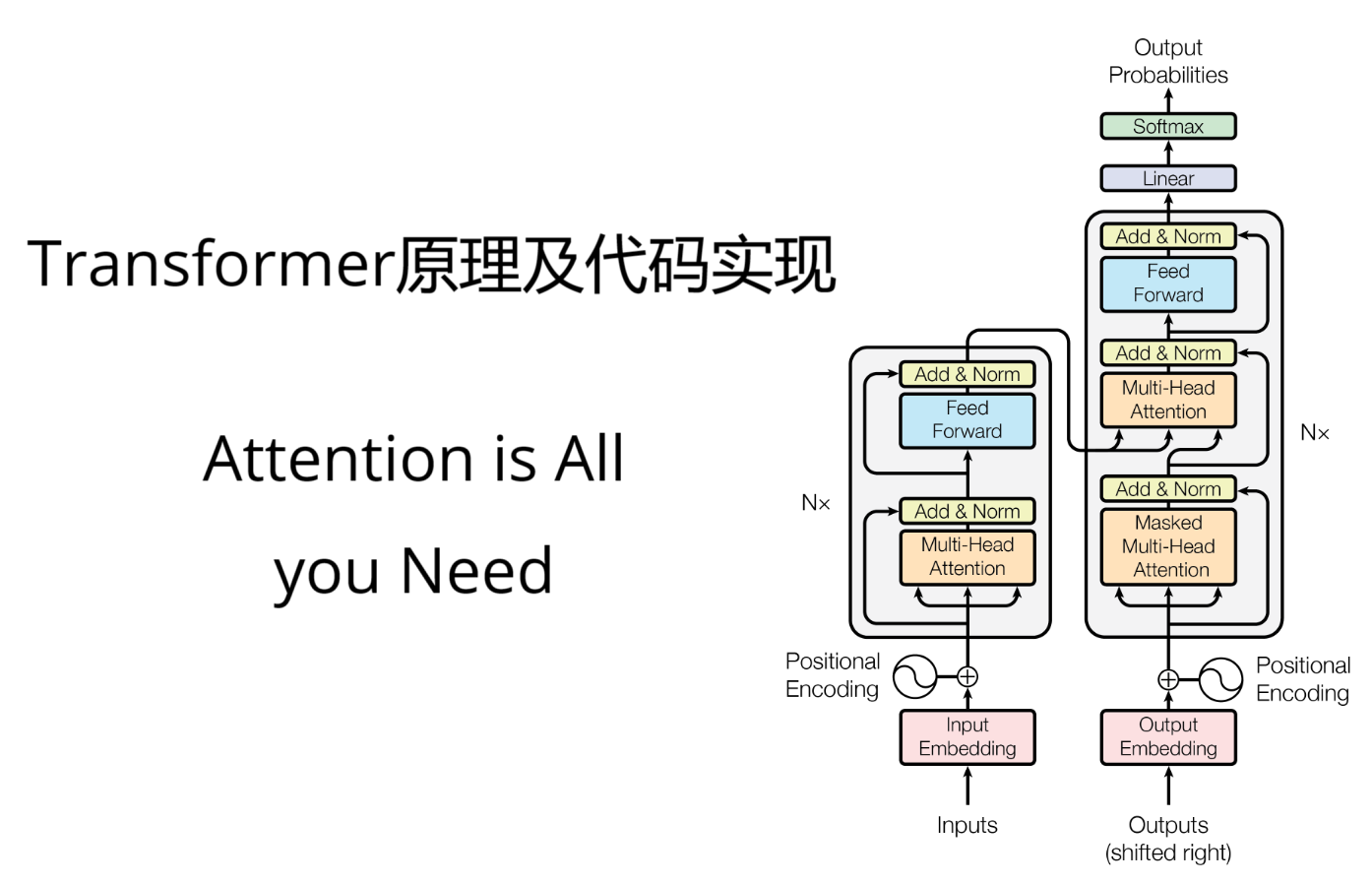
动手学深度学习之神经网络模型总结
本文主要总结了李沐老师《动手学深度学习》课程中的一些经典的神经网络模型。主要包括线性回归模型 、多层感知机模型 、简单的卷积神经网络模型 、经典卷积神经网络LeNet 、深度卷积神经网络AlexNet 、使用块的网络VGG 、网络中的网络NiN 、含并行连接的网络GoogLeNet 、残差网络ResNet 等等。动手学深度学习 PyTorch版:课程链接
一、环境配置
确认是否有Nvidia GPU,有的话去CUDA官网安装[CUDA安装官网](https://developer.nvidia.cn/cuda-downloads)
安装Python包管理工具Anaconda或Miniconda
根据CUDA的版本选择对应版本的GPU版Pytorch[Pytorch安装官网](https://pytorch.p2hp.com/#google_vignette)
安装包d2l和jupyter
具体操作可参照视频Windows 下安装 CUDA 和 Pytorch 跑深度学习 - 动手学深度学习v2
一、线性神经网络
1.1 线性回归模型
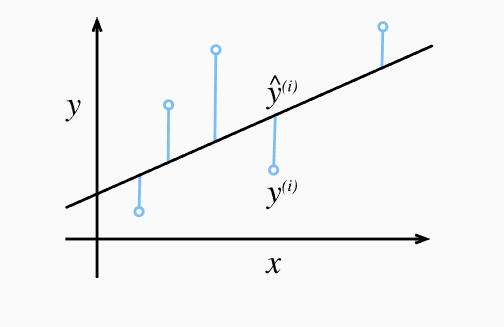
线性回归 y = w x + b y=wx+b y = w x + b y = w ⃗ ⋅ x ⃗ + b y={\vec w }\cdot{\vec x}+b y = w ⋅ x + b w ⃗ \vec w w b b b
1.1.1 从零开始实现线性回归
为了简单起见,我们将根据带有噪声的线性模型构造一个人造数据集。 我们的任务是使用这个有限样本的数据集来恢复这个模型的参数。
1.1.1.1 导包
第一步,导入需要使用的包,导入random包的目的是帮助我们构造人造数据集
1 2 3 import randomimport torchfrom d2l import torch as d2l
1.1.1.2 构造人造数据集
第二步,构造人造数据集,我们的目标是构造一个包含10000个样本的数据集,其中每个样本包含从标准正态分布中采样的2个特征,所以最终得到的输入x x x w = [ 2 , − 3.4 ] T 、 b = 4.2 w=[2,-3.4]^\mathrm T、b=4.2 w = [ 2 , − 3.4 ] T 、 b = 4.2 ϵ \epsilon ϵ
1 2 3 4 5 6 7 8 9 10 def synthetic_data (w, b, num_examples ): """生成y=Xw+b+噪声""" X = torch.normal(0 , 1 , (num_examples, len (w))) y = torch.matmul(X, w) + b y += torch.normal(0 , 0.01 , y.shape) return X, y.reshape((-1 , 1 )) true_w = torch.tensor([2 , -3.4 ]) true_b = 4.2 features, labels = synthetic_data(true_w, true_b, 1000 )
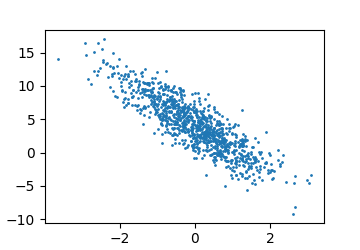
我们可以根据第二个特征来查看我们生成的随机数据集:
1 2 3 d2l.set_figsize() d2l.plt.scatter(features[:, (1 )].detach().numpy(), labels.detach().numpy(), 1 ) d2l.plt.show()
得到的输出图:
1.1.1.3 读取数据集
在读取数据集时,我们一般使用小批量进行读取,因为小批量数据读取有以下几个优势:
内存效率 :如果数据集非常大,无法一次性加载到内存中,使用小批量可以有效地管理内存。模型在训练时只需处理一小部分数据,而不是一次读取整个数据集。训练稳定性 :小批量训练可以让模型的权重更新更加平稳。如果使用整个数据集进行梯度更新(称为全量梯度下降),每次更新都基于所有数据,会导致权重更新比较缓慢。而如果每次只使用一个样本(称为随机梯度下降,SGD),梯度更新会很快,但更新过程容易波动。小批量能够在稳定性和效率之间取得平衡。计算效率 :现代硬件(如GPU和TPU)在处理批量数据时非常高效。使用小批量能够让硬件的计算资源得到充分利用,增加训练速度。更好的泛化能力 :通过在每个小批量中对不同数据子集进行梯度计算,模型可以在权重更新时学习更多的样本分布变异,帮助提高模型的泛化能力。并行处理 :小批量训练可以更好地并行化处理,尤其是在深度学习中,利用GPU或分布式系统进行并行运算可以显著提高训练速度。
1 2 3 4 5 6 7 8 9 10 11 12 def data_iter (batch_size, features, labels ): num_examples = len (features) indices = list (range (num_examples)) random.shuffle(indices) for i in range (0 , num_examples, batch_size): batch_indices = torch.tensor( indices[i: min (i + batch_size, num_examples)]) yield features[batch_indices], labels[batch_indices]
在上面的代码中,我们定义了一个data_iter函数,该函数接收批量大小、特征矩阵和标签向量作为输入,生成大小为batch_size的小批量。每个小批量包含一组特征和标签。
我们可以设置一个小批量来验证data_iter函数:
1 2 3 4 5 batch_size = 10 for X, y in data_iter(batch_size, features, labels): print (X, '\n' , y) break
得到输出:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 tensor([[-0.3809 , -0.8246 ], [-0.1036 , -0.3585 ], [ 1.5089 , -0.8039 ], [ 0.2423 , -0.8148 ], [-1.7175 , -0.0828 ], [ 0.9321 , 0.4002 ], [ 1.5887 , -1.1424 ], [-0.0875 , 0.4256 ], [-0.4705 , 0.8662 ], [ 1.6353 , -0.7181 ]]) tensor([[ 6.2405 ], [ 5.2150 ], [ 9.9482 ], [ 7.4561 ], [ 1.0414 ], [ 4.6962 ], [11.2425 ], [ 2.5706 ], [ 0.3183 ], [ 9.9026 ]])
可以看到输入X X X
1.1.1.4 初始化模型参数
在开始训练模型之前,我们需要初始化模型的参数w w w b b b w w w b b b
1 2 w = torch.normal(0 , 0.01 , size=(2 ,1 ), requires_grad=True ) b = torch.zeros(1 , requires_grad=True )
1.1.1.5 定义模型
我们使用最简单的线性回归y = w ⃗ ⋅ x ⃗ + b y={\vec w }\cdot{\vec x}+b y = w ⋅ x + b
1 2 3 def linreg (X, w, b ): """线性回归模型""" return torch.matmul(X, w) + b
1.1.1.6 定义损失函数
在线性回归模型中我们使用均方误差损失函数作为损失函数:
l ( i ) ( w ⃗ , b ) = 1 2 ( y ^ ( i ) − y ( i ) ) 2 l^{(i)}(\vec w,b) = {1 \over 2}{(\hat y^{(i)}-y^{(i)})^2}
