
Python学习笔记
一、Python基础语法
1.0 常用快捷键
- ctrl+alt+s: 打开软件设置
- ctrl+d: 复制当前行代码
- shift+alt+上\下: 将当前行代码上移或下移
- ctrl+shift+f10: 运行当前代码文件
- shift+f6: 重命名文件
- ctrl+a: 全选
- ctrl+c\v\x: 复制、粘贴、剪切
- ctrl+f: 搜索
1.1 字面量
1.1.1 字面量
在代码中,被写下来的固定的值,称之为字面量。
1.1.2 Python常用数据类型
(1)数字(Number):支持整数(int),浮点数(float),复数(complex),布尔(bool);
(2)字符串(String):描述文本的一种数据类型;
(3)列表(List):有序地可变序列;
(4)元组(Tuple):有序地不可变序列;
(5)集合(Set):无序的不重复集合;
(6)字典(Dictionary):无序Key-Value集合。
1.2 注释
1.2.1 单行注释
以#开头,#右边的所有文字作为注释内容
1.2.2 多行注释
以一对三个双引号(“”“注释内容”“”)来解释说明一段代码的作用及使用方法
1.3 变量
1.3.1 变量
在程序运行时,能够存储结算结果或能表示值的抽象概念
1.3.2 变量的定义格式
变量名称 = 变量的值
示例:
1 | money = 50 |
1.4 数据类型
1.4.1 常见数据类型
(1)string:字符串类型
(2)int:整型(有符号)
(3)float:浮点型(有符号)
1.4.2 验证数据类型
可以利用type()语句验证数据类型,type()语句使用方式有三种:
1.在print语句中直接输出类型信息,示例:
1 | print(type("黑马程序员")) |
打印结果为:
1 | <class 'str'> |
2.使用变量存储type()的结果(返回值),示例:
1 | string_type = type("黑马程序员") |
打印结果为:
1 | <class 'str'> |
3.查看变量中存储的数据类型,示例:
1 | name = "黑马程序员" |
打印结果为:
1 | <class 'str'> |
注:type()查看的是变量存储的数据的类型,而不是变量的类型,变量是没有类型的
1.5 数据类型转换
常见的转换语句:
| 语句 | 说明 |
|---|---|
| int(x) | 将x转换为整数 |
| float(x) | 将x转换为浮点数 |
| str(x) | 将x转换为字符串 |
示例:
1 | # 将数字转换为字符串 |
打印结果为:
1 | <class 'str'> 11 |
1.6 标识符
1.6.1 什么是标识符
在Python中,我们可以给很多东西起名字,比如:变量的名字,方法的名字,类的名字等等,这些名字我们统一称之为标识符,用来作为内容的标识。
1.6.2 标识符命名规则
- 内容限定
- 大小写敏感
- 不可使用关键字
标识符中只允许出现四类元素:
- 英文
- 中文 (不推荐使用)
- 数字 (不可以用在开头)
- 下划线 (_)
1.6.3 变量命名规范
- 变量名
- 见名知意
- 下划线命名法
- 英文字母全小写
- 类名
- 方法名
1.7 运算符
1.7.1 算术运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 加 | a + b |
| - | 减 | a - b |
| * | 乘 | a * b |
| / | 除 | a / b |
| // | 取整除 | 返回商的整数部分,如9//2结果为4 |
| % | 取余 | b % a |
| ** | 指数 | 10 ** 20表示10的20次方 |
1.7.2 赋值运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 赋值运算符 | 把=右边的结果赋给左边的变量,如num = 1 + 2 * 3,结果num的值为7 |
1.7.3 复合赋值运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| += | 加法赋值运算符 | c+=a等效于c=c+a |
| -= | 减法赋值运算符 | c-=a等效于c=c-a |
| *= | 乘法赋值运算符 | c*=a等效于c=c*a |
| /= | 除法赋值运算符 | c/=a等效于c=c/a |
| //= | 取整除法赋值运算符 | c//=a等效于c=c//a |
| %= | 取余法赋值运算符 | c%=a等效于c=c+% |
| **= | 指数法赋值运算符 | c**=a等效于c=c**a |
1.8 字符串的三种定义方式
1.8.1 字符串定义形式:
- 单引号定义法:name = ‘黑马程序员’
- 双引号定义法:name = “黑马程序员”
- 三引号定义法:name = “”“黑马程序员”“”
注:三引号定义法和多行注释的写法一样,同样支持换行操作,使用变量接收它,它就是字符串,不使用变量接收它,它就可以作为多行注释使用
1.8.2 字符串的引号嵌套
当想要定义的字符串本身含有引号时,可以使用以下几种方式:
- 单引号定义法,可以内含双引号
- 双引号定义法,可以内含单引号
- 可以使用转义字符()来将引号解除效用,变成普通字符串
示例:
1 | name = '"黑马程序员"' |
打印结果为:
1 | "黑马程序员" |
1.9 字符串的拼接
如果我们有两个字符串(文本)字面量,可以将其拼接成一个字符串,通过+号即可完成,如:
1 | print("学IT来黑马"+"月薪过万") |
打印结果为:
1 | 学IT来黑马月薪过万 |
不过一般,单纯的2个字符串字面量进行拼接显得很呆,一般,字面量和变量或变量和变量质检会使用拼接,如:
1 | name = "黑马程序员" |
打印结果为:
1 | 我的名字是黑马程序员 |
注:整数及浮点数等非字符串类型无法直接使用’+'与字符串进行拼接
1.10 字符串格式化
通过%s进行占位拼接:
1 | name = "黑马程序员" |
其中:%表示占位,s表示将变量变成字符串放入占位的地方
打印结果为:
1 | 学IT就来 黑马程序员 |
数字类型也可以进行占位拼接:
1 | class_num = 57 |
打印结果为:
1 | Python大数据学科,北京57期,毕业平均工资:16781 |
Python中常用的数据类型占位:
| 格式符号 | 转化 |
|---|---|
| %s | 将内容转换成字符串,放入占位位置 |
| %d | 将内容转换成整型,放入占位位置 |
| %f | 将内容转换成浮点型,放入占位位置 |
1.11 字符串格式化的精度控制
我们可以使用辅助符号"m.n"来控制数据的宽度和精度
- m,控制宽度,要求是数字(很少使用),设置的宽度小于数字自身时不生效
- n,控制小数点精度,要求是数字,会进行小数的四舍五入
示例:
- %5d:表示将整数的宽度控制在5位,如数字11被设置为5d后就会变成[空格][空格][空格]11,用三个空格补足宽度
- %7.2f:表示将宽度控制在7位,小数点后精度控制在2位,如对11.345进行精度控制%7.2后变为[空格][空格]11.35
1.12 字符串格式化方式(二)
快速格式化,通过语法:f"内容{变量}"的格式来快速进行格式化
示例:
1 | name = "传智播客" |
打印结果:
1 | 我是传智播客, 我成立于2006, 我今天的股票价格是:19.99 |
注:此种方法不会理会类型,但不能做精度控制。适合对精度没有要求时快速使用
1.13 对表达式进行格式化
表达式:一条具有明确执行结果的代码语句
使用情况:无需对表达式结果进行存储,可以直接使用结果
示例:
1 | print("1 * 1的结果是:%d" % (1 * 1)) |
打印结果:
1 | 1 * 1的结果是:1 |
1.14 数据输入(input语句)
- 数据输入:input()
- 数据输出:print()
示例:
1 | print("请告诉我你是谁?") |
输入:张三
打印结果:
1 | 请告诉我你是谁? |
input前的print可以简化:
1 | name = input("请告诉我你是谁?") |
注:input语句会自动将输入的内容转换为str类型,若要得到int类型的结果,可以进行数据类型转换
二、Python判断语句
2.1 布尔类型和比较运算符
2.1.1 布尔类型
布尔(bool)表达现实生活中的逻辑,即真和假
- True表示真
- False表示假
Bool类型被划分为数字类型,是因为True和False本质上是一个数字,True记作1,False记作0
2.1.2 布尔类型的定义
定义变量存储布尔类型数据:变量名称 = 布尔类型字面量
2.1.3 比较运算符
布尔类型的数据,不仅可以通过定义得到,也可以通过比较运算符进行内容比较得到
如下代码:
1 | result = 10 > 5 |
打印结果:
1 | 10 > 5 的结果是True,类型是<class 'bool'> |
常用的比较运算符:
| 运算符 | 描述 |
|---|---|
| == | 判断内容是否相等,满足为True,不满足为False |
| != | 判断内容是否不相等,满足为True,不满足为False |
| > | 判断运算符左侧内容是否大于右侧内容,满足为True,不满足为False |
| < | 判断运算符左侧内容是否小于右侧内容,满足为True,不满足为False |
