softmax(dim=-1 ) def forward (self, q, k, v, mask=None ): batch, seq_len, dimension = q.shape head_dim = self.model_dim // self.num_head Q = self.w_q(q) K = self.w_k(k) V = self.w_v(v) Q = Q.view(batch, seq_len, self.num_head, head_dim).permute(0 , 2 , 1 , 3 ) K = K.view(batch, seq_len, self.num_head, head_dim).permute(0 , 2 , 1 , 3 ) V = V.view(batch, seq_len, self.num_head, head_dim).permute(0 , 2 , 1 , 3 ) scores = Q @ K.transpose(2 , 3 ) / math.sqrt(head_dim) if mask is not None : scores = scores.masked_fill(mask == 0 , -1e9 ) scores = self.softmax(scores) @ V scores = scores.permute(0 , 2 , 1 , 3 ).contiguous().view(batch, seq_len, dimension) output = self.o(scores) return output if __name__ == '__main__' : model_dim = 512 num_head = 8 attention = MultiheadAttention(model_dim, num_head) x = torch.rand(128 , 64 , 512 ) output = attention(x, x, x) print (output, output.shape)
三、位置编码(Positional Encoding)
3.1 位置编码原理
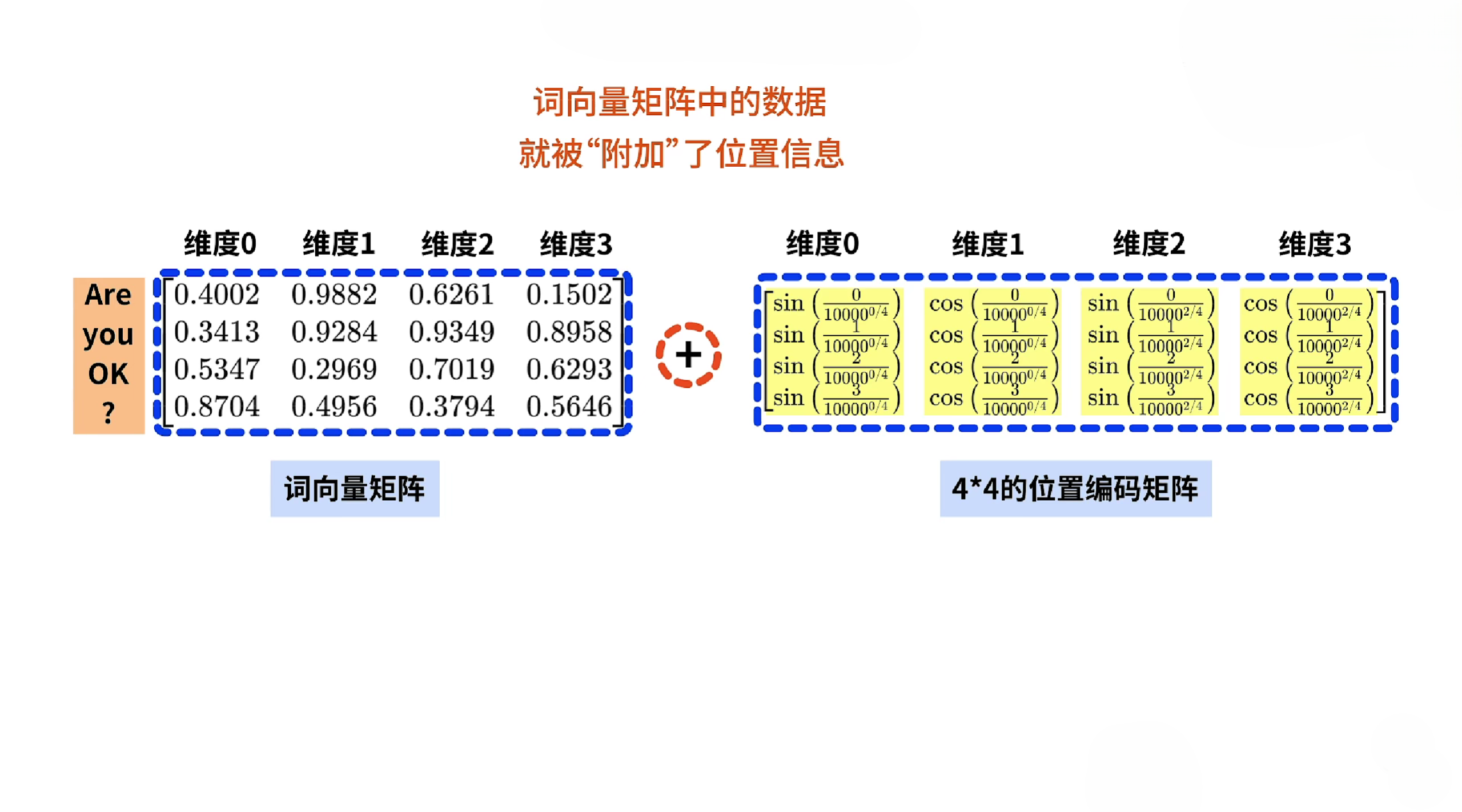
位置编码也是transformer的特色之一。在Transformer以前,NLP任务中有一个很大的问题,那就是模型没有办法知道每个token在句子中的绝对和相对位置信息,比如对于这两个句子:“Tom chase Jerry”和"Jerry chase Tom",它们的token完全一样,但是含义完全相反。p o s pos p os i i i
P E ( p o s , 2 i ) = s i n ( p o s 10000 2 i d m o d e l ) P E ( p o s , 2 i + 1 ) = c o s ( p o s 10000 2 i d m o d e l ) PE_{(pos,2i)} = sin(\frac{pos}{10000^{\frac{2i}{d_{model}}}}) \newline
PE_{(pos,2i+1)} = cos(\frac{pos}{10000^{\frac{2i}{d_{model}}}})
P E ( p os , 2 i ) = s in ( 1000 0 d m o d e l 2 i p os ) P E ( p os , 2 i + 1 ) = cos ( 1000 0 d m o d e l 2 i p os )
其中:p o s pos p os i i i d m o d e l d_{model} d m o d e l ( p o s = 0 , d = 4 ) (pos=0,d=4) ( p os = 0 , d = 4 )
P E ( 0 , 0 ) = s i n ( 0 10000 0 4 ) P E ( 0 , 1 ) = c o s ( 0 10000 0 4 ) P E ( 0 , 2 ) = s i n ( 0 10000 2 4 ) P E ( 0 , 3 ) = c o s ( 0 10000 2 4 ) PE_{(0,0)} = sin(\frac{0}{10000^{\frac{0}{4}}}) \\
PE_{(0,1)} = cos(\frac{0}{10000^{\frac{0}{4}}}) \\
PE_{(0,2)} = sin(\frac{0}{10000^{\frac{2}{4}}}) \\
PE_{(0,3)} = cos(\frac{0}{10000^{\frac{2}{4}}}) \\
P E ( 0 , 0 ) = s in ( 1000 0 4 0 0 ) P E ( 0 , 1 ) = cos ( 1000 0 4 0 0 ) P E ( 0 , 2 ) = s in ( 1000 0 4 2 0 ) P E ( 0 , 3 ) = cos ( 1000 0 4 2 0 )