l ( i ) ( w , b ) = 2 1 ( y ^ ( i ) − y ( i ) ) 2
1 2 3 def squared_loss (y_hat, y ): """均方损失""" return (y_hat - y.reshape(y_hat.shape)) ** 2 / 2
1.1.1.7 定义优化算法
这里我们使用随机梯度下降作为优化算法。随机梯度下降通过不断地在损失函数递减的方向上更新参数来降低误差。
repeat until convergence: { w j = w j − α ∂ J ( w ⃗ , b ) ∂ w j b = b − α ∂ J ( w ⃗ , b ) ∂ b } \begin{align*} \text{repeat}&\text{ until convergence:} \; \lbrace \newline
\; w_j &= w_j - \alpha \frac{\partial J(\vec{w},b)}{\partial w_j} \; \newline
b &= b - \alpha \frac{\partial J(\vec{w},b)}{\partial b} \newline \rbrace
\end{align*}
repeat w j b } until convergence: { = w j − α ∂ w j ∂ J ( w , b ) = b − α ∂ b ∂ J ( w , b )
1 2 3 4 5 6 7 def sgd (params, lr, batch_size ): """小批量随机梯度下降""" with torch.no_grad(): for param in params: param -= lr * param.grad / batch_size param.grad.zero_()
1.1.1.8 训练模型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 lr = 0.03 num_epochs = 3 net = linreg loss = squared_loss for epoch in range (num_epochs): for X, y in data_iter(batch_size, features, labels): l = loss(net(X, w, b), y) l.sum ().backward() sgd([w, b], lr, batch_size) with torch.no_grad(): train_l = loss(net(features, w, b), labels) print (f'epoch {epoch + 1 } , loss {float (train_l.mean()):f} ' ) print (f'w的估计误差: {true_w - w.reshape(true_w.shape)} ' )print (f'b的估计误差: {true_b - b} ' )
训练结果:epoch 1, loss 0.021807))
这样就实现了一个简单的线性神经网络。
1.1.2 线性回归模型的简洁实现
在上节中我们将每个函数都做了内部实现,但实际上在深度学习框架中有很多组件可以直接调用,现在我们来简洁实现一个线性回归模型。
1.1.2.1 导包并生成数据集
这次我们直接通过导包获取数据集。
1 2 3 4 5 6 7 8 import numpy as npimport torchfrom torch.utils import datafrom d2l import torch as d2ltrue_w = torch.tensor([2 , -3.4 ]) true_b = 4.2 features, labels = d2l.synthetic_data(true_w, true_b, 1000 )
1.1.2.2 读取数据集