| >= | 判断运算符左侧内容是否大于等于右侧内容,满足为True,不满足为False |
| <= | 判断运算符左侧内容是否小于等于右侧内容,满足为True,不满足为False |
2.2 if语句的基本格式
if语句格式如下:
if 要判断的条件:
条件成立时,要做的事情
示例:
1 | age = 23 |
打印结果:
1 | 我已经成年了 |
2.3 if else语句
if else语句格式:
if 条件:
满足条件时要做的事情1
满足条件时要做的事情2
满足条件时要做的事情3
…(省略)…
else:
不满足条件时要做的事情1
不满足条件时要做的事情2
不满足条件时要做的事情3
…(省略)…
示例:
1 | print("欢迎来到黑马儿童游乐场,儿童免费,成人收费") |
输入结果为20(>18)时,打印结果为:
1 | 欢迎来到黑马儿童游乐场,儿童免费,成人收费 |
输入结果为16(<18)时,打印结果为:
1 | 欢迎来到黑马儿童游乐场,儿童免费,成人收费 |
2.4 if elif else语句
if elif else语句格式:
if 条件1:
满足条件1时要做的事情1
满足条件1时要做的事情2
满足条件1时要做的事情3
…(省略)…
elif 条件2
满足条件2时要做的事情1
满足条件2时要做的事情2
满足条件2时要做的事情3
…(省略)…
elif 条件3
满足条件3时要做的事情1
满足条件3时要做的事情2
满足条件3时要做的事情3
…(省略)…
else:
所有条件都不满足时要做的事情1
所有条件都不满足时要做的事情2
所有条件都不满足时要做的事情3
…(省略)…
示例:
1 | print("欢迎来到黑马动物园。") |
输入结果为110 4(两个条件都满足)时,打印结果为:
1 | 欢迎来到黑马动物园。 |
输入结果为110 2(身高满足,VIP等级不满足)时,打印结果为:
1 | 欢迎来到黑马动物园。 |
输入结果为130 4(身高不满足,VIP等级满足)时,打印结果为:
1 | 欢迎来到黑马动物园。 |
输入结果为130 2(身高不满足,VIP等级也不满足)时,打印结果为:
1 | 欢迎来到黑马动物园。 |
注:还有一种简洁式写法,即将输入直接放入条件判断中,如下:
1 | print("欢迎来到黑马动物园。") |
这样做不仅可以使代码更加简洁,还可以减少输入
2.5 判断语句的嵌套
对于需要多层次的判断,我们可以自由组合if elif else,从而完成特定需求的要求
多层次嵌套的格式为:
if 条件1:
满足条件1时要做的事情1
满足条件1时要做的事情2
if 条件2
满足条件2时要做的事情1
满足条件2时要做的事情2
只有第一个if满足条件,才会执行第二个if
注:嵌套的关键点在于:空格缩进;通过空格缩进来决定语句之间的层次关系
示例:
1 | print("欢迎来到黑马动物园") |
如图:判断一共有两层,当外层if满足时继续执行内层判断;当外层if不满足时,直接执行外层的else
如输入130 3时,打印结果为:
1 | 欢迎来到黑马动物园 |
当输入110时,打印结果为:
1 | 欢迎来到黑马动物园 |
2.6 判断语句综合案例
案例要求:
1.数字随机产生,范围1-10
2.有三次机会,通过三层嵌套判断实现
3.每次猜不中时,提示大了还是小了
具体实现代码:
1 | import random |
三、Python循环语句
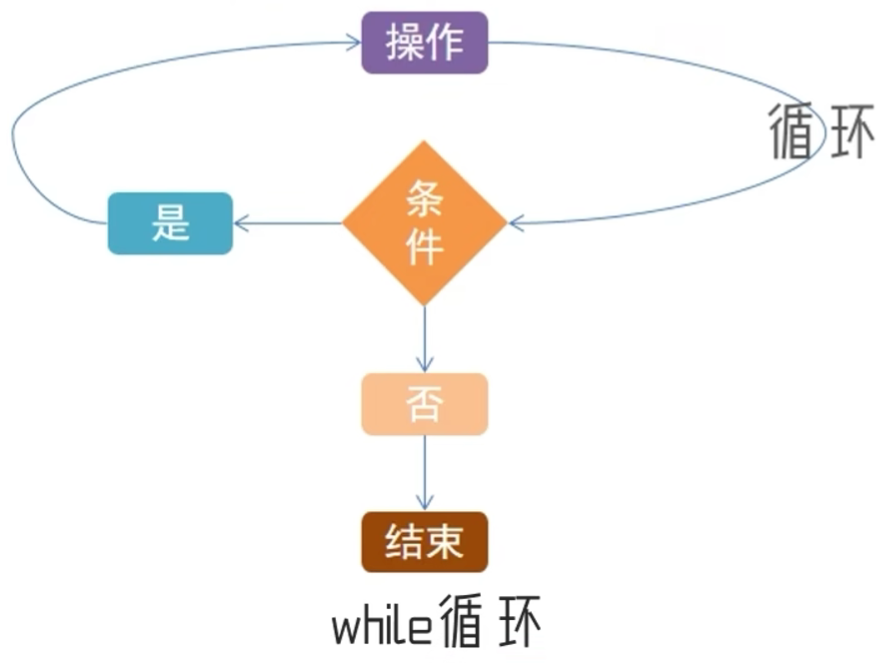
3.1 while循环的基础语法
3.1.1 while循环语句
while循环格式:
while 条件:
满足条件时要做的事情1
满足条件时要做的事情2
满足条件时要做的事情3
…(省略)…
示例:
1 | i = 0 |
打印结果为:
1 | 黑马程序员 |
注:
1.while循环的条件需要得到布尔类型,True表示继续循环,False表示终止循环
2.需要设置循环条件,如i+=1配合i<5,就能确保循环的有限次
3.空格缩进和if判断一样,都需要设置
3.2 while循环的基础案例
案例:
设置一个范围1-100的随机整数变量,通过while循环,配合input语句,判断输入的数字是否等于随机数,要求如下:
- 无限次机会
- 每次一猜不中,会提示大了或小了
- 猜完数字后,提示猜了几次
1 | # 猜数字 |
3.3 while循环的嵌套
while嵌套循环的语法格式:
while 条件:
满足条件时要做的事情1
满足条件时要做的事情2
满足条件时要做的事情3
…(省略)…
while 条件:
满足条件时要做的事情1
满足条件时要做的事情2
满足条件时要做的事情3
…(省略)…
示例:表白100天,每天都会送10朵玫瑰花
1 | # 表白100天,每天送10朵玫瑰花 |
3.4 while嵌套循环案例
案例:
使用while循环打印九九乘法表
1 | i = 1 |
打印结果为:
1 | 1×1=1 |
3.5 for循环语法
3.5.1 for循环的基础语法
while循环与for循环的区别:
- while循环的循环条件是自定义的,自行控制循环条件
- for循环是一种“轮询”机制,是对一批内容进行“逐个处理”
- for循环无法定义循环条件,只能从被处理的数据集中依次取出内容进行处理,所以理论上Python中的for循环无法构建无限循环
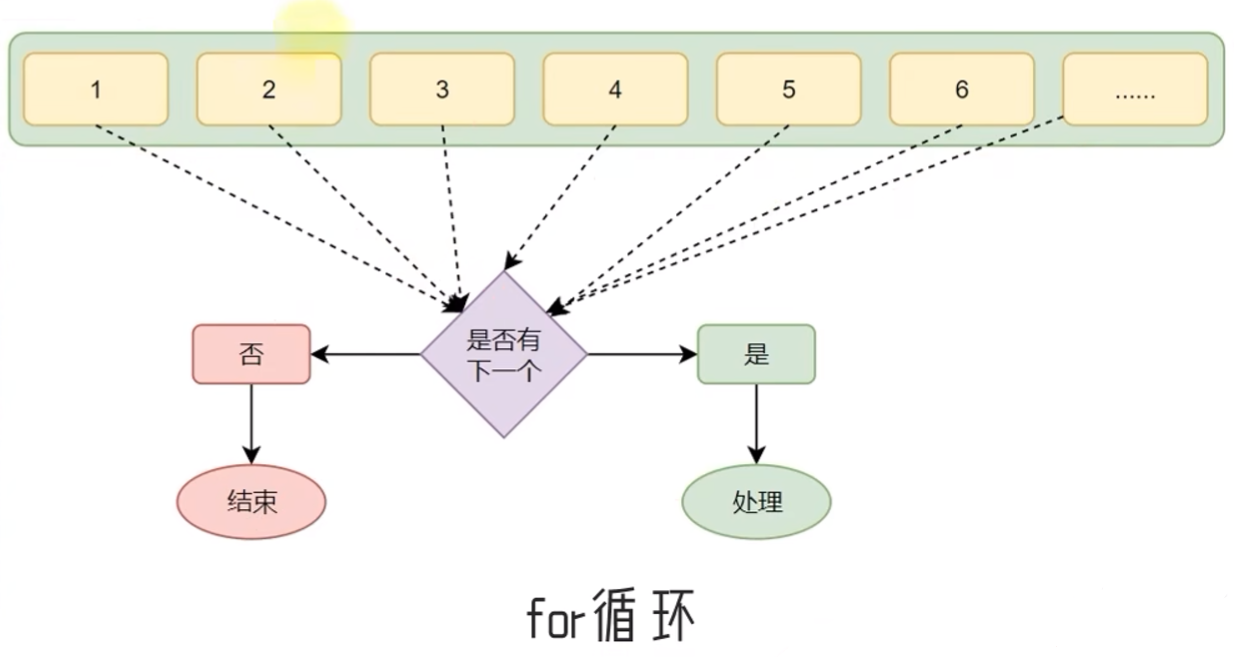
for循环语法:
for 临时变量 in 待处理数据集:
循环满足条件时执行的代码
注:与C语言或Java语言中的for循环不同,Python中的for循环需要提前设置好循环范围,循环的推动由程序自动进行,所以for循环也被叫做遍历循环
示例:
1 | # 遍历字符串 |
打印结果为:
1 | i |
3.5.2 for循环的基础案例
for循环基础案例:
数一数有几个a:定义字符串name,内容为itheima is a brand of itcast,通过for循环遍历此字符串,统计有几个字母a
1 | name = "itheima is a brand of itcast" |
打印结果为:
1 | 该字符串中一共有4个a |
3.5.3 range语句
for循环语法:
for 临时变量 in 待处理数据集:
循环满足条件时执行的代码
for循环语法中的待处理数据集,严格来说称之为:序列类型
序列类型是指:其内容可以一个个一次取出的一种类型,包括:
- 字符串
- 列表
- 元组
- 等
range语句:
利用range语句我们可以获得一个简单的数字序列。
- 语法1:
range(num): 获取一个从0开始,到num结束的数字序列(不含num本身),如range(5)取得的数据是:[0,1,2,3,4] - 语法2:
range(num1,num2):获得一个从num1开始,到num2结束的数字序列(不包含num2本身),如range(5,10)取得的数据是[5,6,7,8,9] - 语法3:
range(num1,num2,step):获得一个从num1开始,到num2结束的数字序列(不包含num2本身),数字之间的步长以step为准(step默认为1),如range(5,10,2)取得的数据是[5,7,9]
3.5.4 变量作用域
for循环语法:
for 临时变量 in 待处理数据集:
循环满足条件时执行的代码
for循环中的临时变量,在编程规范上,其作用范围(作用域)只限定在for循环内部
如果在for循环外部访问临时变量:
- 实际上是可以访问到的
- 但在编程规范上是不允许、不建议这么做的
- 如需访问,可以再for循环上面定义该变量
3.6 for循环的嵌套
3.6.1 for循环嵌套语法
for 临时变量 in 待处理数据集:
循环满足条件时执行的代码
for 临时变量 in 待处理数据集:
循环满足条件时执行的代码
示例:表白100天,每天都会送10朵玫瑰花
1 | # 表白100天,每天送10朵玫瑰花 |
3.6.2 for循环嵌套案例
案例:打印九九乘法表
1 | for i in range(1, 10): |
3.7 循环中断:break和continue
3.7.1 continue关键字
- continue关键字用于:中断本次循环,直接进入下一次循环
- continue可以用于:for循环和while循环,效果一致
- continue在嵌套循环时之作用于其所在的循环
语法:
for i in range(1,100):
语句1
continue
语句2
示例:
1 | for i in range(1,6): |
打印结果为:
1 | 语句1 |
3.7.2 break关键字
- break关键字用于:直接结束循环
- break可用于:for循环和while循环,效果一致
- break在嵌套循环时之作用于其所在的循环
语法:
for i in range(1,100):
语句1
continue
语句2
语句3
示例:
1 | for i in range(1,6): |
打印结果为:
1 | 语句1 |
3.8 循环综合案例
练习案例:发工资
某公司,账户余额有1万元,给20名员工发工资。
- 员工编号从1到20,从编号1开始,依次领取工资,每人可领取1000元
- 领工资时,财务判断员工的绩效分(1-10)(随机生成),如果低于5,不发工资,换下一位
- 如果工资发完了,结束发工资
1 | import random |
打印结果为:
1 | 向员工1发工资1000元,账户余额还有9000元 |
四、Python函数
4.1 函数初体验
函数:是指组织好的,可重复使用的,用来实现特定功能的代码段。
函数的好处:
- 将功能封装在函数内部,可供随时随地重复利用