最终我们会将得到的位置编码矩阵与词向量矩阵相加,从而得到嵌入位置编码的词向量矩阵:p o s pos p os
3.2 位置原理的代码实现
位置编码的代码实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 class TokenEmbedding (nn.Embedding): def __init__ (self, vocab_size, model_dim ): super (TokenEmbedding, self).__init__(vocab_size, model_dim, padding_idx=1 ) class PositionEmbedding (nn.Module): def __init__ (self, model_dim, maxlen, device ): super (PositionEmbedding, self).__init__() self.encodeing = torch.zeros(maxlen, model_dim, device=device) self.encodeing.requires_grad_(False ) pos = torch.arange(0 , maxlen, device=device) pos = pos.float ().unsqueeze(1 ) _2i = torch.arange(0 , model_dim, 2 , device=device) self.encodeing[:, 0 ::2 ] = torch.sin(pos / (10000 ** (_2i / model_dim))) self.encodeing[:, 1 ::2 ] = torch.cos(pos / (10000 ** (_2i / model_dim))) def forward (self, x ): seq_len = x.shape[1 ] return self.encodeing[:seq_len, :] class TransformerEmbedding (nn.Module): def __init__ (self, model_dim, vocab_size, maxlen, drop_prob, device ): super (TransformerEmbedding, self).__init__() self.tok_emb = TokenEmbedding(vocab_size, model_dim) self.pos_emb = PositionEmbedding(model_dim, maxlen, device=device) self.drop_out = nn.Dropout(p=drop_prob) def forward (self, x ): tok_emb = self.tok_emb(x) pos_emb = self.pos_emb(x) out = self.drop_out(tok_emb + pos_emb) return out
四、前馈神经网络层(Feed-Forward Network)
4.1 前馈神经网络(Feed-Forward Network)原理
在Transformer中,每次经过attention层后,都会再经过一个前馈神经网络层(FFN),其作用是对每个位置的注意力输出进一步进行的特征转换和非线性映射,以增强模型的表达能力。
F F N ( x ) = m a x ( 0 , x W 1 + b 1 ) W 2 + b 2 FFN(x) = max(0,xW_1+b_1)W_2+b_2
FFN ( x ) = ma x ( 0 , x W 1 + b 1 ) W 2 + b 2
其中:W 1 W_1 W 1 W 2 W_2 W 2 b 1 b_1 b 1 b 2 b_2 b 2
4.2 前馈神经网络的代码实现
前馈神经网络层的代码实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class PositionwiseFeedForward (nn.Module): def __init__ (self, model_dim, hidden, dropout=0.1 ): super (PositionwiseFeedForward, self).__init__() self.fc1 = nn.Linear(model_dim, hidden) self.fc2 = nn.Linear(hidden, model_dim) self.dropout = nn.Dropout(dropout) def forward (self, x ): x = self.fc1(x) x = F.relu(x) x = self.dropout(x) x = self.fc2(x) return x