之前我们使用遍历样本来读取数据集,这里我们可以调用框架中现有的API来读取数据。 我们将输入值X(features)和标签值(labels)作为API的参数传递,并通过数据迭代器指定batch_size。 此外,布尔值is_train表示是否希望数据迭代器对象在每个迭代周期内打乱数据。
1 2 3 4 5 6 7 8 9 def load_array (data_arrays, batch_size, is_train=True ): """构造一个PyTorch数据迭代器""" dataset = data.TensorDataset(*data_arrays) return data.DataLoader(dataset, batch_size, shuffle=is_train) batch_size = 10 data_iter = load_array((features, labels), batch_size)
1.1.2.3 定义模型
对于标准深度学习模型,我们可以使用框架的预定义好的层。我们首先定义一个模型变量net,它是一个Sequential类的实例。 Sequential类可以将多个层串联在一起。 当给定输入数据时,Sequential实例将数据传入到第一层, 然后将第一层的输出作为第二层的输入,以此类推。
1 2 3 4 from torch import nnnet = nn.Sequential(nn.Linear(2 , 1 ))
1.1.2.4 初始化模型参数
我们初始化模型参数w w w b b b
1 2 3 net[0 ].weight.data.normal_(0 , 0.01 ) net[0 ].bias.data.fill_(0 )
1.1.2.5 定义损失函数
这里我们可以直接使用nn类中定义好的均方误差损失函数,也称L 2 L_2 L 2
1.1.2.6 定义优化算法
torch.optim是一个实现了各种优化算法的库。大部分常用的方法得到支持,并且接口具备足够的通用性,使得未来能够集成更加复杂的方法。https://sonderhs.github.io/2024/05/02/吴恩达机器学习/吴恩达机器学习(一):监督学习/) n e t . p a r a m e t e r s ( ) net.parameters() n e t . p a r am e t ers ( ) l r lr l r
1 trainer = torch.optim.SGD(net.parameters(), lr=0.03 )
1.1.2.7 训练模型
我们设置批量数num_epochs为3,对于每个小批量,我们需要做的就是:通过前向传播计算损失→ \to → → \to →
1 2 3 4 5 6 7 8 9 10 11 12 13 14 num_epochs = 3 for epoch in range (num_epochs): for X, y in data_iter: l = loss(net(X) ,y) trainer.zero_grad() l.backward() trainer.step() l = loss(net(features), labels) print (f'epoch {epoch + 1 } , loss {l:f} ' ) w = net[0 ].weight.data print ('w的估计误差:' , true_w - w.reshape(true_w.shape))b = net[0 ].bias.data print ('b的估计误差:' , true_b - b)
这样我们就通过pytorch框架简洁实现了一个线性神经网络。
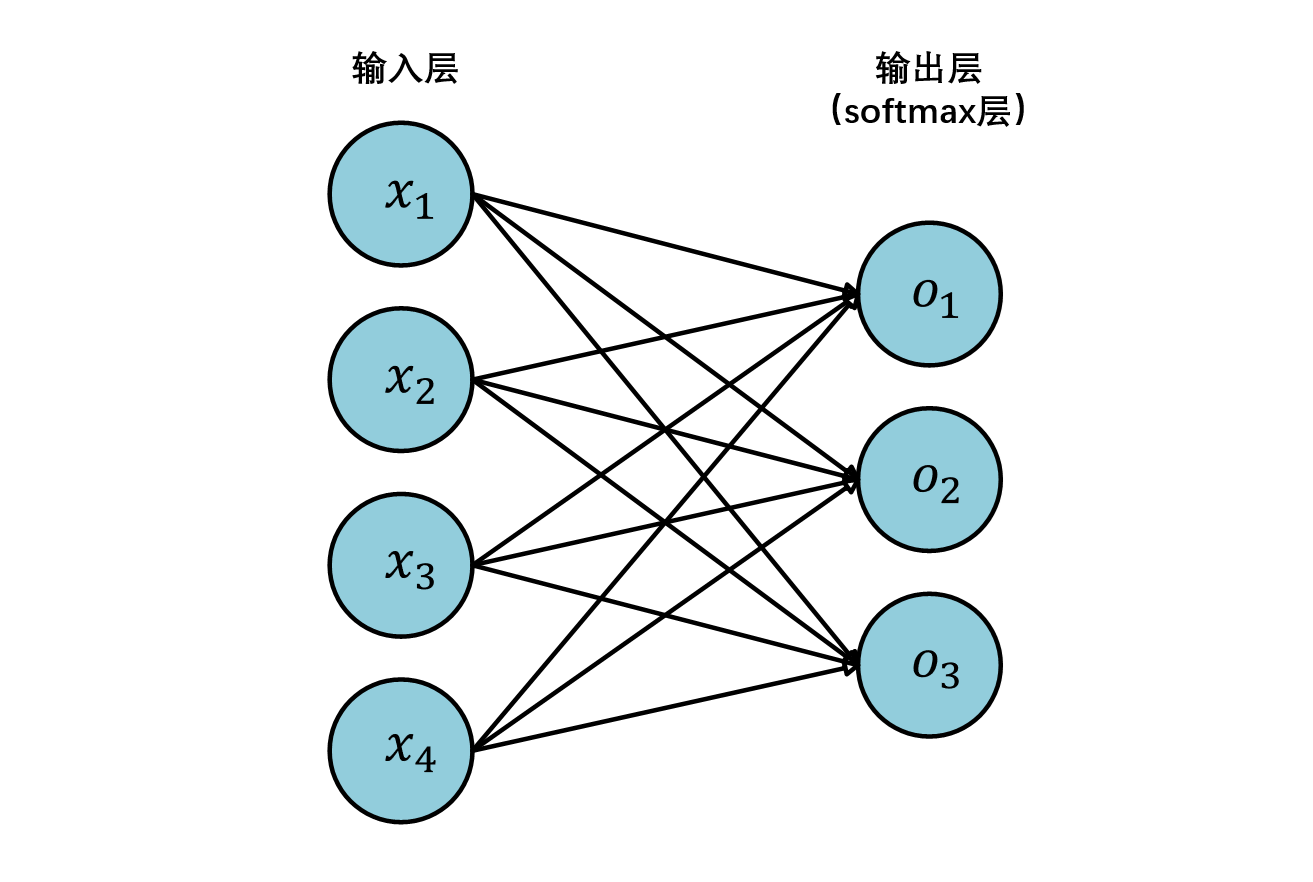
1.2 softmax回归模型
线性回归主要用于解决预测和趋势分析问题,而对于分类问题我们常用的模型为softmax回归模型
z j = w ⃗ j ⋅ x ⃗ + b j , 其中 j = 1 , 2 , . . . , N z_j=\vec w_j \cdot \vec x + b_j ,其中j=1,2,...,N \\
z j = w j ⋅ x + b j , 其中 j = 1 , 2 , ... , N