- 提高代码的复用性,减少重复代码,提高开发效率
示例:定义一个可以计算字符串长度的函数
1 | def my_len(data): |
打印结果为:
1 | 字符串whut的长度为4 |
4.2 函数的定义
4.2.1 函数的定义:
def 函数名(传入参数):
函数体
return 返回值
4.2.2 函数的调用
函数名(参数)
案例:定义一个函数,函数名任意,要求调用后输出以下语句:
欢迎来到黑马程序员!
请出示您的健康码以及72小时核酸证明!
1 | # 定义函数 |
4.3 函数的参数
函数传入参数的功能:在函数进行计算时,接受外部(调用时)提供的数据
示例:定义一个函数用于计算两个数相加
1 | # 定义函数 |
注:
- 函数定义中,提供的x和y称之为:形式参数(形参),表示函数声明将要使用2个参数
- 参数之间使用逗号进行分隔
- 函数调用中,传入的1和2称之为:实际参数(实参),表示函数执行时真正使用的参数值
- 传入的时候,按照顺序传入数据,使用逗号分隔
- 传入参数的数量是不受限制的
- 可以不使用参数
- 也可以仅使用任意n个参数
案例:升级版自动查核酸
定义一个函数,名称任意,并接受一个参数传入(数字类型,表示体温)
在函数内进行提问判断(正常范围:小于等于37.5度),并输出如下内容:
欢迎来到黑马程序员!请出示您的健康码以及72小时核酸证明,并配合测量体温!
体温测量中,您的体温是:37.3度,体温正常请进!
欢迎来到黑马程序员!请出示您的健康码以及72小时核酸证明,并配合测量体温!
体温测量中,您的体温是:39.3度,需要隔离!
1 | # 定义函数 |
4.4 函数的返回值
4.4.1 函数返回值的定义语法
返回值语法:
def 函数名(传入参数):
函数体
return 返回值
变量 = 函数(参数)
示例:
定义一个函数,完成两数相加的功能,并返回结果
1 | # 定义函数 |
注:函数体在遇到return后就结束了,所以写在return后的代码不会执行
4.4.2 None类型
Python中有一个特殊的字面量:None,其类型是<class ‘NoneType’>
无返回值的函数,实际就是返回了None这个字面量
None作为一个特殊的字面量,用于表示:空、无意义,其有非常多的应用场景。
- 用在函数无返回值上
- 用在if判断上
- 在if判断中,None等同于False
- 一般用于在函数中主动返回None,配合if判断做相关处理
- 用于声明无内容的变量上
- 定义变量,但暂时不需要变量有具体的值,可以用None代替
- name = None
4.5 函数的说明文档
函数是纯代码语言,我们可以给函数添加说明文档,辅助理解函数的作用。
语法如下:
def func(x, y):
“”"
函数说明
:param x: 形参x的说明
:param y: 形参y的说明
:return: 返回值的说明
“”"
函数体
return 返回值
- 通过多行注释的形式对函数进行说明解释
- 内容应写在函数体之前
示例:
1 | # 定义函数 |
效果如下: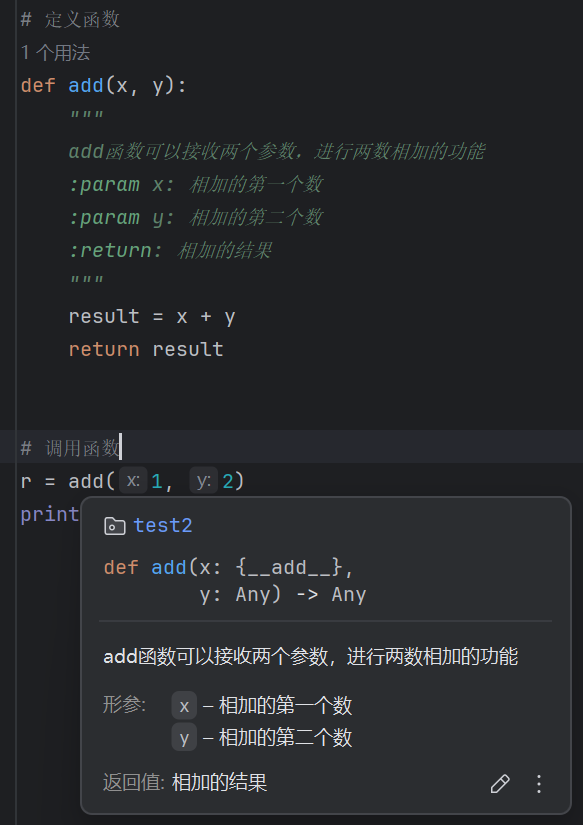
4.6 函数的嵌套调用
- 嵌套调用是指:一个函数里又调用了另一个函数
- 调用流程:函数A执行到调用函数B的语句,会将函数B全部执行完成后,继续执行函数A的剩余部分
示例:
1 | # 定义函数func_b |
打印结果为:
1 | ---1--- |
4.7 变量的作用域
变量的作用域指的是变量的作用范围(变量在哪里可用,在哪里不可用)
主要分为两类:
- 局部变量:定义在函数体内部的变量,即只在函数体内部生效
- 全局变量:在函数体内、外都能生效的变量
global关键字:在函数内部声明变量为全局变量
示例:
1 | # global关键字的使用 |
打印结果为:
1 | 100 |
4.8 综合案例:黑马ATM
- 主菜单效果
-
--------------------主菜单------------------- 周杰伦,您好,欢迎来到黑马银行ATM,请选择操作: 查询余额 [输入1] 存款 [输入2] 取款 [输入3] 退出 [输入4] 请输入您的选择: - 查询余额效果:
-
--------------------查询余额-------------------- 周杰伦,您好,您的余额剩余:5000000元 - 存、取款效果:
1
2
3--------------------存款--------------------
周杰伦,您好,您存款50000元成功
周杰伦,您好,您的余额剩余:5050000元1
2
3--------------------取款--------------------
周杰伦,您好,您取款50000元成功
周杰伦,您好,您的余额剩余:4950000元
要求:
- 定义一个全局变量:money,用来记录银行卡余额(默认5000000)
- 定义一个全局变量:name,用来记录客户姓名(启动程序时输入)
- 定义如下的函数:
- 查询余额函数
- 存款函数
- 取款函数
- 主菜单函数
- 要求:
- 程序启动后要求输入客户姓名
- 查询余额,存款后都会返回主菜单
- 存款、取款后,都应显示一下当前余额
- 客户选择退出或输入错误,程序会退出,否则一直运行
具体实现代码:
1 | # 黑马ATM |
五、Python数据容器
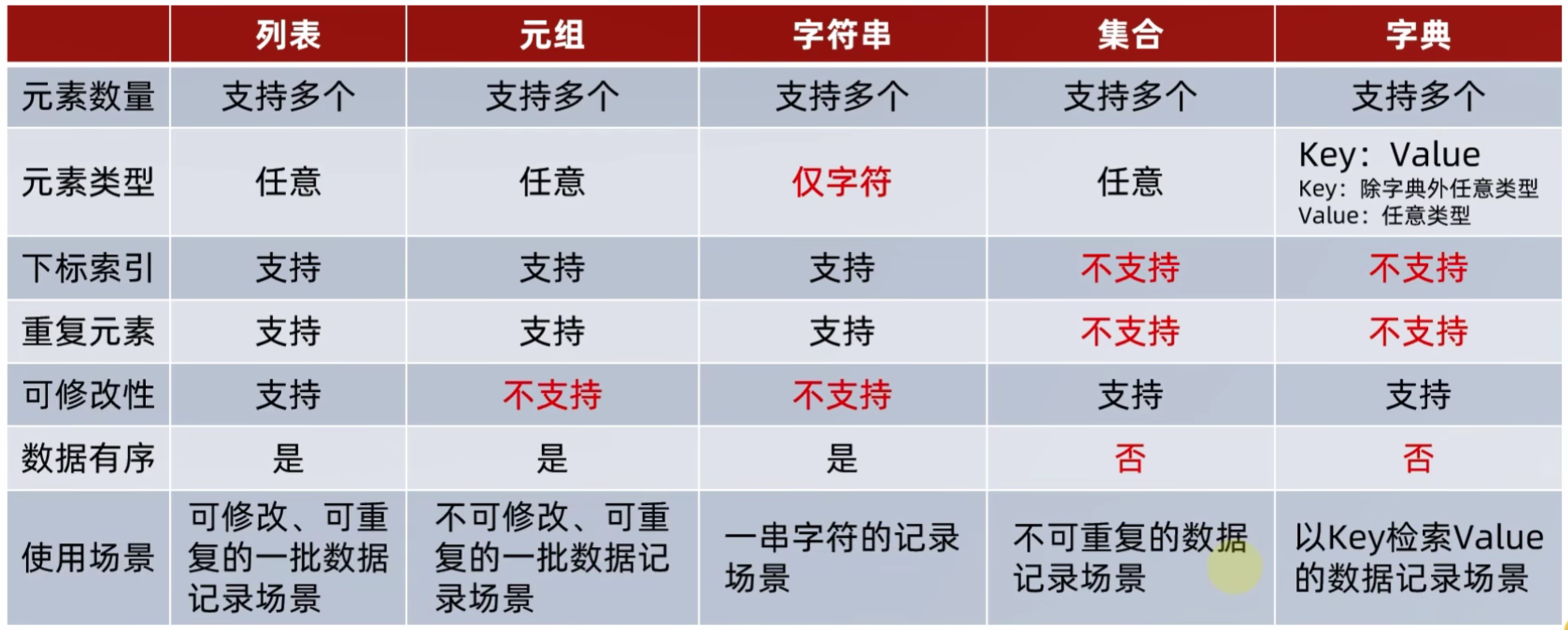
5.1 Python数据容器入门
Python中的数据容器:
一种可以容纳多份数据的数据类型,容纳的每一份数据称之为一个元素,每一个元素可以使任意类型的数据,如字符串、数字、布尔等。
数据容器根据特点的不同,如:
- 是否支持重复元素
- 是否可以修改
- 是否有序,等
分为5类,分别是:
列表(list)、元组(tuple)、字符串(str)、集合(set)、字典(dict)
5.2 数据容器:list(列表)
列表(list)类型是数据容器的一类,它可以一次性存储多个数据。
基本语法:
# 字面量
[元素1, 元素2, 元素3, 元素4, …]
# 定义变量
变量名称 = [元素1, 元素2, 元素3, 元素4, …]
# 定义空列表
变量名称 = []
变量名称 = list()
列表内的每一个数据,称之为元素:
- 以[]作为标识
- 列表内每一个元素之间用, 逗号隔开
案例演示:
1 | # 列表内的元素类型相同 |
打印结果为:
1 | ['itheima', 'itcast', 'python'] |
5.3 列表的遍历
列表的遍历可以使用下标索引

如图,列表中的每一个元素都有其位置下标索引,从前往后的方向,从0开始依次递增
语法:
1 | # 语法: 列表[下标索引] |
打印结果为:
1 | Tom |
或者,列表也可以进行反向索引,也就是从后往前:从-1开始,依次递减(-1, -2, -3, …)

语法:
1 | # 语法: 列表[下标索引] |
打印结果为:
1 | Rose |
嵌套列表的下标(索引)
如果列表是嵌套的列表,同样支持下标索引,类似C语言中的二维数组
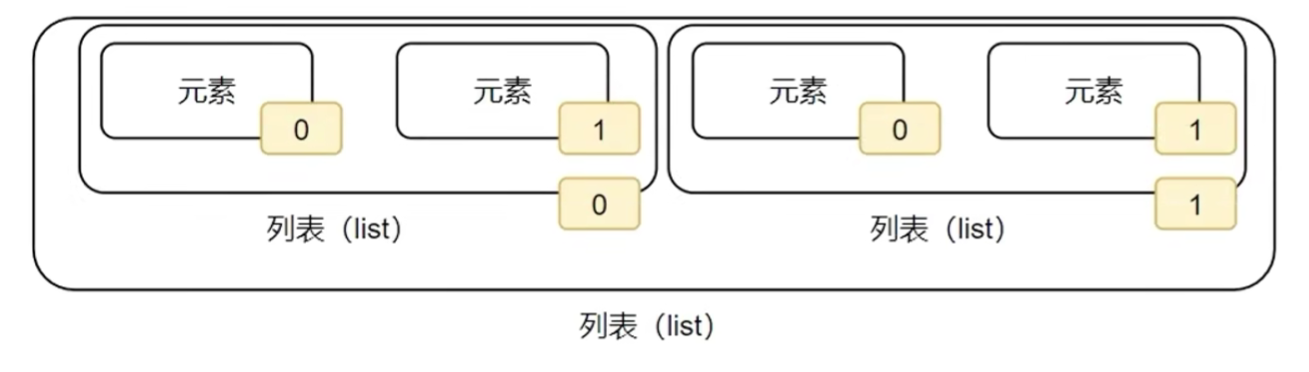
语法:
1 | # 语法: 列表[下标索引] |
打印结果为:
1 | 1 |
5.4 列表的常用操作
列表除了可以:
- 定义
- 使用下标索引获取值
此外,列表也提供了一系列功能:
- 插入元素
- 删除元素
- 清空列表
- 修改元素
- 统计元素个数
等等功能,这些功能我们都称之为:列表的方法
在Python中,如果将函数定义为class(类)的成员,那么函数会称之为:方法,如:
1 | # 函数 |
方法和函数功能一样,有传入参数,有返回值,只是方法的使用格式不同:
- 函数的使用:num = add(1, 2)
- 方法的使用:student = Student()
num = student.add(1, 2)
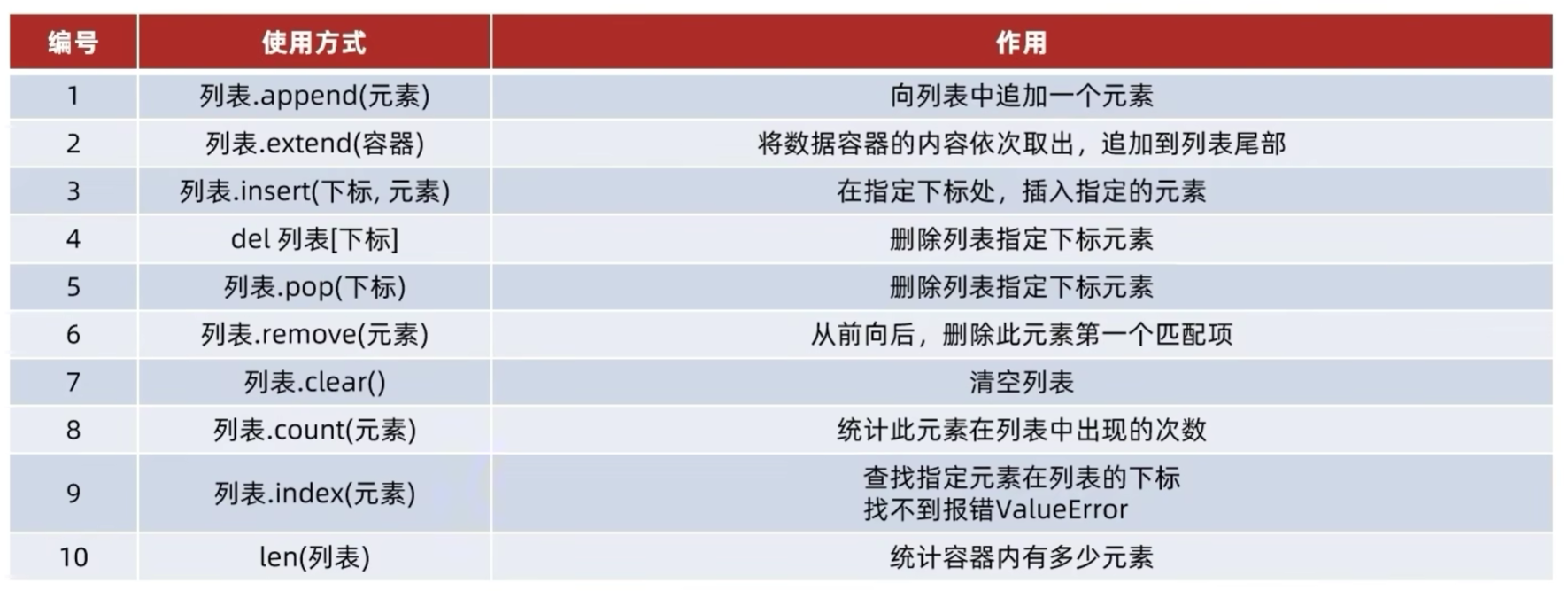
5.4.1 index查询方法
- 查询某元素的下标
功能:查找指定元素在列表中的下标,如果找不到,报错ValueError
语法:列表.index(元素)
index就是列表对象(变量)内置的方法(函数)
示例:
1 | # 列表的查询功能 |
打印结果为:
1 | 'itcast'在列表中的下标索引值是:1 |
5.4.2 列表修改方法
5.4.2.1 修改特定位置(索引)的元素值:
语法:列表[下标] = 值
可以使用如上语法,直接对指定下标(正向、反向下标均可)的值进行重新赋值(修改)
示例:
1 | # 列表的修改功能 |
打印结果为:
1 | 列表修改元素后为:['itheima', 'itcast', 'java'] |
5.4.2.2 insert插入方法:
语法:列表.insert(下标, 元素),在指定的下标位置插入指定的元素
示例:
1 | # 列表的插入功能 |
打印结果为:
1 | 列表插入元素后为:['itheima', 'java', 'itcast', 'python'] |
5.4.2.3 append追加元素方法:
语法:列表.append(元素),将指定元素追加到列表的尾部
示例:
1 | # 列表的追加功能1 |
打印结果为:
1 | 列表追加元素后为:['itheima', 'itcast', 'python', 'java'] |
5.4.2.4 extend追加元素方法:
语法:列表.extend(其他数据容器),将其他数据容器的内容取出,依次追加到列表的尾部
示例:
1 | # 列表的追加功能2 |
打印结果为:
1 | 列表在追加了一个新的列表后为:[1, 2, 3, 4, 5, 6] |
5.4.2.5 del删除方法
语法1:del 列表[下标]
语法2:列表.pop(下标)
示例:
1 | # 删除元素 |
打印结果为:
1 | 列表删除元素后为:[2, 3] |
5.4.2.6 remove删除某元素在列表中的第一个匹配项
语法:列表.remove(元素)
示例:
1 | # 列表删除第一个匹配项 |
打印结果为:
1 | 列表删除第一个匹配项后为:[1, 3, 2, 3] |
5.4.2.7 clear清空列表方法
语法:列表.clear()
示例:
1 | # 清空列表 |
打印结果为:
1 | 清空列表后为:[] |
5.4.2.8 count统计数量方法
语法:列表.count(元素)
示例:
1 | # 统计某个元素数量 |
打印结果为:
1 | 列表中'2'的数量为:3 |
5.4.2.9 len统计长度方法
语法:len(列表)
示例:
1 | # 统计列表所有元素数量 |
打印结果为:
1 | 列表中所有元素的数量为:6 |
5.5 列表的常用操作练习
有一个列表,内容是:[21, 25, 21, 23, 22, 20],记录的是一批学生的年龄
请通过列表的功能(方法),对其进行:
- 定义这个列表,并用变量接收它
- 追加一个数字31,到列表的尾部
- 追加一个新列表[29, 33, 30],到列表的尾部
- 取出第一个元素(应是:21)
- 取出最后一个元素(应是:30)
- 查找元素31,在列表中的下标位置
具体代码实现:
1 | # 定义列表 |
打印结果为:
1 | 列表中的第一个元素是:21 |
5.6 列表的遍历
5.6.1 while循环遍历列表
语法:
index = 0
while index < len(列表):
元素 = 列表[index]
对元素进行处理
index += 1
示例:
1 | # while循环遍历列表 |
打印结果为:
1 | itheima |
5.6.2 for循环遍历列表
语法:
for 临时变量 in 变量容器:
对临时变量进行处理
示例:
1 | # for循环遍历列表 |
打印结果为:
1 | 1 |
5.6.3 while循环与for循环的区别
- 在循环控制上:
- while循环可以自定循环条件,并自行控制
- for循环不可以自定循环条件,只可以一个个从容器内取出数据
- 在无限循环上:
- while循环可以通过条件控制做到无限循环
- for循环理论上不可以,因为被遍历的容器容量不是无限的
- 在使用场景上:
- while循环适用于任何可以想要循环的场景
- for循环适用于遍历数据容器的场景或简单的固定次数循环场景
5.7 数据容器:tuple(元组)
元组同列表一样,都是可以封装多个、不同类型的元素在内。
但最大的不同点在于:元组一旦定义完成就不可以修改,相当于一个只读的列表
基本语法:
元组定义:定义元组使用小括号,且使用逗号隔开各个数据,数据可以是不同的数据类型
# 定义元组字面量
(元素, 元素, …, 元素)
# 定义元组变量
变量名称 = (元素, 元素, …, 元素)
# 定义空元组
变量名称 = ()
变量名称 = tuple()
示例:
1 | # 定义元组 |
打印结果为:
1 | t1的类型是<class 'tuple'>,内容是(1, 'python', True) |
注意:元组只有一个数据时,这个数据后面要添加逗号
1 | # 定义1个元素的元组 |
打印结果为:
1 | t4的类型是<class 'tuple'>,内容是('python',) |
元组也支持嵌套:
1 | # 元组的嵌套 |
打印结果为:
1 | t5的类型是<class 'tuple'>,内容是((1, 2, 3), (4, 5, 6)) |
5.8 元组的常用操作
元组常用方法:

5.8.1 index查询方法
语法:
变量 = 元组.index(元素)
示例:
1 | # index查找方法 |
打印结果为:
1 | 在元组t1中查找1的下标是:0 |
5.8.2 count统计数量方法
语法:
变量 = 元组.count(元素)
示例:
1 | # count统计方法 |
打印结果为:
1 | 元组t1中共有元素'python'3个 |
5.8.3 len统计长度方法
语法:
变量 = len(元组)
示例:
1 | # len统计元组元素数量方法 |
打印结果为:
1 | 元组t1中共有元素5个 |
5.9 元组的遍历
5.9.1 while循环遍历元组
语法:
index = 0
while index < len(元组):
元素 = 元组[index]
对元素进行处理
index += 1
示例:
1 | # while循环遍历列元组 |
打印结果为:
1 | 元组t1中有元素:1 |
5.9.2 for循环遍历元组
语法:
for 临时变量 in 变量容器:
对临时变量进行处理
示例:
1 | # for循环遍历元组 |
打印结果为:
1 | 元组t1中有元素:1 |
注:不可修改元组的内容,但可以修改元组内的list的内容(增删改查等),如t1 = (1, 2, [‘itheima’, ‘itcast’])
5.10 数据容器:字符串(string)
字符串是字符的容器,和其他容器一样,字符串也可以通过下标进行访问:
- 从前往后,下标从0开始
- 从后往前,下标从-1开始
示例:
1 | # 通过下标索引取值 |
打印结果为:
1 | 从字符串itheima and itcast取下标为2的元素是:h,从字符串itheima and itcast取下标为-16的元素是:h |
注:同元组一样,字符串是一个不可修改的数据容器
5.11 字符串的常用操作
字符串常用方法:
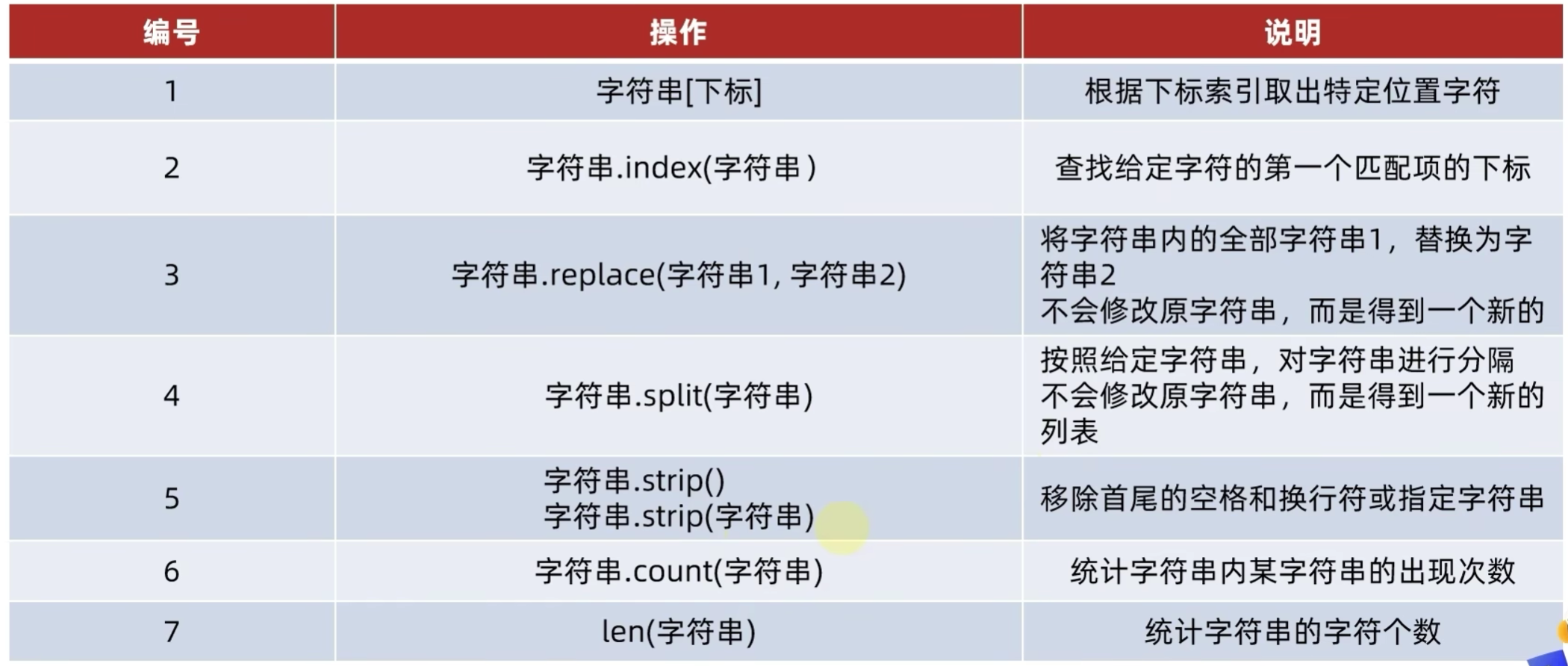
5.11.1 index查询方法
语法:
变量 = 字符串.index(元素)
示例:
1 | # index查询方法 |
打印结果为:
1 | 在字符串itheima and itcast中查找'and',其下标为:8 |
5.11.2 replace替换方法
语法:
新字符串 = 字符串.replace(字符串1, 字符串2)
功能:将字符串内的全部字符串1,替换为字符串2
注意:不是修改字符串本身,而是得到了一个新的字符串
示例:
1 | # replace替换方法 |
打印结果为:
1 | 替换后的新字符串为:程序heima and 程序cast |
5.11.3 split分割方法
语法:
字符串.split(分隔符字符串)
功能:按照指定的分隔符字符串,将字符串划分为多个字符串,并存入列表对象中
注意:字符串本身不变,而是得到了一个列表对象
示例:
1 | # split分割方法 |
打印结果为:
1 | 将字符串hello itheima and itcast进行split分割后得到:['hello', 'itheima', 'and', 'itcast'],其类型为:<class 'list'> |
5.11.4 strip规整方法
5.11.4.1 字符串的规整操作(去前后空格)
语法:
字符串.strip()
示例:
1 | # strip规整操作 (去前后空格) |
打印结果为:
1 | 字符串 itheima and itcast 规整后为:itheima and itcast |
5.11.4.2 字符串的规整操作(去前后指定字符串)
语法:
字符串.strip(字符串)
示例:
1 | # strip规整操作2(去前后指定字符串) |
打印结果为:
1 | 字符串12itheima and itcast21规整后为:itheima and itcast |
注:传入的是"12"其实就是:"1"和"2"都会移除,是按照单个字符
5.11.5 count统计数量方法
语法:
变量 = 字符串.count(元素)
示例:
1 | # count统计数量方法 |
打印结果为:
1 | 字符串itheima and itcast中共有元素'i'3个 |
5.11.6 len统计长度方法
语法:
变量 = len(字符串)
示例:
1 | # len统计元组元素数量方法 |
打印结果为:
1 | 字符串itheima and itcast中共有元素18个 |
5.12 字符串的遍历
5.12.1 while循环遍历字符串
语法:
index = 0
while index < len(字符串):
元素 = 字符串[index]
对元素进行处理
index += 1
示例:
1 | # while循环遍历列字符串 |
打印结果为:
1 | 元组t1中有元素:i |
5.12.2 for循环遍历元组
语法:
for 临时变量 in 变量容器:
对临时变量进行处理
示例:
1 | # for循环遍历字符串 |
打印结果为:
1 | 字符串itheima中有元素:i |
5.13 字符串基本操作练习案例
给定一个字符串:“itheima itcast boxuegu”
- 统计字符串中有多少个"it"字符
- 将字符串内的空格全部替换为字符"|"
- 并按照"|"进行字符串分割,得到列表
具体实现代码如下:
1 | my_str = "itheima itcast boxuegu" |
打印结果如下:
1 | 该字符串中有2个'it'字符 |
5.14 序列及其切片操作
序列:指内容连续有序,可使用下标索引的一类数据容器
列表、元组、字符串均可视为序列
序列的常用操作:切片
序列支持切片,即:列表、元组、字符串均支持切片操作
切片:从一个序列中取出一个子序列
语法:
序列[起始下标:结束下标:步长]