五、Mask机制(Mask)
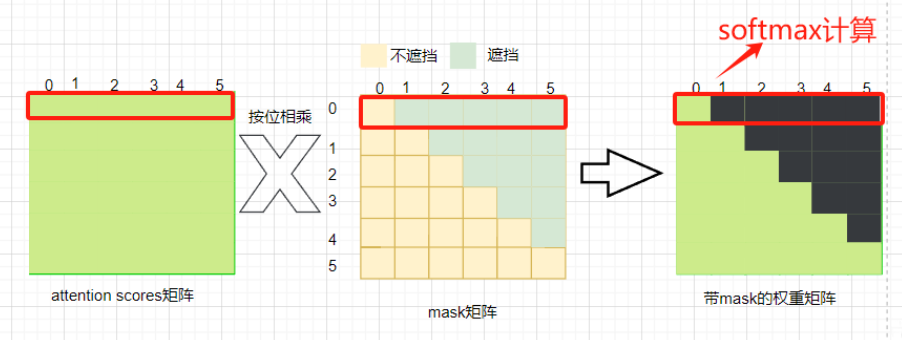
在Transformer模型中,Encoder和Decoder的mask矩阵用于不同的目的,它们限制了模型在自注意力(self-attention)计算时可以看到哪些信息。
5.1 Encoder中的Mask
在模型训练过程中,我们每次会输入多个句子,但这些句子的长度很可能不一致,所以为了使每个句子的长度都保持一致,我们会对句子编码进行填充padding,从而使得所有句子长度一致。− ∞ -\infty − ∞
5.2 Decoder中的Mask
在Decoder中,需要两种mask:Look-ahead Mask和Padding Mask。
5.3 生成Mask矩阵的代码实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 def make_pad_mask (self, q, k, pad_idx_q, pad_idx_k ): len_q, len_k = q.size(1 ), k.size(1 ) q = q.ne(pad_idx_q).unsqueeze(1 ).unsqueeze(3 ) q = q.repeat(1 , 1 , 1 ,len_k) k = k.ne(pad_idx_k).unsqueeze(1 ).unsqueeze(2 ) k = k.repeat(1 , 1 , len_q, 1 ) mask = q & k return mask def make_casual_mask (self, q, k ): len_q, len_k = q.size(1 ), k.size(1 ) mask = torch.tril(torch.ones(len_q, len_k)).type (torch.BoolTensor).to(self.device) return mask
六、Transformer编码器(Transformer Encoder)
6.1 Encoder的结构
Transformer的编码器结构如下:
我们的输入x 0 x_0 x 0 x 1 x_1 x 1
x 1 x_1 x 1 x 2 x_2 x 2 之后x 2 x_2 x 2 x 1 x_1 x 1 x 3 x_3 x 3
接着x 3 x_3 x 3 x 4 x_4 x 4
x 4 x_4 x 4 x 3 x_3 x 3 x 5 x_5 x 5 之后x 5 x_5 x 5
6.2 Encoder的代码实现
具体代码实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 import torchfrom torch import nnimport mathimport torch.nn.functional as Ffrom multi_head_attention import MultiheadAttentionclass TokenEmbedding (nn.Embedding): def __init__ (self, vocab_size, model_dim ): super (TokenEmbedding, self).__init__(vocab_size, model_dim, padding_idx=1 ) class PositionEmbedding (nn.Module): def __init__ (self, model_dim, maxlen, device ): super (PositionEmbedding, self).__init__() self.encodeing = torch.zeros(maxlen, model_dim, device=device) self.encodeing.requires_grad_(False ) pos = torch.arange(0 , maxlen, device=device) pos = pos.float ().unsqueeze(1 ) _2i = torch.arange(0 , model_dim, 2 , device=device) self.encodeing[:, 0 ::2 ] = torch.sin(pos / (10000 ** (_2i / model_dim))) self.encodeing[:, 1 ::2 ] = torch.cos(pos / (10000 ** (_2i / model_dim))) def forward (self, x ): seq_len = x.shape[1 ] return self.encodeing[:seq_len, :] class TransformerEmbedding (nn.Module): def __init__ (self, model_dim, vocab_size, maxlen, drop_prob, device ): super (TransformerEmbedding, self).