预测结果为j的概率:
a j = e z j ∑ j = 1 N e z j = P ( y = j ∣ x ⃗ ) a_j=\frac{e^{z_j}}{\sum\limits_{j = 1}^{N}e^{z_j}}=P(y=j|\vec x)
a j = j = 1 ∑ N e z j e z j = P ( y = j ∣ x )
1.2.1 从零开始实现softmax回归
本节我们不再需要手动生成数据集,而是使用[Fashion-MNIST数据集](https://www.alphaxiv.org/abs/1708.07747)。
1.2.1.1 导包
1 2 3 4 5 6 import torchfrom IPython import displayfrom d2l import torch as d2lbatch_size = 256 train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
1.2.1.2 初始化模型参数
Fasion-MNIST中的图片大小都是28*28的,所以我们将其展开成长度为784的一维向量作为输入,所以输入大小为784;由于我们需要将图片分为10类,所以输出大小为10。w w w
1 2 3 4 5 num_inputs = 784 num_outputs = 10 W = torch.normal(0 , 0.01 , size=(num_inputs, num_outputs), requires_grad=True ) b = torch.zeros(num_outputs, requires_grad=True )
1.2.1.3 定义softmax
softmax函数有三个基本步骤:
对每个项求幂;
对每一行求和,得到每个样本的规范化常数;
将每一行除以其规范化常数,确保结果的和为1。
y i = s o f t m a x ( x i ) = e x i ∑ i = 1 N e x j y_i = softmax(x_i)=\frac{e^{x_i}}{\sum\limits_{i = 1}^{N}e^{x_j}}
y i = so f t ma x ( x i ) = i = 1 ∑ N e x j e x i
用代码实现softmax函数:
1 2 3 4 def softmax (x ): x_exp = np.exp(x) partition = x_exp.sum (1 , keepdim=True ) return x_exp /partition
1.2.1.4 定义模型
softmax模型实现非常简单,我们首先将输入的图片转化为我们所需的向量形状,然后输入到第一个线性层,在通过softmax层输出即可。
1 2 3 4 5 6 7 """ X.reshape((-1, W.shape[0])):将输入的图片转化为一个二维向量 np.dot(X.reshape((-1, W.shape[0])), W) + b:将输入向量与参数w相乘后再加上偏置值b,即得到经过第一个线性层后的输出 softmax(...):经过softmax层后输出 """ def net (X ): return softmax(np.dot(X.reshape((-1 , W.shape[0 ])), W) + b)
1.2.1.5 定义损失函数
在softmax模型中我们使用交叉熵损失函数作为损失函数。
l ( y , y ^ ) = − ∑ j = 1 N y j l o g y ^ j l(y,\hat y) = -\sum\limits_{j = 1}^{N}y_jlog\hat y_j
l ( y , y ^ ) = − j = 1 ∑ N y j l o g y ^ j
其中:y y y y ^ \hat y y ^
1 2 def cross_entropy (y_hat, y ): return - np.log(y_hat[range (len (y_hat)),y])
1.2.1.6 分类精度