表示从序列中,从指定位置开始,依次取出元素,到指定位置结束,得到一个新序列:
- 起始下标表示从何处开始,可以留空,留空视作从头开始
- 结束下标(不含)表示何处结束,可以留空,留空视作截取到结尾
- 步长表示依次取元素的间隔:
- 步长1表示一个个取元素
- 步长2表示每次跳过1个元素取
- 步长N表示每次跳过N-1个元素取
- 步长为负数表示反向取(注意,起始下标和结束下标也要反向标记)
- 此操作不影响序列本身,而是得到了一个新的序列
示例:
1 | # 对列表list进行切片 |
打印结果为:
1 | 切片得到的新列表为:[1, 2, 3] |
5.15 数据容器:set(集合)
集合:不支持元素重复,且无法保证元素有序,但集合允许修改
基本语法:
# 定义集合字面量
{元素, 元素, …, 元素}
# 定义集合变量
变量名称 = {元素, 元素, …, 元素}
# 定义空变量
变量名称 = set()
示例
1 | # 定义集合 |
打印结果为:
1 | my_set的内容是:{'python', 'itcast', 'itheima'},它的类型是<class 'set'> |
5.16 集合的常用操作
集合常用方法:
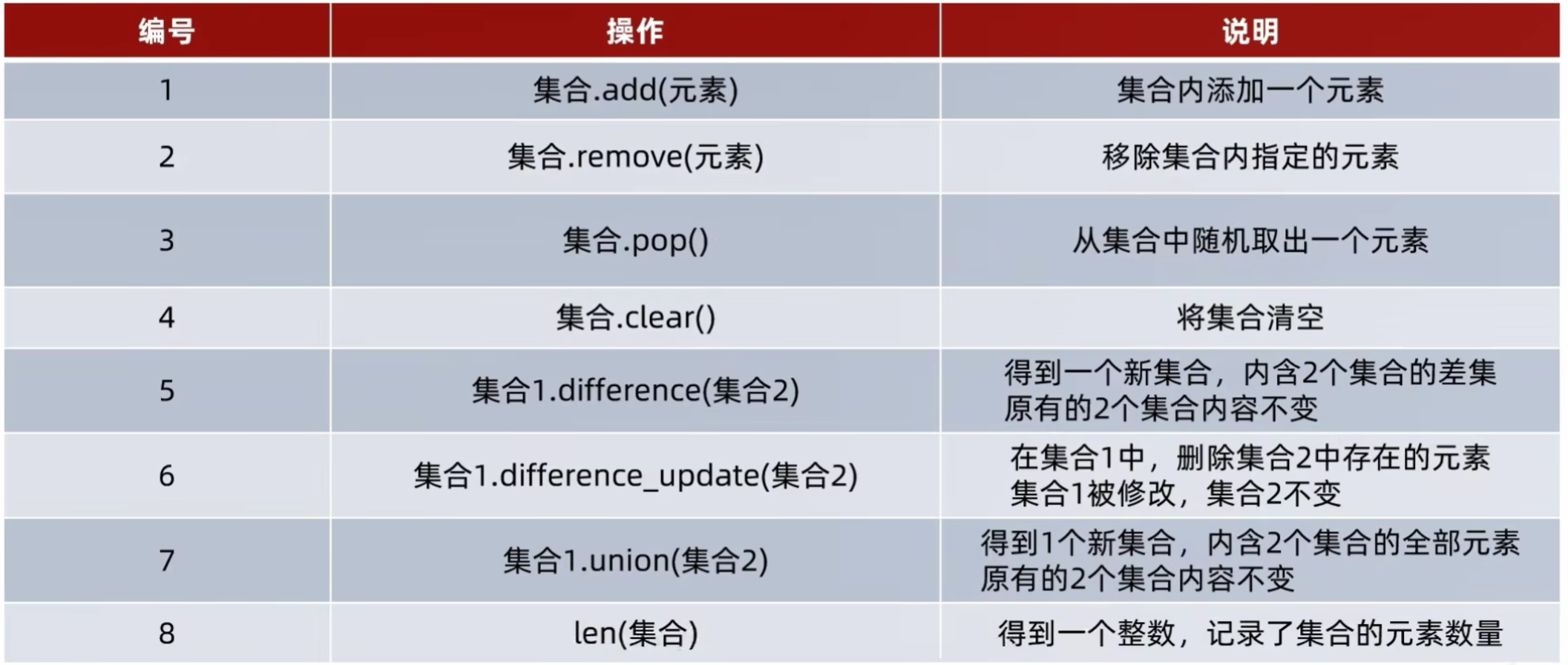
5.16.1 add添加方法
语法:
集合.add(元素)
示例:
1 | # add添加方法 |
打印结果为:
1 | 集合my_set添加新元素后为:{'itcast', 'itheima', 'python', 'java'} |
5.16.2 remove移除方法
语法:
集合.remove(元素)
示例:
1 | # remove移除方法 |
打印结果为:
1 | 集合my_set移除元素后为:{'itcast', 'itheima'} |
5.16.3 pop取出方法
语法:
集合.pop()
功能:从集合中随机取出一个元素,同时将该元素从集合中删除
示例:
1 | # pop取出元素方法 |
打印结果为:
1 | 从集合my_set中取出的元素为:itheima,取出该元素后集合为:{'itcast', 'python'} |
5.16.4 clear清空方法
语法:
集合.clear()
示例:
1 | # clear清空方法 |
打印结果为:
1 | 集合my_set清空后为:set() |
5.16.5 difference差集方法
语法:
集合1.difference(集合2)
功能:取出集合1和集合2的差集(集合1有的而集合2没有的),集合1和集合2不变
示例:
1 | # difference差集方法 |
打印结果为:
1 | 集合my_set1清与集合my_set2的差集为:{'c'} |
5.16.6 difference_update消除差集方法
语法:
集合1.difference_update(集合2)
功能:对比集合1和集合2,在集合1内,删除和集合2相同的元素
示例:
1 | # difference_update消除差集方法 |
打印结果为:
1 | 消除集合my_set1与集合my_set2的差集后my_set1变为:{'c'} |
5.16.7 union合并方法
语法:
集合1.union(集合2)
功能:将集合1和集合2合并后得到一个新集合,集合1和集合2不变
示例:
1 | # union合并方法 |
打印结果为:
1 | 集合my_set1与集合my_set2的合并后为:{'java', 'itheima', 'c', 'python', 'itcast'} |
5.16.8 len统计长度方法
语法:
len(集合)
示例:
1 | # len统计长度方法 |
打印结果为:
1 | 集合my_set的长度为为:4 |
5.17 集合的遍历
由于集合不支持下标索引,所以只能使用for循环进行遍历
语法:
for 临时变量 in 变量容器:
对临时变量进行处理
示例:
1 | # 集合遍历 |
打印结果为:
1 | 集合my_set中有元素:c |
5.18 集合基本操作练习案例
信息去重:
有如下列表对象:
my_list = [‘黑马程序员’, ‘传智播客’, ‘黑马程序员’, ‘传智播客’, ‘itheima’, ‘itcast’, ‘itheima’, ‘itcast’, ‘best’]
请:
- 定义一个空集合
- 通过for循环遍历列表
- 在for循环中将列表的元素添加至集合
- 最终得到的元素去重后的集合对象,并打印输出
具体实现代码如下:
1 | # 练习案例 |
打印结果为:
1 | ----------列表--------- |
5.19 数据容器:dict(字典、映射)
字典:可以按照[Key]找出对应的[Value],其中[Key]不可以重复,后面的[Key]会覆盖前面的[Key]
基本语法:
# 定义字典字面量
{key: value, key: value, …, key:value}
# 定义字典变量
my_dict = {key: value, key: value, …, key:value}
# 定义空字典
my_dict = {}
my_dict = dict()
示例:
1 | # 定义字典 |
打印结果为:
1 | 字典0的内容是:{'小明': 99, '小红': 88, '小强': 77},字典0的类型是:<class 'dict'> |
5.20 字典数据的获取
语法:
字典[Key]
示例:
1 | # 字典数据的获取 |
打印结果为:
1 | 字典中'小明'对应的值为:99 |
5.21 字典的嵌套
字典的Key和Value可以使任意数据类型(Key不可以是字典)
示例:
记录表格:
| 姓名 | 语文 | 数学 | 英语 |
|---|---|---|---|
| 小明 | 77 | 66 | 33 |
| 小红 | 88 | 86 | 55 |
| 小强 | 99 | 96 | 66 |
1 | # 字典的嵌套 |
打印结果为:
1 | 学生的考试成绩是:{'小明': {'语文': 77, '数学': 66, '英语': 33}, '小红': {'语文': 88, '数学': 86, '英语': 55}, '小强': {'语文': 99, '数学': 96, '英语': 66}} |
5.22 从嵌套字典中获取数据
语法:
字典[Key][Key对应的Value中的Key]
示例:
1 | # 获取嵌套字典的数据 |
打印结果为:
1 | 小明的数学成绩为:66 |
5.23 字典的常用操作
字典常用方法:
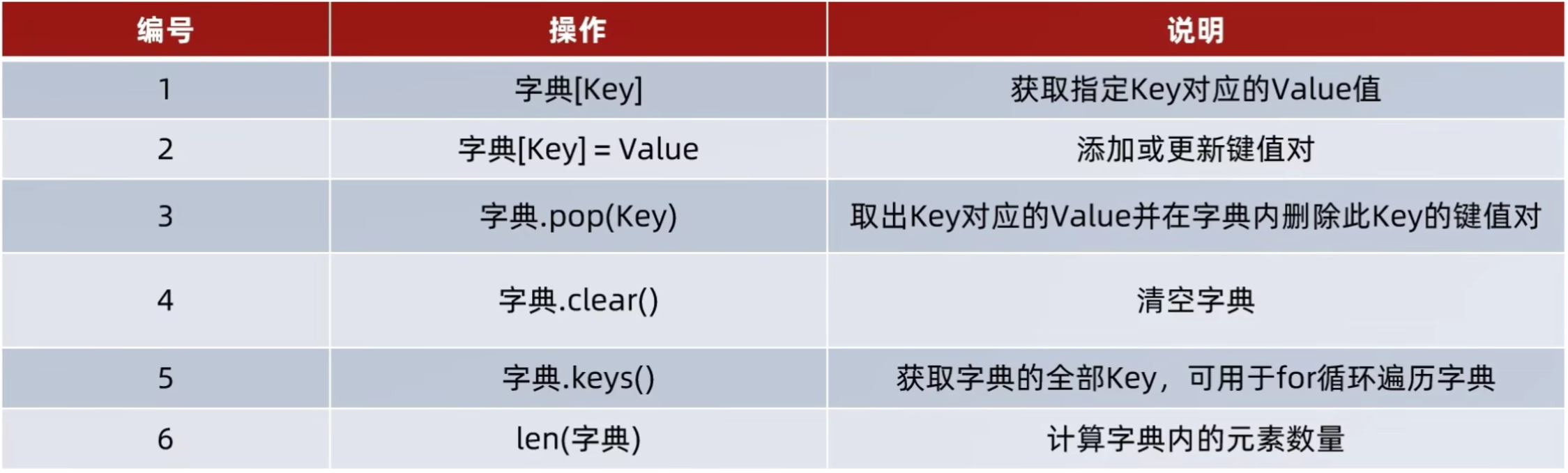
5.23.1 新增元素方法
语法:
字典[Key] = Value
示例:
1 | # 字典添加数据 |
打印结果为:
1 | 字典的内容为:{'小明': 99, '小红': 88, '小强': 77, '小绿': 66} |
5.23.2 更新元素方法
语法:
字典[Key] = Value
示例:
1 | # 字典更新数据 |
打印结果为:
1 | 字典更新后的内容为:{'小明': 66, '小红': 88, '小强': 77} |
5.23.3 pop删除方法
语法:
字典.pop(Key)
功能:获得指定的Key的Value,同时字典被修改,指定的Key的数据被删除
示例:
1 | # 字典删除数据 |
打印结果为:
1 | 字典更新后的内容为:{'小红': 88, '小强': 77} |
5.23.4 clear清空方法
语法:
字典.clear()
示例:
1 | # 字典清空方法 |
打印结果为:
1 | 字典更新后的内容为:{} |
5.23.5 keys获取全部Key方法
语法:
字典.keys()
示例:
1 | # 获取字典全部key方法 |
打印结果为:
1 | 字典中的所有key为:dict_keys(['小明', '小红', '小强']) |
5.23.6 len统计长度方法
语法:
len(字典)
示例:
1 | # len统计字典长度 |
打印结果为:
1 | 字典中共有3个元素 |
5.24 字典的遍历
方法1:通过keys进行遍历
for key in keys:
print(f"字典的value是:{my_dict[key]}")
示例:
1 | # 字典的遍历 |
打印结果为:
1 | 字典的key是:小明 |
方法2:直接对字典进行for循环
语法:
for key in my_dict:
print(f"字典的value是:{my_dict[key]}")
示例:
1 | # 字典的遍历 |
打印结果为:
1 | 字典的key是:小明 |
5.25 五种数据容器总结
数据容器可以从以下视角进行简单的分类:
- 是否支持下标索引:
- 支持:列表、元组、字符串 - 序列类型
- 不支持:集合、字典 - 非序列类型
- 是否支持重复元素:
- 支持:列表、元组、字符串 - 序列类型
- 不支持:集合、字典 - 非序列类型
- 是否可以修改:
- 支持:列表、集合、字典
- 不支持:元组、字符串
5.26 容器通用操作
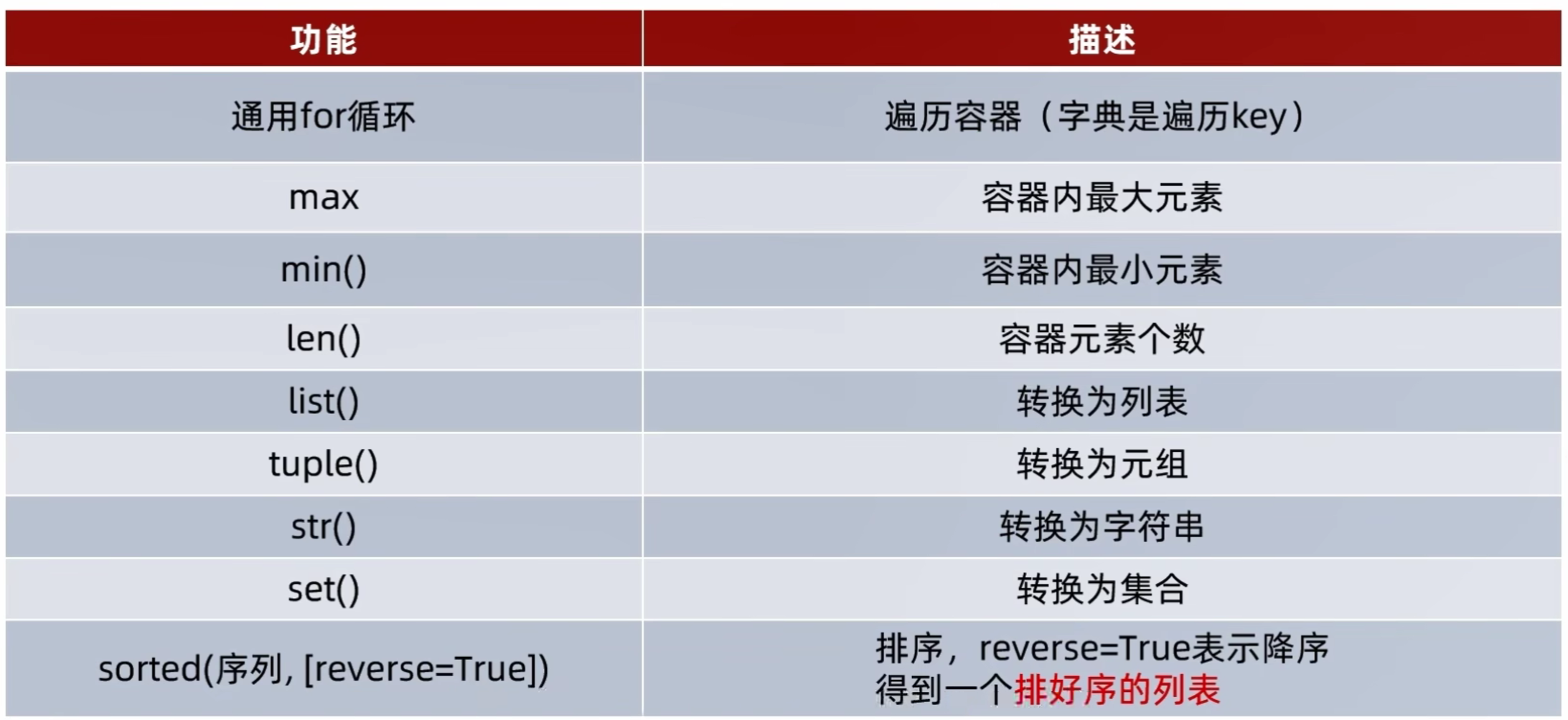
sorted通用排序操作:
语法:
sorted(容器, [reverse=True])
功能:对容器内元素进行排序,排序之后全部变为列表对象,reverse=True为正向排序,reverse=False为逆向排序
示例:
1 | # sorted排序方法 |
打印结果为:
1 | 列表对象的排序结果为:[1, 2, 3, 4, 5] |
六、Python函数进阶
6.1 函数的多返回值
语法:
return 返回值1, 返回值2, …