__init__() self.tok_emb = TokenEmbedding(vocab_size, model_dim) self.pos_emb = PositionEmbedding(model_dim, maxlen, device=device) self.drop_out = nn.Dropout(p=drop_prob) def forward (self, x ): tok_emb = self.tok_emb(x) pos_emb = self.pos_emb(x) out = self.drop_out(tok_emb + pos_emb) return out class LayerNorm (nn.Module): def __init__ (self, model_dim, eps=1e-10 ): super (LayerNorm, self).__init__() self.gamma = nn.Parameter(torch.ones(model_dim)) self.beta = nn.Parameter(torch.zeros(model_dim)) self.eps = eps def forward (self, x ): mean = x.mean(-1 , keepdim=True ) var = x.var(-1 , unbiased=False , keepdim=True ) out = (x - mean) / torch.sqrt(var + self.eps) out = self.gamma * out + self.beta return out class PositionwiseFeedForward (nn.Module): def __init__ (self, model_dim, hidden, dropout=0.1 ): super (PositionwiseFeedForward, self).__init__() self.fc1 = nn.Linear(model_dim, hidden) self.fc2 = nn.Linear(hidden, model_dim) self.dropout = nn.Dropout(dropout) def forward (self, x ): x = self.fc1(x) x = F.relu(x) x = self.dropout(x) x = self.fc2(x) return x class EncoderLayer (nn.Module): def __init__ (self, model_dim, num_head, hidden, drop_prob ): super (EncoderLayer, self).__init__() self.attention = MultiheadAttention(model_dim, num_head) self.norm1 = LayerNorm(model_dim) self.drop1 = nn.Dropout(drop_prob) self.ffn = PositionwiseFeedForward(model_dim, hidden, drop_prob) self.norm2 = LayerNorm(model_dim) self.drop2 = nn.Dropout(drop_prob) def forward (self, x, mask=None ): _x = x x = self.attention(x, x, x, mask) x = self.drop1(x) x = self.norm1(x + _x) _x = x x = self.ffn(x) x = self.drop2(x) x = self.norm2(x + _x) return x
七、Transformer解码器(Transformer Decoder)
7.1 Deconder的结构
Transformer解码器的结构如下:
我们由Encoder得到的输出x 5 x_5 x 5 x 6 x_6 x 6
x 6 x_6 x 6 x 7 x_7 x 7 x 7 x_7 x 7 x 6 x_6 x 6 x 8 x_8 x 8 之后x 8 x_8 x 8 x 5 x_5 x 5 x 9 x_9 x 9