分类精度指的是正确预测数量与总预测数量之比。为了计算精度,我们执行以下操作:
若y ^ \hat y y ^
第二维度代表输入x属于每一类别的概率,每一行的最大值即为我们的预测结果。所以我们使用argmax函数找到每行中最大元素的索引来获取预测类别;
之后我们将预测标签y ^ \hat y y ^ y y y
1 2 3 4 5 6 def accuracy (y_hat, y ): """计算预测正确的数量""" if len (y_hat.shape) > 1 and y_hat.shape[1 ] > 1 : y_hat = y_hat.argmax(axis=1 ) cmp = y_hat.type (y.dtype) == y return float (cmp.type (y.dtype).sum ())
对于任意数据迭代器data_iter可访问的数据集, 我们可以评估在任意模型net的精度。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 def evaluate_accuracy (net, data_iter ): """ 计算在指定数据集上模型的精度 isinstance(object,classtype):判断对象object是否是classtype类型 net.eval():将模型设置为评估模式,在评估模型下,网络会 1.停用dropout(不过本模型中没有使用dropout) 2.调整Batch Normalization的行为:在评估模式下,BatchNorm使用在训练过程中计算并存储的全局均值和方差,不再基于输入动态计算 使用net.eval()可以确保模型的表现和你在训练后测试模型时的表现一致,尤其是避免 Dropout 和 BatchNorm 的随机性。 with torch.no_grad():表明当前过程中不需要计算梯度,可以节省内存空间,加快模型评估的速度 """ if isinstance (net, torch.nn.Module): net.eval () metric = Accumulator(2 ) with torch.no_grad(): for X, y in data_iter: metric.add(accuracy(net(X), y), y.numel()) return metric[0 ] / metric[1 ]
再定义一个实用程序类Accumulator,用于对多个变量进行累加,Accumulator实例中创建了2个变量, 分别用于存储正确预测的数量和预测的总数量。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Accumulator : """在n个变量上累加""" def __init__ (self, n ): self.data = [0.0 ] * n def add (self, *args ): self.data = [a + float (b) for a, b in zip (self.data, args)] def reset (self ): self.data = [0.0 ] * len (self.data) def __getitem__ (self, idx ): return self.data[idx]
1.2.1.7 训练模型
softmax回归的训练与之前线性回归模型的训练类似:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 def train_epoch_ch3 (net, train_iter, loss, updater ): """训练模型一个迭代周期(定义见第3章)""" if isinstance (net, torch.nn.Module): net.train() metric = Accumulator(3 ) for X, y in train_iter: y_hat = net(X) l = loss(y_hat, y) if isinstance (updater, torch.optim.Optimizer): updater.zero_grad() l.mean().backward() updater.step() else : l.sum ().backward() updater(X.shape[0 ]) metric.add(float (l.sum ()), accuracy(y_hat, y), y.numel()) return metric[0 ] / metric[2 ], metric[1 ] / metric[2 ]