按照返回值的顺序,写对应多个变量进行接收即可,变量之间用逗号隔开,支持不同类型的数据return
示例:
1 | # 多返回值 |
打印结果为:
1 | a的值为:1,b的值为:True |
6.2 多种传参方式
函数参数种类:
根据使用方式上的不同,函数常见的参数使用方式可分为4种:
- 位置参数
- 关键字参数
- 缺省参数
- 不定长参数
6.2.1 位置参数
位置参数:调用函数时根据函数定义的参数位置来传递参数
注意:传递的参数和定义的参数顺序及个数必须一致
示例:
1 | # 位置参数 |
打印结果为:
1 | 您的名字是Tom, 年龄是:20, 性别是:男 |
6.2.2 关键字参数
关键字参数:函数调用时通过“键=值”形式传递参数
注意:函数调用时,如果有位置参数时,位置参数必须在关键字参数前面,但关键字参数之间不存在先后顺序
示例:
1 | # 关键字参数 |
打印结果为:
1 | 您的名字是Tom, 年龄是:20, 性别是:男 |
6.2.3 缺省参数
缺省参数:缺省参数也叫默认参数,用于定义函数,为参数提供默认值,调用函数时可不传该默认参数的值,当调用函数没有传递参数时,就会默认使用缺省参数对应的值
注意:所有位置参数必须出现在默认参数之前,包括函数定义和调用
示例:
1 | # 缺省参数 |
打印结果为:
1 | 您的名字是Tom, 年龄是:20, 性别是:男 |
6.2.4 不定长参数
不定长参数:不定长参数也叫做可变参数,用于不确定调用的时候会传递多少个参数(不传参也可以)的场景
作用:当调用函数时不确定参数个数时,可以使用不定长参数
不定长参数的类型:
- 位置传递
- 关键字传递
6.2.4.1 位置传递不定长参数
示例:
1 | # 位置传递不定长参数 |
打印结果为:
1 | args参数的类型为:<class 'tuple'>,内容是:('TOM',) |
注:传进的所有参数都会被args变量收集,它会根据传进参数的位置合并为一个元组(tuple),args是元组类型,这就是位置传递
6.2.4.2 关键字传递不定长参数
示例:
1 | # 关键字传递不定长参数 |
打印结果为:
1 | kwargs参数的类型为:<class 'dict'>,内容是:{'name': 'TOM', 'age': 18, 'id': 110} |
注:参数是“键=值”形式的情况下,所有的“键=值”都会被kwargs接受,同时会根据“键=值”组成字典
6.3 函数作为参数传递
函数也可以作为参数传入另一个函数,如下代码:
1 | def test_func(compute): |
其中,函数compute作为参数传入了test_func函数中使用:
- test_func需要一个函数作为参数传入,这个函数需要接收2个数字进行计算,计算逻辑由这个被传入的函数决定
- compute函数接收这2个数字对其进行计算,compute函数作为参数,传递给了test_func函数使用
- 最终,在test_func函数内部,由传入的compute函数完成了对数字的计算操作
其实,这是一种计算逻辑的传递,而非数据的传递,任何逻辑都可以自行定义并作为函数传入
上述示例打印结果为:
1 | compute的类型为:<class 'function'> |
注:将函数传入的作用在于:传入计算逻辑,而非传入数据
6.4 lambda匿名函数
函数的定义中:
- def关键字,可以定义带有名称的函数
- lambda关键字,可以定义匿名函数(无名称)
有名称的函数,可以基于名称重复使用
无名称的函数,只可临时使用一次
匿名函数定义语法:
lambda 传入参数: 函数体(一行代码)
- lambda是关键字,表示定义匿名函数
- 传入参数表示匿名函数的形式参数,如:x,y表示接收2个形式参数
- 函数体,就是函数的执行逻辑,要注意:只能写一行,无法写多行代码
示例:
1 | def test_func(compute): |
打印结果为:
1 | 计算结果是:3 |
七、Python文件操作
7.1 文件编码概念
编码技术:即翻译的规则,记录了如何将内容翻译成二进制,以及如何将二进制翻译回可识别内容
计算机中有许多可用编码:
- UTF-8
- GBK
- Big5
- 等
不同的编码方式翻译结果是不同的,只有使用正确的编码才能对文件进行正确的读写
UTF-8是目前全球通用的编码格式,除非有特殊需求,否则一律以UTF-8格式进行文件编码即可
7.2 文件的读取操作
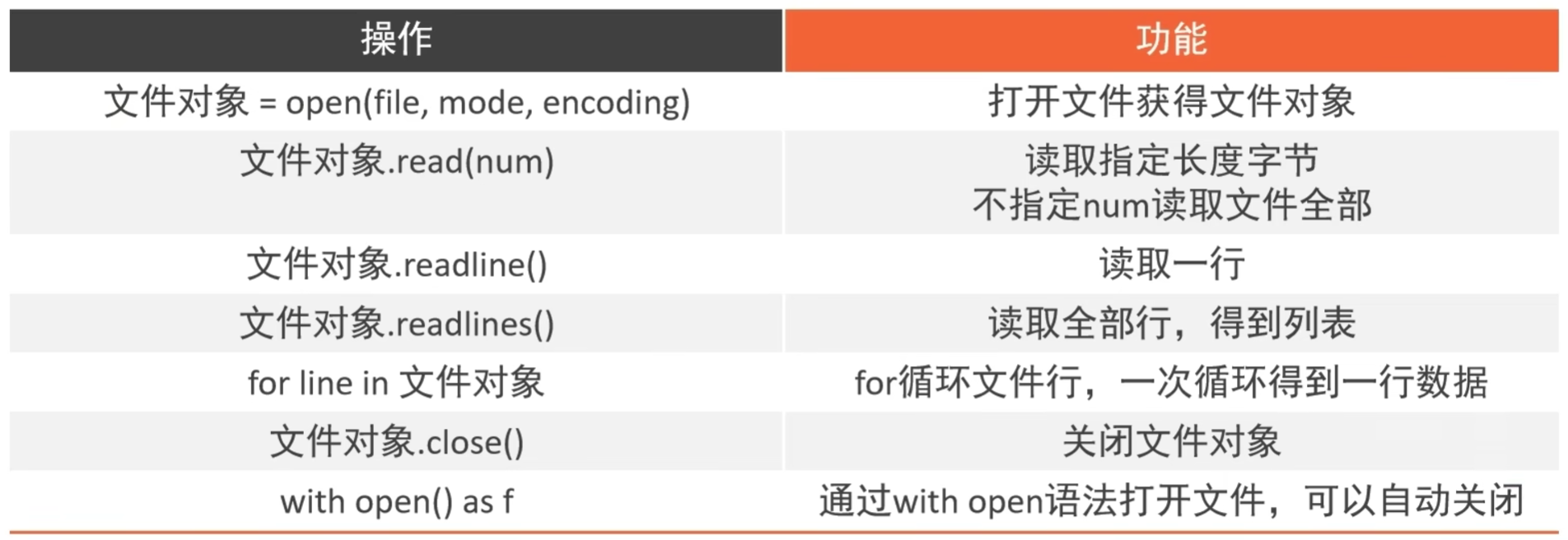
7.2.1 open()打开函数方法
语法:
open(name, mode, encoding)
其中:
- name:是要打开的目标文件名的字符串(可以包含文件所在的具体路径)
- mode:设置打开文件的模式(访问模式):只读、写入、追加等
- encoding:编码格式(推荐使用UTF-8)

示例:
1 | """ |
注:此时的’f’是’open’函数的文件对象,对象是Python中的一种特殊的数据类型,拥有属性和方法,可以使用对象.属性或对象.方法对其进行访问
7.2.2 read()、readlines()、readline()读文件方法
7.2.2.1 read()读文件方法
语法:
文件对象.read(num)
num表示要从文件中读取的数据长度(单位是字节),如果没有传入num,那么就表示读取文件中的所有数据
示例:
1 | # read()读取文件 |
打印结果为:
1 | 读取5个字节的结果为:hello |
注:在同一文件中多次调用read()方法是,下一次read调用会从上一次read调用结束处开始
7.2.2.2 readlines()读文件方法
语法:
文件对象.readlines()
readlines可以按照整行的方式把整个文件的内容一次性读取,并且返回的是一个列表,其中每一行的数据为一个元素
示例:
1 | # readlines()读取文件 |
打印结果为:
1 | lines对象的类型是:<class 'list'> |
7.2.2.3 readline()读文件方法
语法:
文件对象.readline()
readline一次读取一行内容
示例:
1 | # readline()读取文件 |
打印结果为:
1 | 文件的第一行内容为:hello1 world1 |
7.2.3 for循环读文件方法
语法:
for line in open(“D:/test.txt”, ‘r’):
print(line)
其中,每一个line临时变量都记录了文件的一行内容
示例:
1 | # for循环读取文件 |
打印结果为:
1 | 每一行的数据是:hello1 world1 |
7.2.3 close()关闭文件方法
语法:
文件对象.close()
通过close关闭文件对象也就是关闭对文件的占用
如果不调用close,同时程序没有停止运行,那么这个文件就会一直被Python程序占用
7.2.4 with open()读取并关闭文件方法
语法:
with open(“D:/test.txt”, ‘r’) as f:
f.readlines()
通过在with open的语句块中对文件进行操作,可以在操作完成后自动关闭close文件,避免遗忘掉close方法
示例:
1 | # with open()读取并关闭文件 |
打印结果为:
1 | 每一行的数据是:hello1 world1 |
7.3 文件读取操作练习案例
单词计数:
通过Windows的文件编辑软件,将如下内容复制并保存到:word.txt,文件可以存储到任意位置,通过文件读取操作,读取此文件,统计itheima单词出现的次数
itheima itcast python
itheima python itcast
beijing shanghai itheima
shenzhen guangzhou itheima
wuhan hangzhou itheima
zhengzhou bigdata itheima
具体实现代码如下:
1 | f = open("D:/word.txt", 'r', encoding='Utf-8') |
7.4 文件的写出操作
将文件写入需要使用write方法,之后使用flush刷新内容
语法:
-
打开文件
f = open(“D:/test.txt”, ‘w’, encoding=‘Utf-8’) -
文件写入
f.write(‘hello4 world4’) -
内容刷新
f.flush()
注:
- 直接调用write,内容并为真正写入文件,而是会积攒在程序的内存中,称之为缓冲区
- 当调用flush时,内容会真正写入文件
- 这样做是避免频繁地操作硬盘,导致效率下降(攒一堆,一次性写入磁盘)
示例:
1 | # 文件写入演示 |
打印结果为:
1 | 文件写入前内容为:hello world |
注:
- w模式,文件不存在时会自动创建文件
- w模式,文件存在时会清空原有内容
- close()方法,带有flush()方法的功能
7.5 文件的追加写入操作
文件追加与文件写入类似,只需要将w模式改为a模式即可
语法:
-
打开文件
f = open(“D:/test.txt”, ‘a’, encoding=‘Utf-8’) -
文件写入
f.write(‘hello4 world4’) -
内容刷新
f.flush()
示例:
1 | # 文件追加写入演示 |
打印结果为:
1 | 文件写入前内容为:hello world |
注:
- a模式,文件不存在时会自动创建文件
- a模式,文件存在时会在原有内容后继续写入
- 可以使用"\n"来写出换行符
7.6 文件操作综合案例
需求:有一份账单文件,记录了消费收入的具体记录,内容如下:
name date money type remarks
周杰轮,2022-01-01,100000,消费,正式
周杰轮,2022-01-02,300000,收入,正式
周杰轮,2022-01-03,100000,消费,测试
林俊节,2022-01-01,300000,收入,正式
林俊节,2022-01-02,100000,消费,测试
林俊节,2022-01-03,100000,消费,正式
林俊节,2022-01-04,100000,消费,测试
林俊节,2022-01-05,500000,收入,正式
张学油,2022-01-01,100000,消费,正式
张学油,2022-01-02,500000,收入,正式
张学油,2022-01-03,900000,收入,测试
王力鸿,2022-01-01,500000,消费,正式
王力鸿,2022-01-02,300000,消费,测试
王力鸿,2022-01-03,950000,收入,正式
刘德滑,2022-01-01,300000,消费,测试
刘德滑,2022-01-02,100000,消费,正式
刘德滑,2022-01-03,300000,消费,正式
先将其复制保存为bili.txt
需求:
- 读取文件
- 将文件写出到bili.txt.bak文件作为备份
- 同时,将文件内标记为测试的数据行丢弃
实现思路:
- open和r模式打开一个文件对象并读取文件
- open和w模式打开另一个文件对象,用于文件写出
- for循环内容,判断是否是测试不是测试就用write写出,是测试就continue跳过
- 将2个文件对象均close
具体实现代码如下:
1 | # f1用于读取文件 |
八、Python异常、模块与包
8.1 Python异常
异常:当检测到一个错误时,Python解释器就无法继续执行了,反而出现了一些错误提示,这就是所谓的“异常”,也就是我们常说的BUG
8.2 异常的捕获
捕获异常的作用在于:提前假设某处会出现异常,做好提前准备,当真的出现异常的时候,可以有后续手段
8.2.1 捕获异常
基本语法:
try:
可能发生错误的代码
except:
如果出现异常执行的代码
示例:
尝试用’r’模式打开文件,如果文件不存在,则以’w’模式打开
1 | try: |
8.2.2 捕获指定异常
1 | try: |
打印结果为:
1 | 出现了变量未定义的异常 |
8.2.3 捕获多个异常:
1 | try: |
打印结果为:
1 | 出现了变量未定义 或 除以0 的异常 |
8.2.4 捕获全部异常:
1 | try: |
8.2.5 异常else
else表示的是如果没有异常要执行的代码
示例:
1 | try: |
8.2.6 异常的finally
finally表示无论是否异常都要执行的代码,如关闭文件
示例:
1 | try: |
8.3 异常的传递性
异常是具有传递性的,有如下代码:
1 | # 异常的传递 |
当函数func01中发生异常,并且没有捕获处理这个异常时,异常会传递到func02,当func02也没有捕获处理这个异常时,main函数会捕获这个异常,这就是异常的传递性
当所有函数都没有捕获异常时,程序就会出错
上面代码执行结果为:
1 | 这是func02开始 |
8.4 模块的概念和导入
Python模块(Module),是一个Python文件,以.py结尾。模块能定义函数、类和变量,也能包含可执行的代码
模块的作用:模块封装了函数、类或变量,可以帮助我们快速实现一些功能
模块的导入方式:
模块在使用前需要先导入,导入的语法如下:
[from 模块名] import [模块 | 类 | 变量 | 函数 | *] [as 别名]
常用的组合形式如:
- import 模块名
- from 模块名 import 类、变量、方法等
- from 模块名 import *
- import 模块名 as 别名
- from 模块名 import 功能名 as 别名
示例:
1 | # 模块的导入 |
8.5 自定义模块并导入
8.5.1 自定义模块并导入使用
使用方法:
创建一个 模块名.py 文件,并在其中写入需要使用的类、变量或函数
调用时先import导入模块,之后就可以使用模块中的功能了

注:当导入多个模块,且模块内有同名功能,当调用这个同名功能时,调用的是后面模块的功能
示例:
1 | # 模块1 代码 |
打印结果为:
1 | 2 |
8.5.2 main变量
在模块中进行测试时,我们可能会使用模块中的功能,为了不让测试代码影响正常使用,我们可以使用main变量进行控制
语法:
if __name__ == ‘__main__’:
测试代码
实现原理:每个文件都内置了一个变量__name__,在该文件内执行时name会被赋值为main,而当在其他文件中执行时,name则不等于main,以此来实现测试代码的效果而不影响正常调用
示例:
1 | # my_module1模块中代码 |
打印结果为:
1 | 3 |
当使用main变量后:
1 | # my_module1模块中代码 |
打印结果为:
1 | 2 |
8.5.3 __all__变量
如果一个模块文件中有’__all__'变量,当使用’from xxx import *'导入时,只能导入这个列表中的元素
示例:
1 | # my_module1模块中代码 |
8.6 自定义Python包
Python包:
从物理上看,包就是一个文件夹,在该文件夹下包含了一个__init__.py文件,该文件夹可用于包含多个模块文件
从逻辑上看,包的本质依然是模块
包的作用:当我们的模块文件越来越多时,包可以帮助我们管理这些模块,包的作用就是包含多个模块,但包的本质依然是模块
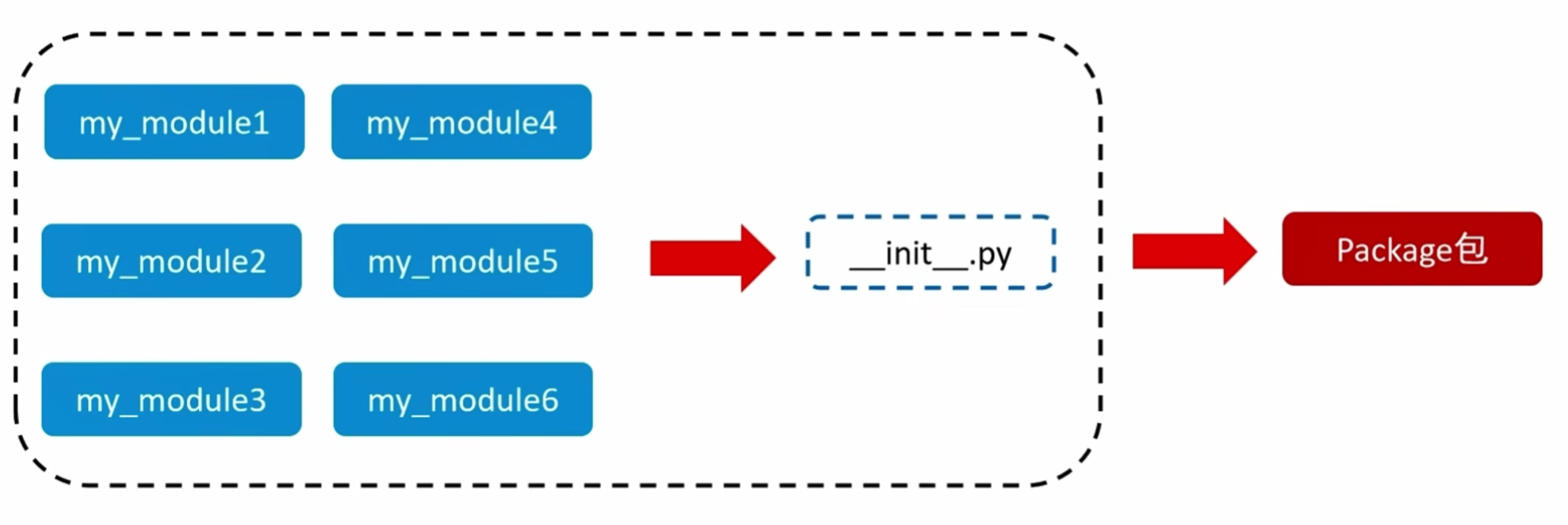
新建包步骤如下:
- 新建包’my_package’
- 新建包内模块:‘my_module1’和’my_module2’
- 模块内代码如下:
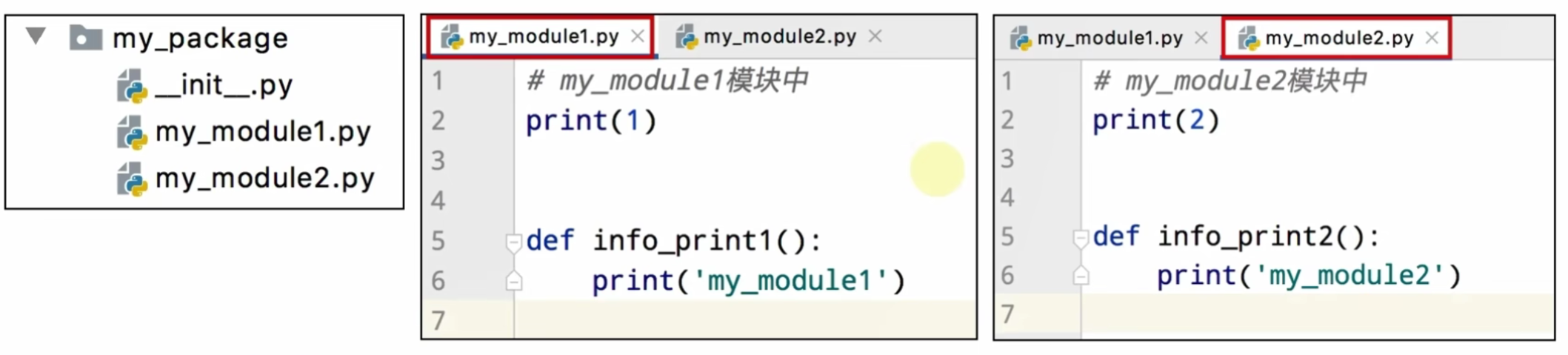
使用方式:导入包:
- 方式一:
import 包名.模块名
包名.模块名.功能
示例:
1 | # 演示自定义模块1 |
打印结果为:
1 | 模块1代码 |
- 方式二:
from 包名 import 模块名
模块名.功能
示例:
1 | # 演示自定义模块1 |
打印结果为:
1 | 模块1代码 |
注:必须在’__init__.py’文件中添加’__all__ = []',控制允许导入的模块列表(all只针对’from … import *'这种方式)
8.7 安装第三方包
使用第三方包可以极大地帮助我们提高开发效率,如:
- 科学计算中常用的:numpy包
- 数据分析中常用的:pandas包
- 大数据计算中常用的:pyspark、apache-flink包
- 图形可视化中常用的:matplotlib、pyecharts包
- 人工智能中常用的:tensorflow包
- 等
第三方包的安装方法:
在命令提示程序中输入:
pip install 包名称
即可通过网络安装第三方包
pip的网络优化
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple 包名称
https://pypi.tuna.tsinghua.edu.cn/simple 是清华大学提供的一个可使用pip下载第三方包的网站
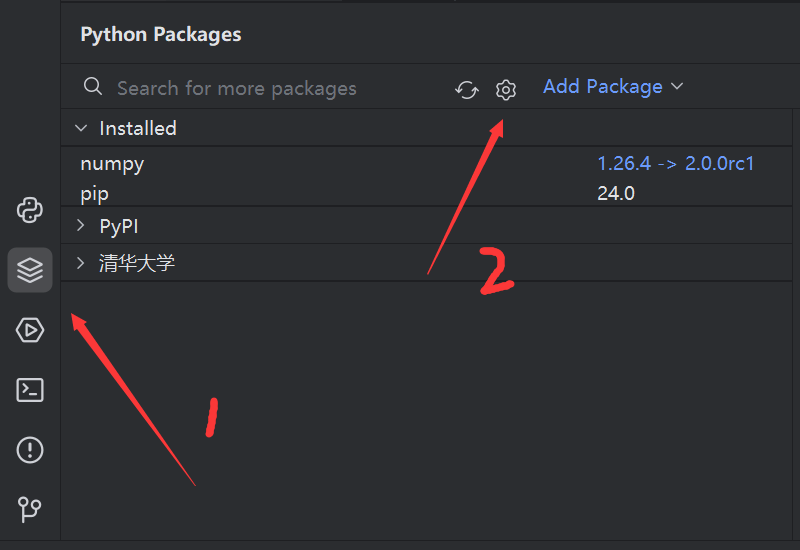
我在使用pycharm安装第三方包时出现了无法搜索到第三方包的问题,具体原因应该是因为网络原因,解决办法如下,视频可参考:https://www.bilibili.com/video/BV1SM4y1H71G/?spm_id_from=333.1007.top_right_bar_window_history.content.click
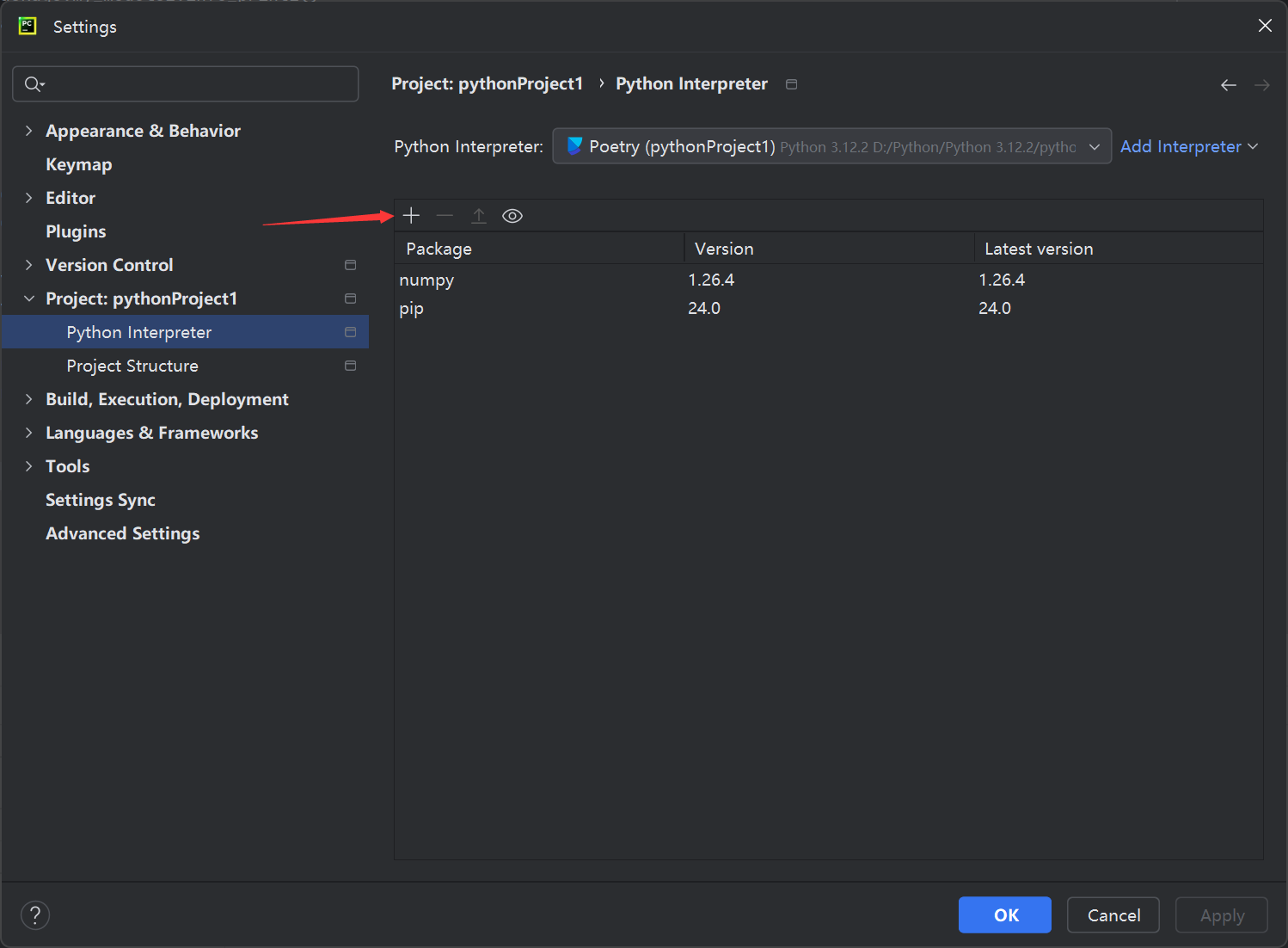
第一步:首先点击左下方Python Packages,之后点击设置(Manage repositories)
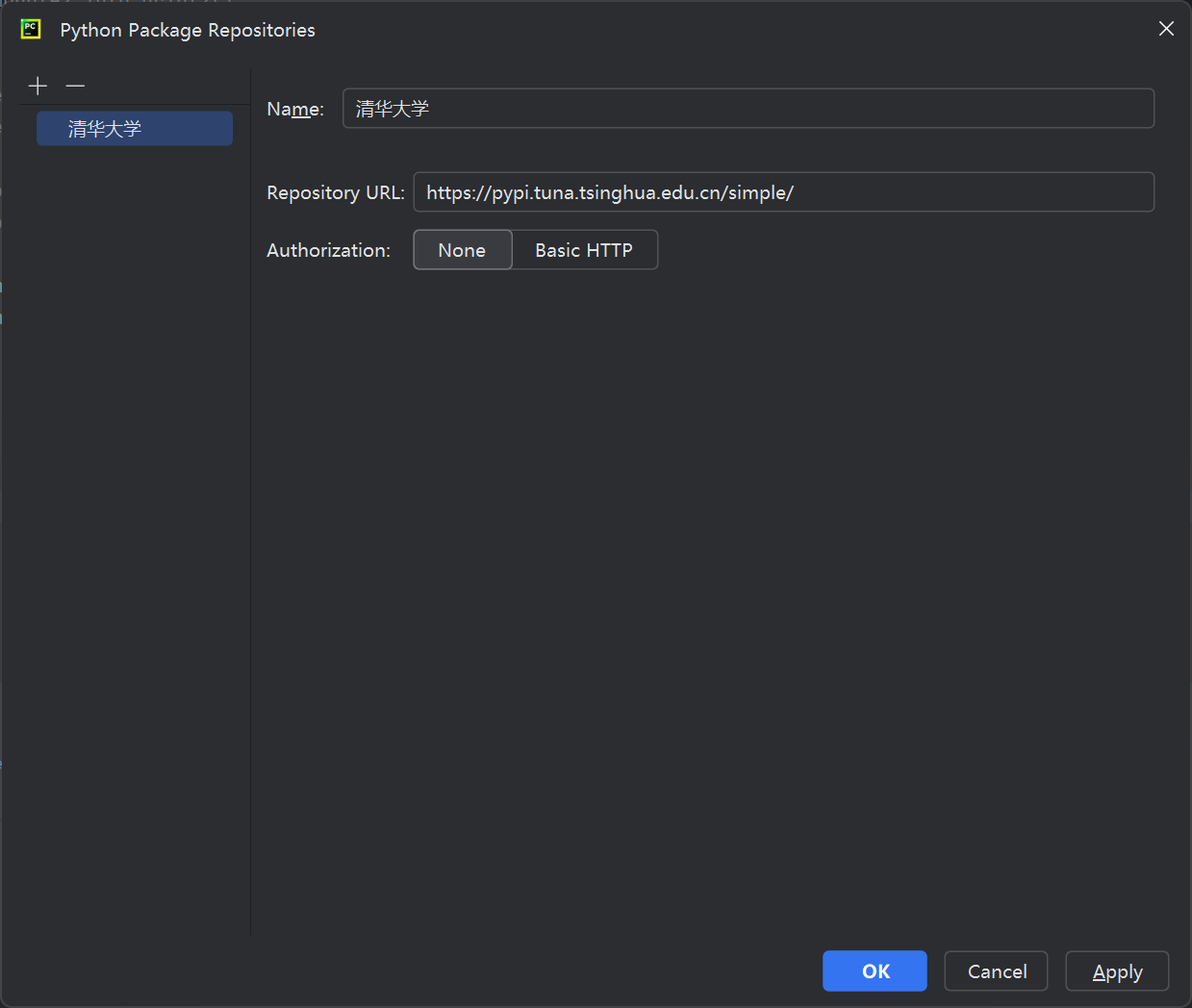
第二步:添加库
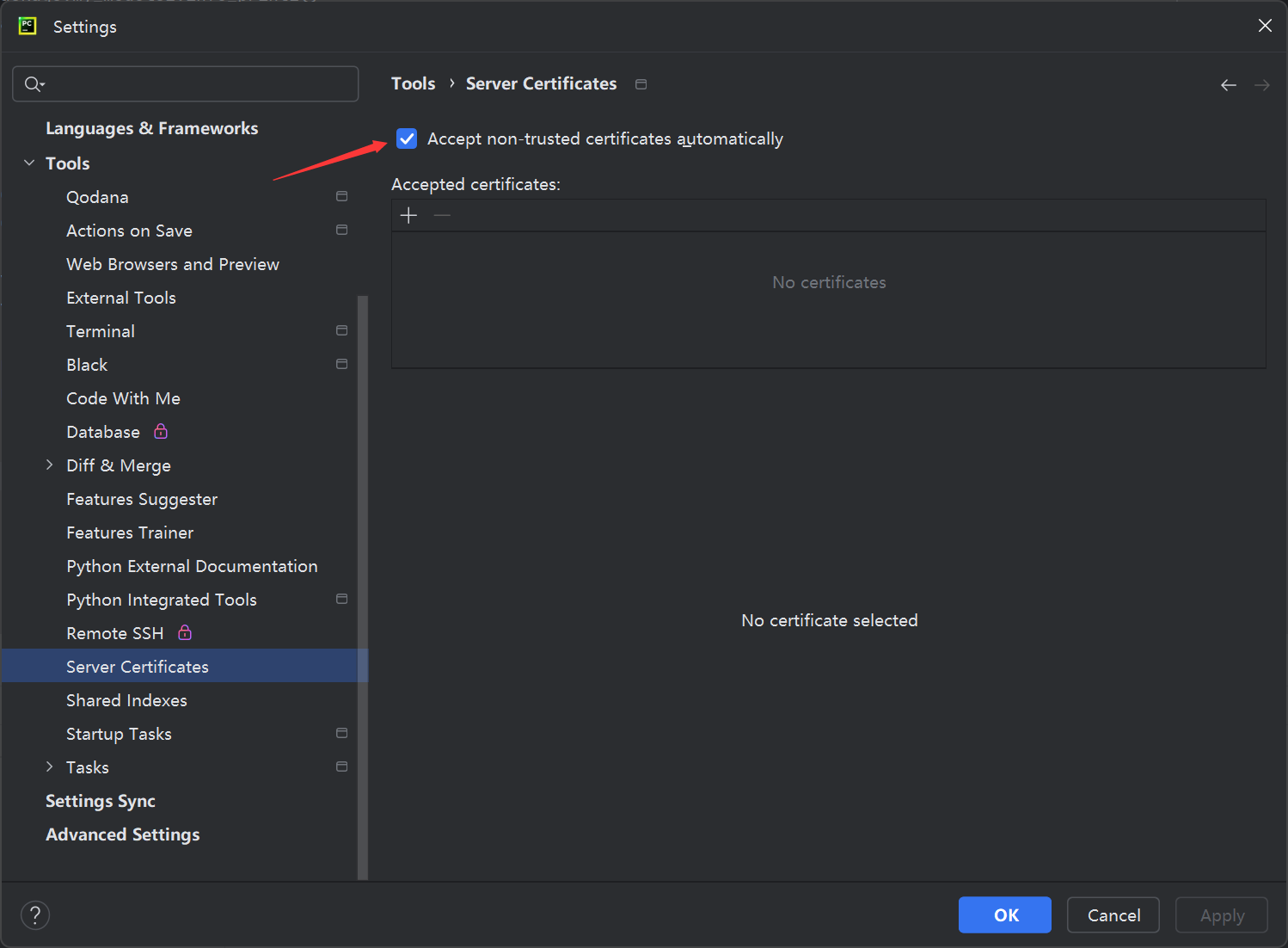
第三步:打开设置,找到Tools中的Server Certificates,选择勾选Accept non-trusted certificates automatically,即自动接收没有信任的证书
第四步:在设置中的Project->Python interpreter中点击加号添加第三方包即可
九、Python基础综合案例:图形可视化
9.1 json数据格式
JSON是一种轻量级的数据交互格式,其本质上是一个带有特定格式的字符串。我们可以按照JSON指定的格式去组织和封装数据,从而实现不同编程语言中的数据传递和交互
JSON的数据格式:
- JSON数据的格式可以是:
{“name”: “admin”, “age”: 18} # 与Python中字典的格式相同 - 也可以是:
[{“name”: “admin”, “age”: 18}, {“name”: “root”, “age”: 16}, {“name”: “张三”, “age”: 20}] # 与Python中列表嵌套字典的格式相同 - 其实JSON要求的格式与Python中字典(dict)或列表嵌套字典的格式相同
Python数据和JSON数据的相互转化:
基础语法:
1 | """ |
打印结果为:
1 | 1-data的类型是:<class 'list'>,data的内容是:[{'name': '老王', 'age': 16}, {'name': '张三', 'age': 20}] |
其中第二条输出中中文转变为了代码,这是因为在转换过程中中文的编码问题,如果需要输出为中文,可以将data = json.dumps(data)语句改为data = json.dumps(data, ensure_ascii=False),即可实现输出为中文的目的
注:如果json数据data为dict格式的字符串,那么转化为python数据后类型为:dict
9.2 pyecharts模块
pyecharts是用于python语言的有百度开源的数据可视化模块
pyecharts官网是:https://pyecharts.org
pyecharts官方画廊:https://gallery.pyecharts.org/#/README
pip安装pyecharts:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyecharts
9.3 pyecharts入门使用
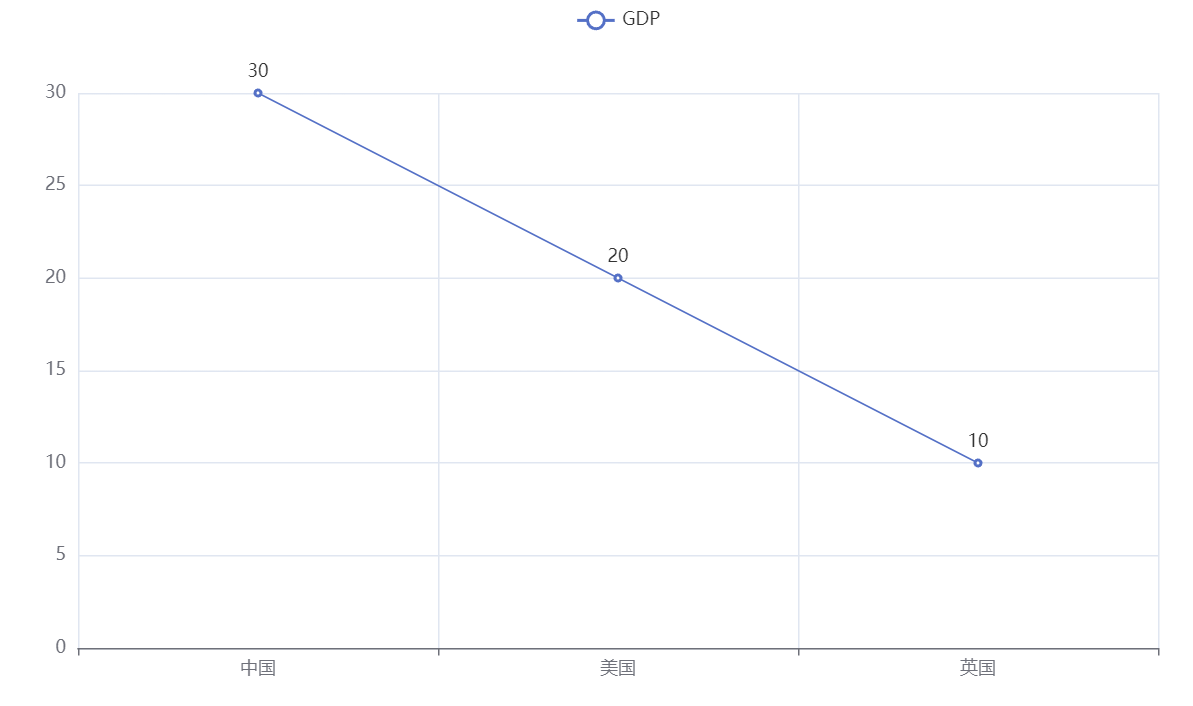
基础折线图:
示例:
1 | # pyecharts入门:基础折线图 |
得到的效果为:
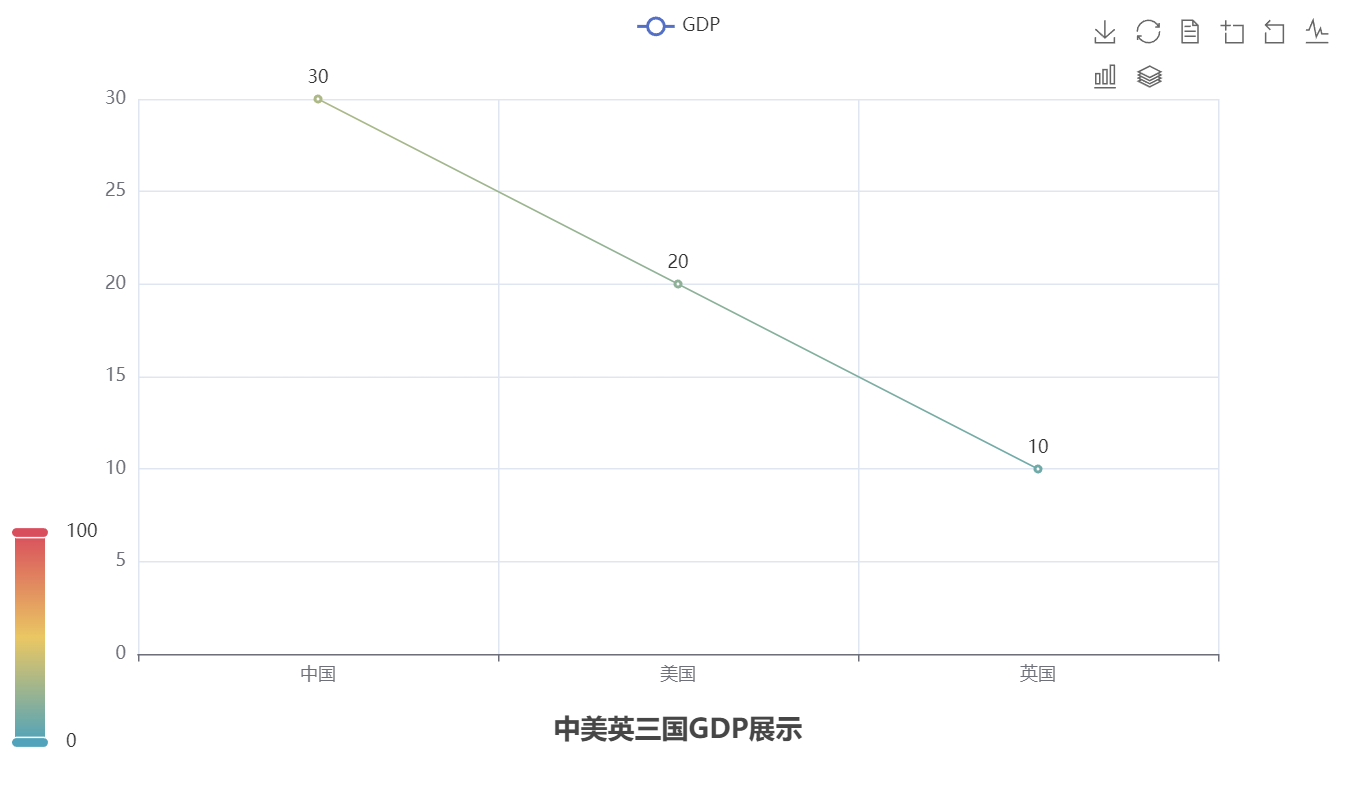
pyecharts配置选项:
全局配置选项
set_global_opts方法:
在上述案例中添加代码:
1 | # 设置全局配置项 |
最终得到的效果为:
十、Python面向对象
与Java中类似,在Python中我们也可以使用对象进行组织数据:
- 设计类(class)
- 创建对象
- 对象属性赋值
10.1 类的成员方法
类的使用语法:
class 类名称:
类的属性
类的方法
- class是关键字,表示要定义类了
- 类的属性,即定义在类中的变量(成员变量)
- 类的行为,即定义在类中的函数(成员方法)
创建类对象的语法:
对象 = 类名称()
在类中:
- 不仅可以定义属性来记录数据
- 也可以定义函数用来记录行为
- 类中定义的属性(变量)我们称为:成员变量
- 类中定义的行为(函数)我们称为:成员方法
成员方法定义语法:
def 方法名(self, 形参1, …, 形参N):
方法体
其中,self关键字是必须填写的:
- 它用来表示类对象自身的意思
- 当我们使用类对象调用方法时,self会自动被python传入
- 在方法内部,想要访问类的成员变量,必须使用self
- 传参时可以忽略它
示例:
1 | # 定义一个带有成员方法的类 |
打印结果为:
1 | 大家好,我是张三,希望大家多多关照 |
10.2 构造方法
在Python类中可以使用:__init__()方法,称之为构造方法,可以实现:
- 在创建对象(构造类)时,会自动执行
- 在创建对象(构造类)时,将传入参数自动传递给__init__方法使用
示例:
1 | # 构造方法__init__() |
打印结果为:
1 | Student类创建了一个对象 |
10.3 魔术方法
Python类内置的方法称之为魔术方法
10.3.1 __init__()构造方法
具体见10.2
10.3.2 __str__()字符串方法
功能:当类对象需要被转换为字符串时,会输出其内存地址,我们可以利用__str__()方法,控制类转换为字符串的行为
示例:
1 | # __str__方法 |
打印结果为:
1 | <__main__.Student object at 0x00000258D1D85670> |
使用__str__()方法后:
示例:
1 | class Student: |
打印结果为:
1 | Student类对象,name:张三,age:18 |
10.3.3 __lt__()小于、大于符号比较方法
功能:直接对2个对象进行比较是不可以的,但是在类中实现__lt__方法,即可同时完成:小于符号和大于符号两种比较。传入参数other(另一个对象),返回值为True或False;实际就是规定了两个对象比较时使用哪个属性进行比较
示例:
1 | # __lt__方法 |
打印结果为:
1 | True |
10.3.4 __le__()小于等于、大于等于符号比较方法
功能:__le__方法可以实现:小于等于符号和大于等于符号两种比较。传入参数other(另一个对象),返回值为True或False;实际就是规定了两个对象比较时使用哪个属性进行比较
示例:
1 | # __le__方法 |
打印结果为:
1 | True |
10.3.5 __eq__()==符号比较方法
功能:__eq__方法可以实现:等于符号的比较。传入参数other(另一个对象),返回值为True或False;实际就是规定了两个对象比较时使用哪个属性进行比较
示例:
1 | # __eq__方法 |
打印结果为:
1 | False |
10.4 封装
封装表示的是,将现实世界事物的属性、行为封装到类中,描述为:
- 成员变量
- 成员方法
从而实现程序对现实世界事物的描述
类中提供了私有成员的形式来实现对现实事物中不公开属性和行为的映射:
- 私有成员变量
- 私有成员方法
定义私有成员的方式很简单,只需要:
- 私有成员变量:变量名以__(两个下划线)开头
- 私有成员方法:方法名以__(两个下划线)开头
即可完成私有成员的设置
私有变量无法赋值,也无法获取值;私有方法无法直接被类对象使用
示例:
1 | # 含有私有变量和私有方法的类 |
打印结果为:
1 | # 发生报错,原因是'Phone' object has no attribute '__keep_single_core',即'Phone'对象没有'__keep_single_core'这个方法 |
私有成员无法被类对象使用,但是可以被其他成员使用:
示例:
1 | # 含有私有变量和私有方法的类 |
打印结果为:
1 | 让CPU以单核模式运行 |
10.5 继承
继承:从父类那里继承(复制)来成员变量和成员方法(不含私有)
继承分为单继承和多继承
单继承:
语法:
class 类名(父类名):
类内容体
示例:
1 | # 单继承演示 |
打印结果为:
1 | HM |
多继承:
语法:
class 类名(父类1, 父类2, …, 父类N):
类内容体
示例:
1 | # 多继承演示 |
打印结果为:
1 | HM |
pass关键字:
pass是站位语句,用来保证函数(方法)或类定义的完整性,表示无内容,空的意思
当新的类不需要添加新功能时,可以直接使用:
class 类名(父类1, 父类2, …, 父类N):
pass
10.6 复写父类成员和调用父类成员
复写:
子类继承父类的成员变量和成员方法后,如果对其“不满意”,那么可以进行复写,即在子类中重新定义同名的属性或方法即可
示例:
1 | # 复写 |
打印结果为:
1 | ITHEIMA |
调用父类的同名成员
一旦复写父类成员,那么类对象调用成员时,就会调用复写后的新成员,如果需要使用被复写的父类成员,需要特殊的调用方式:
- 方式1:
使用成员变量:父类名.成员变量
使用成员方法:父类名.成员方法(self) - 方式2:使用super()调用父类成员
使用成员变量:super.成员变量
使用成员方法:super.成员方法
示例:
1 | # 调用父类成员 |
打印结果为:
1 | ITHEIMA |
10.7 类型注解
10.7.1 变量的类型注解
类型注解:在代码中设计数据交互的地方,提供数据类型的注解(显式的说明)
主要功能:
- 帮助第三方IDE工具(如PyCharm)对代码进行类型判断,协助做代码提示
- 帮助开发者自身对变量进行类型注释
支持:
- 变量的类型注解
- 函数(方法)形参列表和返回值的类型注解
语法:
变量: 类型
也可以使用注释进行类型注解
语法:
# type: 类型
示例:
1 | # 变量类型注解 |
注:
- 元组类型设置类型详细注解时,需要将每一个元素都标记出来
- 字典类型设置类型详细注解时,需要两个类型,第一个是key,第二个是value
- 类型注解只是提示性的,而非决定性的。数据类型和注解类型无法队形也不会导致错误
10.7.2 函数和方法类型注解
语法:
- 对函数(方法)形参进行类型注解
def 函数方法名(形参名: 类型, 形参名: 类型, …):
pass - 对函数(方法)返回值进行类型注解
def 函数方法名(形参名: 类型, 形参名: 类型, …) -> 返回值类型:
pass
示例:
1 | # 函数方法类型注解 |
10.7.3 Union联合类型注解
Union适用于多类型变量或函数同时注解
语法:
from typing import Union # 需要先导包
Union[类型, …, 类型]
示例:
1 | # Union类型注解 |
10.8 多态
多态:指的是多种状态,即完成某个行为时,使用不同的对象会得到不同的状态。即对于同样的函数(行为),传入不同的对象,得到不同的状态
多态常作用在继承关系上,比如:
- 函数(方法)形参声明接收父类对象
- 实际传入父类的子类对象进行工作
即:
- 以父类做定义声明
- 以子类做实际工作
- 用以获得同一行为,不同状态
示例:
1 | # 多态演示 |
打印结果为:
1 | 汪汪汪 |
抽象类(接口):
父类Animal的speak方法是空实现,这样设计的含义是:
- 父类用来确定有哪些方法
- 具体的方法实现,由子类自行决定
这种写法就叫做抽象类
抽象类:含有抽象方法的类
抽象方法:方法体是空实现的(pass)称之为抽象方法