x 9 x_9 x 9 x 8 x_8 x 8 x 1 0 x_10 x 1 0 x 1 0 x_10 x 1 0 x 1 1 x_11 x 1 1 x 1 1 x_11 x 1 1 x 1 0 x_10 x 1 0 x 1 2 x_12 x 1 2 之后x 1 2 x_12 x 1 2
7.2 Decoder的代码实现
具体实现代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 import torchfrom torch import nnimport mathimport torch.nn.functional as Ffrom multi_head_attention import MultiheadAttentionfrom transformer_encoder import *class DecoderLayer (nn.Module): def __init__ (self, model_dim, hidden, num_head, drop_prob ): super (DecoderLayer, self).__init__() self.attention1 = MultiheadAttention(model_dim, num_head) self.norm1 = LayerNorm(model_dim) self.drop1 = nn.Dropout(drop_prob) self.cross_attention = MultiheadAttention(model_dim, num_head) self.norm2 = LayerNorm(model_dim) self.drop2 = nn.Dropout(drop_prob) self.ffn = PositionwiseFeedForward(model_dim, hidden, drop_prob) self.norm3 = LayerNorm(model_dim) self.drop3 = nn.Dropout(drop_prob) def forward (self, dec, enc, t_mask, s_mask ): _x = dec x = self.attention1(dec, dec, dec, t_mask) x = self.drop1(x) x = self.norm1(x + _x) if enc is not None : _x = x x = self.cross_attention(x, enc, enc, s_mask) x = self.drop2(x) x = self.norm2(x + _x) _x = x x = self.ffn(x) x = self.drop3(x) x = self.norm3(x + _x) return x class Decoder (nn.Module): def __init__ (self, model_dim, dec_voc_size, maxlen, hidden, num_head, n_layer, drop_prob, device ): super (Decoder, self).__init__() self.embedding = TransformerEmbedding(model_dim, dec_voc_size, maxlen, drop_prob, device=device) self.layers = nn.ModuleList( [DecoderLayer(model_dim, hidden, num_head, drop_prob) for _ in range (n_layer)] ) self.fc = nn.Linear(model_dim, dec_voc_size) def forward (self, dec, enc, t_mask, s_mask ): dec = self.embedding(dec) for layer in self.layers: dec = layer(dec, enc, t_mask, s_mask) dec = self.fc(dec) return dec
八、Transformer完整代码实现
Transformer完整代码实现地址:Transformer
参考资料:Attention is all you need 注意力机制的本质|Self-Attention|Transformer|QKV矩阵 【可视化】Transformer中多头注意力的计算过程 【研1基本功 (真的很简单)注意力机制】手写多头注意力机制 如何理解Transformer的位置编码,PositionalEncoding详解