定义一个在动画中绘制数据的实用程序类Animator:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 class Animator : """在动画中绘制数据""" def __init__ (self, xlabel=None , ylabel=None , legend=None , xlim=None , ylim=None , xscale='linear' , yscale='linear' , fmts=('-' , 'm--' , 'g-.' , 'r:' 1 , ncols=1 , figsize=(3.5 , 2.5 ): if legend is None : legend = [] d2l.use_svg_display() self.fig, self.axes = d2l.plt.subplots(nrows, ncols, figsize=figsize) if nrows * ncols == 1 : self.axes = [self.axes, ] self.config_axes = lambda : d2l.set_axes( self.axes[0 ], xlabel, ylabel, xlim, ylim, xscale, yscale, legend) self.X, self.Y, self.fmts = None , None , fmts def add (self, x, y ): if not hasattr (y, "__len__" ): y = [y] n = len (y) if not hasattr (x, "__len__" ): x = [x] * n if not self.X: self.X = [[] for _ in range (n)] if not self.Y: self.Y = [[] for _ in range (n)] for i, (a, b) in enumerate (zip (x, y)): if a is not None and b is not None : self.X[i].append(a) self.Y[i].append(b) self.axes[0 ].cla() for x, y, fmt in zip (self.X, self.Y, self.fmts): self.axes[0 ].plot(x, y, fmt) self.config_axes() display.display(self.fig) display.clear_output(wait=True )
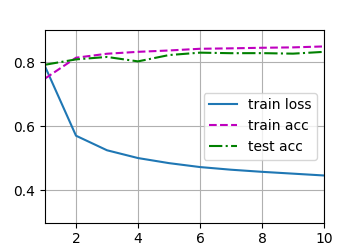
训练模型:
1 2 3 4 5 6 7 8 9 10 11 12 def train_ch3 (net, train_iter, test_iter, loss, num_epochs, updater ): """训练模型(定义见第3章)""" animator = Animator(xlabel='epoch' , xlim=[1 , num_epochs], ylim=[0.3 , 0.9 ], legend=['train loss' , 'train acc' , 'test acc' ]) for epoch in range (num_epochs): train_metrics = train_epoch_ch3(net, train_iter, loss, updater) test_acc = evaluate_accuracy(net, test_iter) animator.add(epoch + 1 , train_metrics + (test_acc,)) train_loss, train_acc = train_metrics assert train_loss < 0.5 , train_loss assert train_acc <= 1 and train_acc > 0.7 , train_acc assert test_acc <= 1 and test_acc > 0.7 , test_acc
设置训练参数:
1 2 3 4 5 6 7 8 lr = 0.1 def updater (batch_size ): return d2l.sgd([W, b], lr, batch_size) num_epochs = 10 train_ch3(net, train_iter, test_iter, cross_entropy, num_epochs, updater) d2l.plt.show()
训练结果:
1.2.1.8 预测
给定一系列图像,我们比较它们的实际标签(文本输出的第一行)和模型预测(文本输出的第二行):
1 2 3 4 5 6 7 8 9 10 11 12 def predict_ch3 (net, test_iter, n=6 ): """预测标签(定义见第3章)""" for X, y in test_iter: break trues = d2l.get_fashion_mnist_labels(y) preds = d2l.get_fashion_mnist_labels(net(X).argmax(axis=1 )) titles = [true +'\n' + pred for true, pred in zip (trues, preds)] d2l.show_images( X[0 :n].reshape((n, 28 , 28 )), 1 , n, titles=titles[0 :n]) predict_ch3(net, test_iter) d2l.plt.show()
预测结果:
1.2.2 softmax回归的简洁实现
1.2.2.1 导包
1 2 3 4 5 6 import torchfrom torch import nnfrom d2l import torch as d2lbatch_size = 256 train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
1.2.2.2 初始化模型参数
1 2 3 4 5 6 7 8 9 10 net = nn.Sequential(nn.Flatten(), nn.Linear(784 , 10 )) def init_weights (m ): if type (m) == nn.Linear: nn.init.normal_(m.weight, std=0.01 ) net.apply(init_weights)
1.2.2.3 设置损失函数
直接使用内置的交叉熵损失函数:
1 2 3 4 5 6 7 """ 参数reduction用于指定应用于输出的归约方式,可选值:'none','mean','sum' 'none':不进行归约 'mean':对所有样本的损失求平均值 'sum':对所有样本的损失求和 """ loss = nn.CrossEntropyLoss(reduction='none' )
1.2.2.4 设置优化算法
优化算法使用SGD(随机梯度下降)算法,学习率设置为0.1:
1 trainer = torch.optim.SGD(net.parameters(), lr=0.1 )
1.2.2.5 训练
1 2 3 num_epochs = 10 d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer) d2l.plt.show()